
编者注:本文属于《解码 AI》系列栏目,该系列的目的是让技术更加简单易懂,从而解密 AI,同时向 RTX PC 用户展示全新硬件、软件、工具和加速特性。
随着生成式 AI 技术不断进步并在各行各业中得到广泛应用,在本地 PC 和工作站上运行生成式 AI 应用的重要性越来越高。本地推理可让用户享受更低的延迟,不再依赖网络,并能够更好地保护和管理自己的本地数据。
NVIDIA GeForce 和 NVIDIA RTX GPU 配备专用的 AI 硬件加速器 Tensor Core,可为在本地运行生成式 AI 提供强大动力。
NVIDIA TensorRT 软件开发者套件现已针对 Stable Video Diffusion 进行优化,该套件可在超过 1 亿台由 RTX GPU 提供支持的 Windows PC 和工作站上解锁超高性能生成式 AI。优化的 Stable Video Diffusion 1.1 Image-to-Video 模型可以在 Hugging Face 上下载。
适用于 Automatic1111 开发的热门 Stable Diffusion WebUI 的 TensorRT 扩展程序现已添加对 ControlNet 的支持。ControlNet 是一种工具,可以让用户添加其他图像作为指导,以便更好地把控并优化生成式内容的输出。
全新的 UL Procyon AI 图像生成基准测试现已支持 TensorRT 加速,内部测试表明该基准测试可以准确复现实际性能表现。与最快的非 TensorRT 加速状态相比,TensorRT 加速可在 GeForce RTX 4080 SUPER GPU 上带来 50% 的速度提升,比实力最接近的竞品快 1 倍以上。
更高效、更精准的 AI
TensorRT 使开发者能够得到完全优化的 AI 硬件体验。与在其他框架上运行应用相比,AI 性能通常会翻倍。
TensorRT 还能加速非常热门的生成式 AI 模型,例如 Stable Diffusion 和 SDXL。Stable Video Diffusion 是 Stability AI 的 image-to-video 生成式 AI 模型,在 TensorRT 的助力下,其速度可提升 40%。
此外,适用于 Stable Diffusion WebUI 的 TensorRT 扩展程序至高可将性能提升至原来的 2 倍,从而大幅加速 Stable Diffusion 工作流。
此扩展程序的最新更新使 TensorRT 的优化可扩展至 ControlNet。ControlNet 是一组 AI 模型,可借助额外控制来引导扩散模型的输出。在 TensorRT 的助力下,ControlNet 的速度可提高 40%。
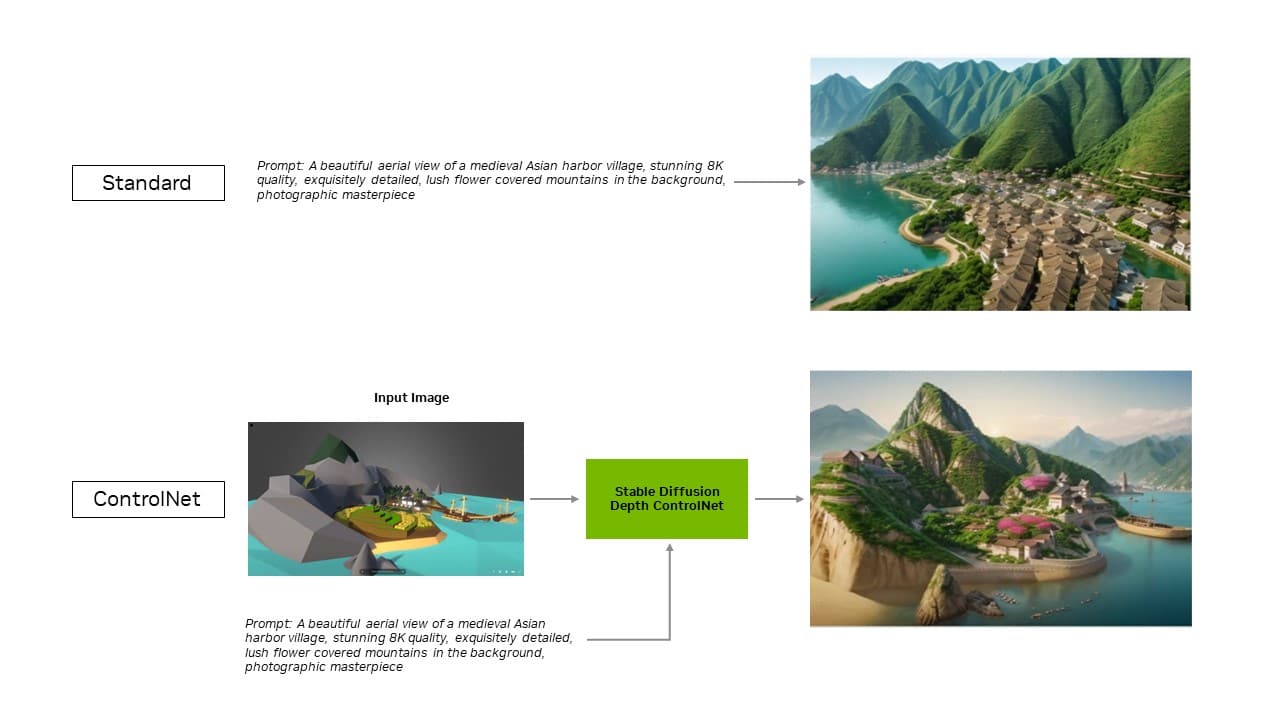
用户可以引导输出的各个方面,使其与输入图像匹配,这使他们能够加强对最终图像的把控。他们还可以同时使用多个 ControlNet 来更好地把控输出。ControlNet 可以使用深度图、边缘图、法线图或关键点检测模型等。
立即在 GitHub 上下载适用于 Stable Diffusion WebUI 的 TensorRT 扩展程序。
由 TensorRT 加速的其他热门应用
Blackmagic Design 在 DaVinci Resolve 的 18.6 更新中采用了 NVIDIA TensorRT 加速。与 Mac 相比,DaVinci Resolve 的神奇遮罩、光流 (Speed Warp) 和 Super Scale 等 AI 工具在 RTX GPU 上的运行速度提高了 50% 以上,最高可达在 Mac 上的 2.3 倍。
此外,借助 TensorRT 集成,Topaz Labs 的 Photo AI 和 Video AI 应用(例如照片降噪、锐化、照片超分辨率、视频慢动作、视频超分辨率、视频防抖等)在 RTX 上运行时,性能至高可提升 60%。
将 Tensor Core 与 TensorRT 软件结合后,本地 PC 和工作站可获得卓越的生成式 AI 性能。此外,本地运行拥有以下优势:
- 性能增强:用户将体验到更低的延迟,因为当整个模型在本地运行时,延迟不受网络质量影响。这对于游戏或视频会议等实时用例非常重要。NVIDIA RTX 提供超快的 AI 加速器,可将 AI 运算速度扩展至超过 1300 万亿次运算/秒 (TOPS)。
- 成本降低:用户无需承担与大型语言模型推理相关的云服务、云托管 API 或基础设施的成本。
- 随时访问:用户可以随时随地访问 LLM 功能,无需依赖高带宽网络连接。
- 数据隐私无虞:私人和专有数据可始终保留在用户的设备上。
针对 LLM 优化
了解 TensorRT 为深度学习带来了哪些优势,以及 NVIDIA TensorRT-LLM 为最新的 LLM 带来了哪些优势。
TensorRT-LLM 是一个可加速和优化 LLM 推理的开源库,包含对热门社区模型(Phi-2、Llama2、Gemma、Mistral 和 Code Llama 等)的开箱即用支持。无论是开发者和创作者,还是企业员工和普通用户,任何人都可以在 NVIDIA AI 游乐园中试用经 TensorRT-LLM 优化的模型。此外,通过使用 NVIDIA ChatRTX 技术演示软件,用户可以了解在 Windows PC 上本地运行的各种模型的性能。ChatRTX 基于 TensorRT-LLM 构建,可优化 RTX GPU 上模型的性能。
借助新的封装器,适用于 Windows 的 TensorRT-LLM 可与 OpenAI 的热门聊天 API 兼容,您可以选择在云端或是在本地 RTX 系统上运行 LLM 应用,并在二者之间轻松切换。
NVIDIA 正在与开源社区合作,开发适用于热门应用框架(包括 LlamaIndex 和 LangChain)的原生 TensorRT-LLM 连接器。
这些创新使开发者能够轻松将 TensorRT-LLM 与其应用结合使用,并通过 RTX 体验卓越 LLM 性能。
请订阅《解码 AI》时事通讯,我们每周都会将新鲜资讯直接投递到您的收件箱。