
在 COMPUTEX 期间举办的 NVIDIA GTC 台北大会上,全球开发者、研究人员和行业领导者齐聚一堂,深入探讨正在影响各行各业的全新突破,涵盖 AI 工厂以及将基础设施扩展到代理式 AI 和物理 AI 等主题。
NVIDIA 创始人兼首席执行官黄仁勋将于北京时间 6 月 1 日 (星期一) 上午 11 点发表主题演讲,并同步直播。
您可在此处获得所有最新动态,敬请关注博客,了解实时动态。
2026 年 6 月 4 日
NVIDIA Nemotron 3 Ultra 正式上线!Perplexity、Palantir 和 ServiceNow 作为早期采用者,正以此驱动长时间运行的 AI 智能体

NVIDIA 今日发布了 Nemotron 3 Ultra,这是一个专为长时间运行的智能体构建的开放模型,Nemotron Coalition 为其开发做出了贡献。
为长时间运行的智能体提供支持的模型,其作用远不止是生成文本。它们需要解释信息、规划后续步骤、调用工具、评估结果并进行反复迭代,以完成复杂的编码、研究和企业级任务。这就需要高效模型能够在更短的时间内探索更广的搜索空间,从而更快地提供更高准确度的结果。
Nemotron 3 Ultra 专为这种新工作负载而打造。这是一款前沿智能模型,推理速度可提升高达 5 倍,并可将复杂智能体任务的成本降低高达 30%。这使智能体能够在更短的时间内完成相同的工作,或在相同时间内完成更多工作。
Nemotron 3 Ultra 是一个具有 5,500 亿参数的混合专家模型,能够处理自主工作流中的编排和高难度的推理调用:在长时间运行的编码会话中做出架构决策、跨数百个研究来源进行合成,以及对数千个相互依赖的约束进行验证。
企业软件领导者正在使用这一全新模型构建智能体,涵盖软件开发、深度研究、客户服务和企业自动化等工作流。
- Aible 正在将 Nemotron 3 Ultra 集成到 AIbleClaw 平台中,使其客户能够为各个领域大规模构建安全且能够长时间运行的智能体。
- Glean 正在其与模型无关型的智能体 Harness 中提供 Nemotron 3 Ultra,并结合使用 Nemotron 3 Nano 微调的智能体搜索模型,从而扩展企业获取经济高效的企业级代理式 AI 的途径。
- Greptile 正在将 Nemotron 3 Ultra 集成到其代码审查平台中,以进行代码库索引,从而以更低的成本实现具有出色准确度的代码审查。
- Harvey 正在通过其平台支持 Nemotron 3 Ultra 及其后训练版本,帮助客户构建和部署 AI 驱动的法律工作流,并更好地把控其数据。
- Perplexity 正在将 Nemotron 3 Ultra 用于搜索和 Perplexity Computer,并使用其模型路由器根据任务将工作负载引导到微调的开放模型或专有模型,帮助其 AI 助手实现快速、高效、大规模地运行。
正如本周早些时候所宣布,CrowdStrike 和 Palantir 正在采用 Nemotron 3 Ultra,以驱动新型长时间运行的 AI 智能体,帮助团队在网络安全和企业环境中分析复杂数据、协调任务并简化运营。
采用该模型的公司还包括 Applied Compute、CodeRabbit、Dataiku 和 ServiceNow。
该模型基于智能体追踪进行训练,并针对智能体 Harness 进行优化,使开发者能够在保持准确度的同时选择自己偏好的框架。
支持全新的 Nemotron 模型的智能体平台和 Harness 包括 BlackBox AI、Cline、Factory AI、Hermes Agent、Kilo Code、LangChain Deep Agents、OpenClaw、OpenCode、OpenHands 和 Pi。
Nemotron 3 Ultra 可与 NVIDIA NemoClaw 蓝图协同工作,该蓝图为企业提供了安全的运行时环境、开放模型和特定领域的技能,使自主智能体能够大规模运行。
H Company、Naver、Nous 和 Prime Intellect 加入 Nemotron Coalition
H Company、NAVER Cloud、Nous Research 和 Prime Intellect 正在加入 Nemotron Coalition。这些成员将贡献数据、训练环境、评估框架和领域专业知识方面的独特优势,支持协作开发在 NVIDIA DGX Cloud 上训练的开放前沿模型,该模型将成为即将推出的 Nemotron 4 系列的基础。
通过汇聚各方力量,该联盟正在汇集全球领先的 AI 实验室和基础设施提供商,以加速开放前沿模型的开发。这种协作方式旨在拓宽前沿 AI 创新的获取渠道,同时使全球开发者和企业能够面向行业、地区和用例构建和定制模型。
全新 Nemotron 语音和安全模型
全新 Nemotron 语音识别模型今日同步上线,它为全球企业部署的语音智能体工作流带来了支持 40 种语言环境的实时流式自动语音识别 (ASR)。此外,Nemotron 3.5 Content Safety 模型 —— 一个拥有 40 亿参数的开放多模态模型 —— 可对 23 个安全类别和十几种语言的内容进行分类,并支持自定义企业策略。
开放、可定制,且可随处部署
Nemotron 模型发布时开放了权重、数据集和训练方案,为组织提供了透明度和管理权,以便为特定领域的工作流定制模型,并将其部署到其应用程序和数据所在的位置。
开发者可以使用 NVIDIA NeMo 等工具来定制、评估和优化其用例。由于 Nemotron 系列模型的开放性,组织可以在满足监管、主权或数据本地化要求的环境中部署这些模型。
这些模型目前已在 Hugging Face、魔搭社区、OpenRouter 以及 NVIDIA 官网以 NVIDIA NIM 形式提供,并通过 NVIDIA 云合作伙伴、推理平台和云服务提供商构成的广泛的生态系统供用户使用。
2026 年 6 月 2 日
“Build-a-Claw”登陆台北,带来长时运行 AI 智能体

“Build-a-Claw”体验登陆 GTC 台北,将安全、可长时间运行的智能体开发能力直接带给亚太区开发者。
“Build-a-Claw”活动彰显了开发者社区及其生态系统在智能体规模化应用方面的飞速扩展。活动中,参与者从 OpenClaw 和 Hermes Agent 起步,首先为自己的“Claw”设定个性特征,添加智能体技能,并配置其运行计划。随后,他们借助 NVIDIA NemoClaw 蓝图与 NVIDIA OpenShell 运行时,将其智能体安全、可靠地部署到专属环境中。
所谓“Claw”,即长时间运行的智能体,是一类超越“一问一答”模式的 AI 系统。与完成单次任务后即终止的传统智能体不同,Claw 具备持续性:它们会朝着既定目标持续推进,在遇到障碍时自主调整策略、汇报状态,并在开发者离线后仍能在后台持续执行任务。
这类智能体正是智能企业自动化、智能体商业和自主基础设施背后的核心引擎。而要正确构建此类智能体,仅靠精巧的架构远远不够,还需要一个安全可靠的运行时环境。
NVIDIA NemoClaw 将灵活的智能体编排框架支持 (即 Agent Harness),与 NVIDIA OpenShell 安全运行时相结合,兼容 OpenClaw、Hermes Agent 等框架,为开发者构建 Claw 智能体提供了一个经过加固的沙箱式基础。
OpenShell 负责划定运行时的安全边界:它能够隔离智能体工作负载、强制执行策略,并确保自主执行始终处于开发者及其组织可信赖的安全护栏内。NemoClaw 蓝图则进一步降低了开发门槛,为构建者提供可快速适配的模板,助力打造安全、企业就绪的智能体。
2026 年 6 月 2 日
NVIDIA Isaac GR00T 加速人形机器人从数据采集到实际部署全开发流程

制造人形机器人是一项极其复杂的工程,而进展往往取决于团队能多快地跑通整个开发闭环:采集演示数据、生成并优化数据、训练策略模型、在仿真环境中测试、验证整套软件栈,并最终在真实硬件上完成部署。然而,如今的开发者在这一工作流中,不得不应对大量孤立的工具以及繁琐的交接环节。
NVIDIA Isaac GR00T 平台的重大更新正在加速这一循环。作为一个开放的端到端人形机器人开发平台,Isaac GR00T 整合了包括 Isaac Teleop、Isaac Lab、Isaac Sim、Isaac ROS、GR00T 开放模型,以及用于实时推理与控制的 NVIDIA Jetson Thor 在内的多项技术,为开发者提供了一条从数据到部署的跨越。
Agility、波士顿动力、Dyna Robotics、Figure、FieldAI、Noble Machines、Richtech Robotics 和 Skild AI 等公司正利用 NVIDIA 人形机器人技术栈的核心组件,全面加速其机器人研发进程。
研发飞轮效应已显著加速。GR00T 模型的下载量已达 27.4 万次,而 GR00T X Embodiment Sim 数据集在 Hugging Face 上的下载量已突破 1000 万次。
Isaac GR00T 一系列更新正在提速机器人开发
现已全面开放的 Isaac Teleop 是一个开源框架,支持对仿真及实体机器人进行实时遥操作和数据采集。该框架将扩展现实 (XR) 头显、数据手套、动作追踪器等各类遥操作设备无缝连接到集成了 Isaac Lab、Isaac Sim、ROS 2 及 Isaac ROS 的工作流中,从而大幅减少重复性工作。
PICO 等头部遥操作设备制造商已原生支持 Isaac Teleop,Foxconn 和光轮智能等机器人开发商也已将其纳入自身的训练管线中。
最新的 GR00T 1.7 模型以 Cosmos Reason 2 为底层架构,并在两万小时的人类第一人称视角数据上进行了预训练。它使机器人能够执行更复杂的双手协同与精细操作任务,例如从一叠卡片中抽出一张并插入卡槽。目前处于早期访问阶段的 GR00T 1.7 已与 HuggingFace 的 LeRobot 集成,并采用商业授权许可,以便开发者在研究场景之外构建和部署衍生模型。
Techman Robot 借助 GR00T 开发平台及 GR00T 1.7 模型加速其开发流程,从而更快地将 AI 带入实际工业应用场景。
未来,Isaac GR00T 开放模型将纳入 Linux 基金会的 OpenMDW-1.1 许可协议。通过采用这种统一的、以模型为中心的授权方式,开发者在机器人工作流中构建、定制和部署 GR00T 模型资源将变得更加便捷。
Enactic 和 Nexuni 正集成 GR00T 1.7,以帮助机器人在养老院和洗衣房等难以预测的环境中进行推理、适应和作业。
此外,Isaac Lab 3.0 开发者预览版通过集成 Newton 物理引擎和支持多 GPU 扩展功能以运行大规模物理 AI 实验,进一步拓展了机器人的学习能力。开发者现在能够针对更加逼真的场景 (包括复杂的机械结构、材质和环境) 来进行策略训练。同时,Isaac Lab 与 Isaac Sim 之间统一的执行器模型有助于减少策略学习与软件在环测试之间的偏差,从而在进行全栈验证或硬件部署之前就能提前让问题暴露出来。
Flexion AG 公司利用 Isaac Lab 进行人形机器人的运动与操作策略训练,在感知类工作负载的训练上实现了高达 5 倍的加速。
现已全面开放的 Isaac Sim 6.0,为开发者提供了一个仿真环境,可以在部署前验证机器人行为并测试完整软件栈。新增的智能体技能有助于团队实现自动化仿真工作流,同时借助 Newton 的编写工具和软件在环测试功能,让开发者能够在更真实的机器人软件和物理环境中评估在 Isaac Lab 中训练的策略。此次发布还新增了超过 1,000 个可直接用于仿真的可抓取资产,以加速操作测试。
RLWRLD 借助 Isaac Sim 开发了其灵巧基础模型 RLDX-1,Robotiq 已将 Isaac Sim 集成到其触觉传感开放工作流中,以提升机器人在接触密集型任务中的操作能力。Lyte 正与 NVIDIA 合作,将 LyteVision 的真实世界多模态采集技术与 Isaac Sim、OpenUSD、SimReady 及 NVIDIA Warp 工作流相连接,将捕捉到的场景转化为 SimReady 资产和环境,用于训练机器人的感知与操作策略。
工作流的最后一环是部署,Isaac ROS 4.4 将从 Isaac Sim 和 Isaac Lab 中学习到的机器人技能,与 ROS 2 软件栈、传感器以及现实世界测试所需的加速计算能力相连接。该版本还新增了对扩展现实遥操作、操作工作流及 Jetson Thor 级硬件的支持。
开发者可以探索 NVIDIA Isaac 开放机器人开发平台,获取加速人形机器人全工作流开发所需的工具、模型和算力。这套从数据到部署的端到端验证参考工作流将于今年下半年推出。
欢迎观看 NVIDIA 创始人兼 CEO 黄仁勋在 GTC 台北大会的主题演讲,并深入了解这些物理 AI 专题会议。
请参阅有关软件产品信息的声明。
2026 年 6 月 2 日
黄仁勋走访 COMPUTEX AI 生态合作伙伴展位
NVIDIA 创始人兼 CEO 黄仁勋走访了 COMPUTEX 多家合作伙伴展位,并与宏碁董事长兼 CEO 陈俊圣、华硕董事长施崇棠、MediaTek CEO 蔡力行、广达电脑副董事长兼总经理梁次震等行业领导者会面。
与此同时,GTC 台北的活动将持续至 6 月 4 日(星期四),举办地点为台北国际会议中心。本次活动设置了 60 余场专题演讲、实操培训班、Build-a-Claw 智能体体验活动,以及多场展示前沿 AI 技术成果的现场演示。

2026 年 6 月 2 日
NVIDIA AI for Media 拓展实时 AI 版图:全面赋能直播管线与后期制作工作流

在 COMPUTEX 期间举办的 GTC 台北上,NVIDIA 发布 NVIDIA AI for Media 全新技术,正在为广播公司、流媒体平台和开发者提供用于直播制作、内容本地化、内容分析以及合成视频检测的实时基础构建模块。
据估算,媒体行业每年产出高达 1800 万小时的直播节目,拍摄 1.5 亿小时的镜头素材,并且沉淀了超过 250 EB 的专业视频存档。然而,这些海量内容中的绝大部分,往往面临着检索成本高昂、本地化速度缓慢以及难以进行规模化分析的困境。
全新的 AI for Media 功能旨在改变这一现状。这些功能既可以通过 NVIDIA RTX PRO 工作站本地部署,也能在云端运行,能够实现自动化的内容本地化流水线、可检索的存档元数据,以及 AI 辅助的直播与后期制作工作流。
此次更新包括:
- 多语言唇形同步 (LipSync):能够实时将屏幕上人物的口型与配音音频精准同步,并且现在新增了对法语、德语和西班牙语的支持。
- 增强的主动发言者检测 (Active Speaker Detection) 功能:可以自动追踪摄像头画面中的发言者,让制作团队可以轻松地实现自动化操作,精准聚焦并突出显示当前正在说话的人脸。
- 增强的 NVIDIA RTX 视频超分辨率 (NVIDIA RTX Video Super Resolution) 和 RTX 视频帧生成 (RTX Video Frame Generation) 功能:利用 AI 技术在搭载 RTX 的系统上对视频输出进行画质提升与流畅度优化。
- 一套符合 SMPTE ST 2110 标准的 NVIDIA NIM 微服务,专为基于 IP 的实时媒体管线打造,将媒体画质增强从传统的“后期制作”环节,直接带入到了“实时广播基础设施”领域。这些 NIM 微服务涵盖了主动发言者检测、视频超分辨率、唇形同步以及专业录音棚级语音增强 (Studio Voice)。其中,SMPTE ST 2110 是一套针对音频、视频和数据流传输的行业专用标准规范。
- NVIDIA 合成视频检测器是一款 NIM 微服务,它仅需短短 22 毫秒,就能以约 92% 的准确率识别出 AI 生成的视频。随着合成媒体内容正如潮水般涌入各大网络平台,这款检测器为新闻编辑室和内容平台提供了一项强有力的工具,能够在虚假或经过篡改的影像触达观众之前,及时将其标记出来。
了解更多关于 NVIDIA AI for Media 的信息,探索 NIM 微服务目录,并在 COMPUTEX 观看这些功能的实时演示。
2026 年 6 月 2 日
NVIDIA Spectrum-X 以太网硅光技术全面量产

NVIDIA Spectrum-X 以太网硅光技术现已全面量产,新一代 Spectrum-X 交换机基于光电一体封装技术 (CPO) 构建,支持 NVIDIA Vera Rubin 平台在数据中心进行横向扩展和跨区域扩展部署 AI 工厂。
该平台通过与中国台湾地区半导体和系统生态合作伙伴的深度协同工程实现量产,台积电、SPIL、TFC 和 Foxconn 分别为从硅光到系统的流程关键层提供了突出贡献:
- 台积电先进的硅光制造技术,将突破性设计转化为可投入生产的芯片。
- SPIL 的芯片级封装、组装和测试技术,将电气和光学组件以微米级精度结合在一起。
- TFC 的激光芯片经过模组封装,提供满足全年全天候运行的 AI 工作负载所需的可靠性要求。
- Foxconn 的系统组装将 Spectrum-X CPO 交换机集成到完整的机架型网络平台中。
- NVIDIA AI 工厂系统在 NVIDIA 自有和运营的 AI 工厂内进行拆箱、安装和通电,在客户发货前验证整体工作流。
Spectrum-X 以太网硅光技术是 NVIDIA 全栈协同设计的典范代表之一。与使用传统收发器的网络相比,Spectrum-X 以太网硅光技术可实现能效提升 5 倍,AI 正常运行时间提升 5 倍,部署时间快 1.3 倍。
凭借简化设计,为计算释放更多电力,NVIDIA 光电一体封装技术网络为百万 GPU AI 工厂提供了基础架构,CoreWeave、Lambda 和 Oracle Cloud Infrastructure 等公司已率先采用该技术。
阅读 Lambda 博客,观看开箱过程合作视频,了解 Lambda 如何在其 AI 工厂中拆箱和部署 NVIDIA CPO 硅光交换机。
通过大规模部署 CPO 实践,NVIDIA 消除了光互连的功率、可靠性和部署时间上限,即消除了限制 AI 集群增长的关键因素之一。
详细了解 NVIDIA 硅光技术。
2026 年 6 月 2 日
借助 NVIDIA Vera Rubin、800 VDC 以及不断壮大的全球生态系统,NVIDIA MGX 正在实现 AI 工厂的规模化扩展
在 GTC 台北,NVIDIA 与超过 80 家 NVIDIA MGX 合作伙伴,共同推进模块化、MGX 就绪的 AI 工厂基础设施建设,其范围涵盖了系统、电源和冷却等核心领域。
AI 工厂正成为智能体 AI 的核心引擎,而推理模型、长上下文推理以及 AI 之间的协同工作流,要求在生产级规模下具备更高的性能、效率和弹性。
为帮助基础设施建设者从容应对这些需求,NVIDIA 正进一步扩展其面向 AI 工厂的开放模块化参考架构——NVIDIA MGX。此次扩展包括面向 NVIDIA Vera Rubin 平台的第三代 MGX 机架设计,兼容 MGX 的 800 伏直流电 (VDC) 供电基础设施,以及日益壮大的全球生态系统。
AI 工厂的模块化基础架构
MGX 覆盖从单节点服务器、机架级系统、POD 级部署,到完整数据中心基础设施的各个层级,为制造商提供统一的基础架构,让他们能够以更少的工程投入、更快地构建加速计算系统。
该架构支持基于 Arm 和 x86 系统,采用 PCIe 等开放标准,并经过专门设计,可在当前及未来几代 GPU、CPU、DPU 和网络技术之间保持兼容。NVIDIA 还已将 MGX 机架级设计贡献给开放计算项目 (OCP),以推动其在整个数据中心行业的广泛普及和应用。
Vera Rubin 引领 MGX 迈入机架级时代
NVIDIA 同日宣布,NVIDIA Vera Rubin 已全面投产。该平台依托 MGX 架构,交付五款专为现代智能体 AI 工作负载而设计的机架级系统。
第三代 MGX 机架架构将模块化、无缆线、无软管和无风扇的计算托盘和 NVIDIA NVLink 交换机托盘相结合,具备动态功率分配、智能功率平滑技术,并采用 100% 液冷设计,专为 45 摄氏度温水进水温度工程化打造。
这些机架级的技术突破也与 NVIDIA DSX 平台高度契合。DSX 是一个面向 AI 工厂级规模的设计、仿真和运营平台。MGX 为纵向扩展机架域和解耦推理架构提供了统一的物理基础;而 DSX 的参考设计、仿真技术和运营软件,则帮助建设者在计算、网络、存储、电源、冷却和控制等全方位维度上,规划、验证并运营完整的 AI 工厂。
800 VDC 为 AI 工厂提供升级路径
随着 AI 工厂规模的不断扩大,运营商们迫切需要在保持现有物理空间和电力容量的前提下,大幅提升算力性能。
NVIDIA 800 VDC 供电架构通过减少电流转换环节,将直流电输送到更靠近机架的位置,并支持更高密度的加速计算,有效应对这一转变。
对于现有或正在建设的、基于交流电 (AC) 配电系统的设施,兼容 MGX 的 800 VDC 电源机架提供了一种实用的桥梁,可实现混合 AC 与 800 VDC 设计的无缝衔接。这一升级路径有助于保护当前在土地、电力和建筑外壳方面的既有投资,同时为 AI 工厂迎接未来的机架级计算能力做好准备。
在 NVIDIA Vera Rubin NVL72 系统中,“智能功率平滑”功能有助于缓冲由大型、同步的 AI 工作负载所产生的剧烈负载波动。随着 AI 工厂规模的不断扩大,这一能力有效应对了电力输送领域日益严峻的挑战。欲深入了解这项工作的稳电原理,请参阅这篇论文。
NVIDIA 合作伙伴将模块化设计落地为实际部署
在 COMPUTEX 期间举办的 GTC 台北大会上,NVIDIA 的合作伙伴生态系统贯穿了整个 AI 工厂的技术栈。从全球系统制造商、平台构建者到电源密度和散热合作伙伴,整个生态系统正在打造兼容 MGX 的系统,帮助客户在全球范围内大规模部署全栈式 AI 工厂解决方案。
总而言之,MGX 生态系统正在将模块化设计转化为真正落地的 AI 基础设施。这使客户能够采用开放架构,享受广泛的供应链灵活性,并获得支撑下一代 AI 工厂的全套 NVIDIA 软件栈。
2026 年 6 月 1 日
GTC 台北主题演讲收官,黄仁勋和合作伙伴打卡当地炸鸡

NVIDIA 创始人兼 CEO 黄仁勋所说的炸鸡,正是台北当地一家餐厅的招牌。星期一晚上,黄仁勋和合作伙伴们到小店就餐,吸引了不少路人驻足围观。
黄仁勋在 GTC 台北主题演讲结束后与 NVIDIA 在韩国生态系统的 80 多位合作伙伴齐聚这家餐馆,共度了一个休闲的夜晚。黄仁勋即将前往韩国,他表示非常期待在韩国与更多合作伙伴会面,与 NVIDIA 一同打造 AI 未来的企业和机构负责人深入交流。
晚餐结束后,黄仁勋向众多粉丝和媒体分发了美味的炸鸡,还特意用这家餐馆的黑色碗碟为大家签名留念。
2026 年 6 月 1 日
GTC 台北主题演讲实时更新
聆听 NVIDIA 创始人兼 CEO 黄仁勋在台北流行音乐中心主舞台带来的现场演讲。
“如今,AI 已成为利润引擎,也是 GDP 引擎” —— NVIDIA CEO 黄仁勋在 COMPUTEX 期间的 GTC 台北大会上指出
NVIDIA 创始人兼 CEO 黄仁勋抵达台北后,行程便一刻未停。
他与参与建设全球 AI 基础设施的合作伙伴逛了夜市,与使用 NVIDIA 平台的企业 CEO 们共进晚餐,并为新园区揭幕。
本周黄仁勋所到之处,都能看到生态系统的身影。今天,他们齐聚台北流行音乐中心共同迎来这场主题演讲。黄仁勋向在场的每一位致谢,从各公司 CEO,到他在夜市偶遇的水果摊主。
黄仁勋向现场及线上的观众表示:“如今,AI 已成为利润引擎,也是 GDP 引擎。”
过去三年,人们一直在追问 AI 是否真的有用。生成式 AI 给出了肯定回答;推理模型让 AI 真正具备能力;而智能体则让 AI 真正工作起来,实现自主、持续、大规模运行。
黄仁勋表示:“实用 AI 已经到来。”2026 年前几个月里,GitHub 等平台上的开发者提交量已接近此前的三倍。
黄仁勋说,这也让身处这股浪潮中心的人们比以往任何时候都更具价值。
AI 工厂成为新型基础设施
黄仁勋表示,Token 如今已成为可创造利润的营收单元,AI 企业正争相建设更多 AI 工厂,将地区对计算能力的需求推向新高。
他说:“归根到底,我们的客户是建设 AI 工厂,而并不只是要购买计算机。”
NVIDIA DSX 是 NVIDIA 面向基础设施建设者推出的 AI 工厂框架:DSX MaxLPS 可在相同功耗预算下提供多 40% 的 GPU,DSX OS 则采用开源、可扩展的架构。
黄仁勋说:“全球正在竞相建设 AI 工厂,这是人类历史上规模最大的基础设施建设。因为计算能力就是营收。”他逐一介绍了与 CoreWeave、Nebius、Nscale、NAVER Cloud、Yotta、Firmus、Indosat、GMI 等众多合作伙伴的合作。黄仁勋说:“这些公司都在同时服务区域客户与全球客户。它们都是出色的公司,带来了难得的机遇。”
黄仁勋强调,在 AI 工厂时代,计算能力就是营收,每生成一个 Token 都能创造利润。这让每瓦性能、可靠性以及系统的长生命周期,成为关键的财务杠杆,而不仅仅是技术指标:“如果你拥有十亿瓦级的电力,那么每瓦吞吐量就是你的收入。仅因为芯片更便宜就选择错误的架构,是没有意义的,因为计算能力就是营收。买得越多,赚得越多。”
NVIDIA Vera Rubin 进入全面量产
随后,黄仁勋宣布 NVIDIA Vera Rubin 正在加速进入全面量产阶段。

他表示:“我们为 Vera Rubin 打造的供应链规模是 Grace Blackwell 的两倍。我们需要所有产能来支撑当前的需求。”
由 NVIDIA Vera Rubin NVL72 系统、NVIDIA Vera CPU、NVIDIA Groq 3 LPX、NVIDIA Spectrum-6 SPX 以太网机柜以及 NVIDIA Vera BlueField-4 STX 存储所构成的五机柜平台,正由数百家 NVIDIA 供应链生态合作伙伴共同推进量产,仅台湾地区就有 150 家,这些合作伙伴分布于全球 30 个国家与地区、超过 350 家工厂。
黄仁勋表示:“NVIDIA 的生态系统贯穿了整个产业链,从主要位于台湾地区的上游供应链向下一直延伸至数据中心,并最终触达终端用户。”
本次量产覆盖范围已涵盖 AI 云、本地数据中心以及工业与企业级部署。
在舞台上,黄仁勋逐一走过整套新一代系统——Vera Rubin NVL72 系统、液冷 Vera CPU 机柜、Vera BlueField-4 STX 存储与安全系统、Groq 3 LPX 低延迟推理托盘,以及 Spectrum-X 以太网硅光网络,强调了 NVIDIA 最新硬件的设计理念,即作为一个单一的、紧密集成的 AI 工厂平台。
Spectrum-X 以太网硅光交换机是全球首款支持 200Gb/s SerDes 的、采用光电一体化封装的以太网交换机,专为百万 GPU 级 AI 工厂打造,目前已进入量产,CoreWeave、Lambda 与 Oracle Cloud Infrastructure 等成为首批生态合作伙伴与采用者。
NVIDIA Vera CPU 是一款为 AI 时代量身打造的 CPU,提供 88 个核心、1.2TB/s 的 LPDDR5X 内存带宽,以及无芯粒边界的 3.6TB/s 片上互连结构,同时每时钟周期可执行 10 条指令,带来世界级的单线程性能。
黄仁勋在解释 Vera 为何被设计为“专为智能体打造的 CPU”时说:“过去我们打造的 CPU 是为人类服务的。未来将会有数十亿个智能体,而这些智能体在使用 CPU 时几乎没有耐心。”
NVIDIA Vera BlueField-4 STX 从芯片层面处理安全问题。NVIDIA DOCA Argus 可将威胁检测时间从分钟级压缩至毫秒级;DOCA Vault 则在机柜级别为 AI 数据提供安全防护。
智能体迎来专属运行时
黄仁勋将智能体视为下一个重大的计算机遇。
他指出,这一转变将催生一个“前所未有”的全新 CPU 市场,背后驱动力是持续运行、并不断调度工具与数据的自主智能体。
黄仁勋表示:“这种应用模式,将成为每家公司未来十年采用的计算模式。”而智能体将成为它们基础设施中的基础层。
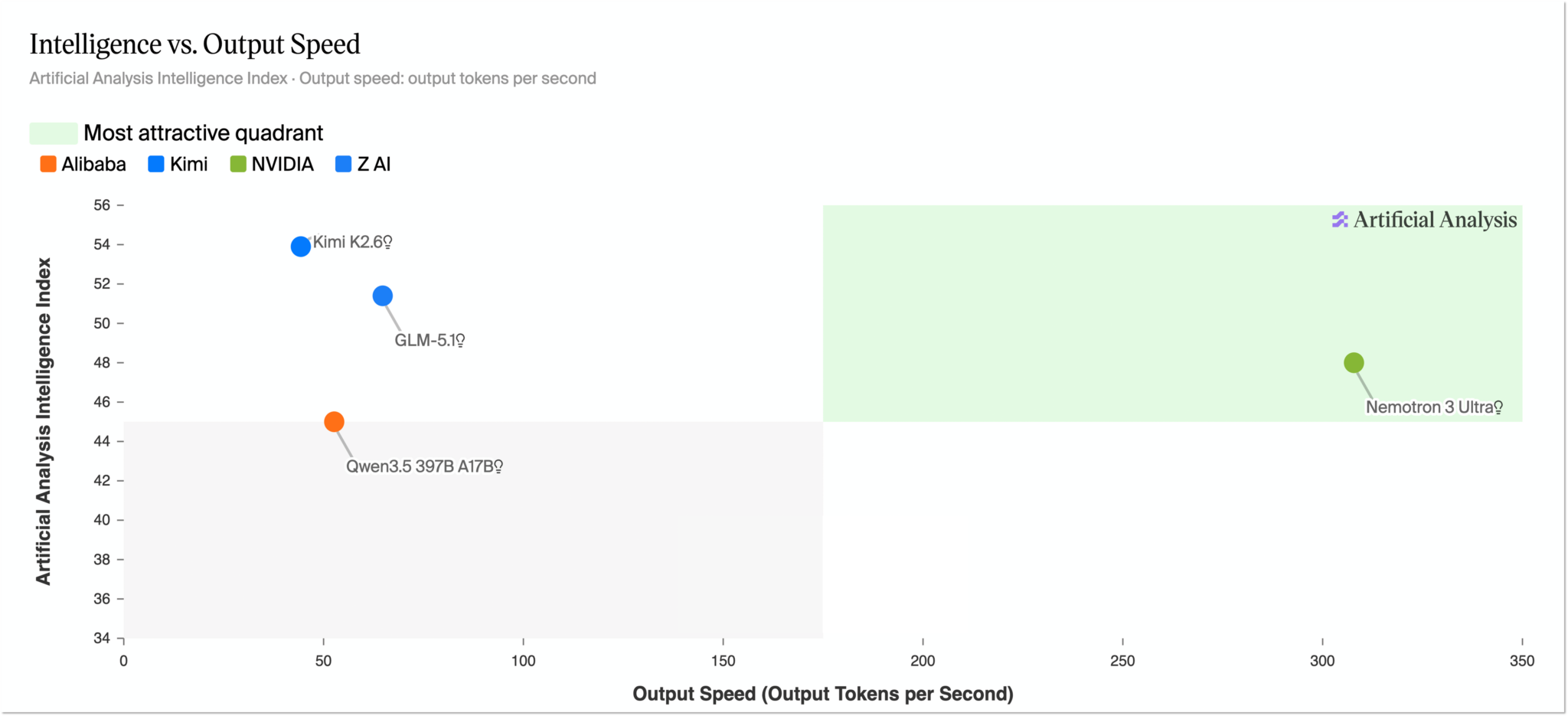
NVIDIA 正以 NVIDIA Agent Toolkit 把握这一机遇——这是一套全栈运行时,可用于在企业内部构建、部署并保障自主智能体的运行。
该工具包集成了大语言模型、智能体 Harness 以及企业级运行时,使企业能够在 NVIDIA AI 平台之上“安全地运行智能体”,并“为自身工作量构建专属智能体”。
黄仁勋将芯片设计列为他最看好的智能体应用场景之一,并重点介绍了 NVIDIA 与 Cadence 共同开发的芯片设计“超级智能体”。
通过编排寄存器传输级 (RTL) 生成、测试平台搭建、回归测试与调试等工作流,Cadence-NVIDIA 验证智能体可自动运行数百次仿真与形式化验证。
黄仁勋表示,验证周期已“加快超过 40 倍”,“过去需要几周才能完成的工作,现在几个小时即可完成”。
黄仁勋发布了 Nemotron 3 Ultra —— NVIDIA 全新的 5,500 亿参数混合专家 (MoE) 模型。这是一款更小、更聪明的前沿智能模型,推理速度最高可提升 5 倍,运行成本较当前领先的开源模型降低约 30%。
黄仁勋表示:“我们致力于为世界打造开放模型,所有人都可以使用、并在其基础上扩展、让它变得更好,并最终成为属于自己的模型。”
调用 NVIDIA CUDA-X 库 (包括 cuDF、cuOpt、AI-Q、NeMo、PhysicsNeMo 与 CUDA-Q) 的智能体技能 (skills),现已向智能体全面开放。这些经过验证的 NVIDIA 智能体技能可在 Claude Code 插件市场以及 Hermes Skills Hub 中获取,智能体可以将高性能的 CUDA 加速能力作为工具直接调用。
NVIDIA OpenShell 是面向这些自主智能体的安全运行时。它为智能体操作提供独立沙盒、集中式策略执行机制以及治理管理网关,并可运行于 Ubuntu、Windows 与 Red Hat OpenShift 等主流企业平台之上。
这不仅是一套云端基础设施。该智能体运行时还将部署到企业服务器、工作站乃至笔记本电脑之上。
重塑计算机
个人计算经过四十年发展走到了今天。NVIDIA 与微软正在为个人智能体时代重塑 PC——从数据中心一路延伸到桌面端。
黄仁勋回顾了从最初的 Windows PC 生态系统到当今智能体时代的发展历程,并指出 AI 领域正在发生与之类似的平台级转变。
他解释说,新型 PC 在传统操作系统之上叠加了大语言模型和智能体。运行时,用户可以与一位自主助手对话,这位助手能够跨越文件、应用与网页进行查看、理解并自主执行操作。
黄仁勋发布了 NVIDIA RTX Spark,让轻薄 Windows 笔记本与紧凑型桌面主机都能具备 1 Petaflop 的 AI 性能。
由 MediaTek 联合打造,运行微软 Windows 系统,NVIDIA RTX Spark 将为首个专为个人智能体打造的 PC 提供动力——始终在线、始终本地运行。
黄仁勋将 RTX Spark 形容为“我们把 33 年来积累的一切,浓缩进一颗芯片之中”。它将搭载一颗 NVIDIA Blackwell RTX GPU,拥有 6,144 个 CUDA 核心、可提供 1 Petaflop AI 性能,与一颗“和 MediaTek 联合打造,并通过 NVLink 融合在一起”的 20-Core NVIDIA Grace CPU 相连接。
他举起这颗新芯片,称其为“世界上有史以来最出色的芯片”,并强调“NVIDIA 全部软件栈都能在这颗芯片上运行”,它为新一代专为个人智能体打造的 Windows PC 提供动力。
Adobe 正针对 RTX Spark,从底层重新架构 Photoshop 与 Premiere,使其 AI 与图形性能提升一倍。
黄仁勋解释说,Adobe 已为 RTX Spark “重新设计了 Adobe Photoshop 与 Premiere 的核心架构”,并将以“两倍速度”发布这些新版本,他还补充说,这些新版本同样将方便智能体使用。
他说:“这是四十年来第一次覆盖整条产品线的 PC 重塑。”
随后,黄仁勋公布了一整条面向智能体打造的 Windows 设备产品线——涵盖笔记本、台式机和桌面级超级计算机——并向观众逐一介绍它们之间如何协同工作。

首先登场的是由 RTX Spark 驱动的笔记本电脑,黄仁勋称它是“为创作而生、为游戏而生、为智能体而生”,并可在本地运行个人 AI。
接着,他介绍了桌面端的“个人智能体”主机。这是一台紧凑型 Windows 机器,可以放在家中持续运行。黄仁勋说:“这个智能体可以全天候运行,不必担心计费。你可以下载自己的智能体,可以把它当成一只属于自己的‘龙虾’养在这里。这是你的‘Claw’,它一直在运行,没有按量计费的焦虑,并且属于你自己。”
它被设计为始终在线的个人 AI 中枢,随着 Nemotron 3 Ultra 等模型及其后续版本的持续推出,会变得越来越智能。
最后,他发布了适用于 Windows 的 NVIDIA DGX Station,这是一台桌面级 AI 超级计算机,具备数十 Petaflops 的 AI 性能与几百 GB 的内存,面向那些希望在办公桌旁就拥有一整座“AI 工厂级”计算能力的开发者。
黄仁勋表示,随着时间推移,“你家中实际上就拥有了一台 AI 超级计算机。渐渐地,对你而言,它会更像 R2-D2 和 C-3PO (《星球大战》中的角色),而不再像一台 PC。”
他认为,这些系统共同标志着一次重要转变,其意义不亚于当年手机向智能化演变的那次变革。
黄仁勋说:“这是这段旅程的开端。一条全新的产品线、一个全新的开始。”他指出,未来每一代 NVIDIA 架构都将包含台式机、笔记本与工作站三类产品,并强调“全球 PC 产业已全部加入我们,共同重塑 PC”。
AI 走入物理世界
AI 正在进入工厂、车辆、医院以及支撑这个世界运转的各类物理系统。黄仁勋将其描述为物理 AI 的前沿——在这里,智能体不再只是阅读和书写文本,而是真正在现实世界中感知、推理和行动。
NVIDIA Cosmos 3 全模态模型是一款基于混合 Transformer 架构构建的世界基础模型,能够从第一人称或第三人称等任意视角理解并模拟物理世界。
黄仁勋解释说,大语言模型训练所用的文本均出自人类视角,而机器人所需的数据则必须源自其自身视角,这让物理 AI 成为计算领域“最棘手的数据问题之一”。
Cosmos 3 通过遥操作、仿真以及第三人称视频重投影等方式进行学习,在视觉推理、世界仿真与动作生成等多项基准测试中均达到前沿水平。
Cosmos 3 同时提供了一整套丰富的开源工具包,可简化从数据生成、仿真到训练与验证的全流程。借此,开发者可以构建出按黄仁勋所说的能够“理解物理世界、对其进行推理,并将其生成出来,在闭环中进行仿真,甚至本身就成为决策”的机器人与自主系统。
黄仁勋介绍了搭载 NVIDIA Halos OS 的 NVIDIA DRIVE Hyperion 如何成为面向辅助驾驶汽车的全球性平台,主流汽车制造商与出行服务商正在不同地区采用这一技术栈。他表示,搭载 DRIVE Hyperion 的车辆将接入“约占全球出行服务 97%”的出行平台,使 NVIDIA 的辅助驾驶平台成为全球无人驾驶出租车与智能车队共同的底层基础。
NVIDIA 发布了 Alpamayo 2 Super,一款开放的自动驾驶推理模型,旨在理解复杂驾驶场景并支持端到端决策。
Alpamayo 2 搭配了用于辅助驾驶策略训练的闭环强化学习框架 AlpaGym 和能够生成逼真驾驶场景的 OmniDreams。这样开发者能够在辅助驾驶系统真正上路之前,在仿真环境中完成训练与验证。
面向机器人研究领域,NVIDIA Isaac GR00T 参考人形机器人是首款基于 NVIDIA Jetson Thor 与 NVIDIA Isaac GR00T 开发平台打造的开放式人形机器人参考设计。
全栈产品已正式交付
黄仁勋最后表示:“过去六个月,计算机行业发生了彻底变革。”他介绍了一套可不断复用的智能体计算架构:以大模型作为智能体核心,搭配 Harness 调用各类 Skills,并依托运行时环境完成运转。
这类运行时可部署在云端、本地机房、PC 或机器人中,整体计算架构完全统一。各家企业可基于 NVIDIA Agent Toolkit,选用不同 Harness 与模型进行自研优化,还能打造子智能体并对外提供租用服务。这套工具也为各方对接 AI 技术提供了便捷途径。
黄仁勋称,Vera Rubin 目前已进入全面量产阶段。它不只是一款 GPU,而是一套完整的分布式智能体处理系统。Grace Blackwell 主要用于 AI 计算,尤其是推理任务,而 Vera Rubin 则专门适配智能体的运行需求。
他表示,NVIDIA 如今已转型为基础设施企业,它不再只是单纯的显卡厂商、系统厂商,而是致力于帮助客户尽快实现收益与利润最大化的基础设施服务商。
与此同时,CPU 本身也在迎来变革。“智能体时代催生了全新的计算模式,如今 CPU 的设计目标转向智能体,而非传统的人类用户。”
NVIDIA 与微软联手推出面向智能体的全新 PC 产品线,这标志着一个全新阶段的开启。这套智能体处理模式,将广泛应用于各类设备,覆盖 PC、机器人、卫星、通信基站、工厂,部署场景包含云端、本地与边缘。
黄仁勋表示:“这种基于智能体的计算模式将在世界各地的计算机中得到推广。我们对个人计算机的认知很可能会因此发生改变。”
“我要感谢与各位的合作和深厚情谊。若没有我们共同付出的努力,就不可能有今天的成就,”黄仁勋对台下观众说道。
随着主题演讲的结束,黄仁勋播放了一段动画回顾短片:一个 AI 机器人收到了一条短信“夜市派对”。随后便动身前往台北夜市。成群结队的机器人在街头穿梭。而黄仁勋刚刚描绘的关于实用 AI 和代理式 AI 的故事,也正从数据中心融入到这座缔造了它的城市之中。
2026 年 6 月 1 日
NVIDIA DGX Spark 通过 NVIDIA NemoClaw,为本地 AI 智能体带来 2 倍加速,并简化部署与设置流程
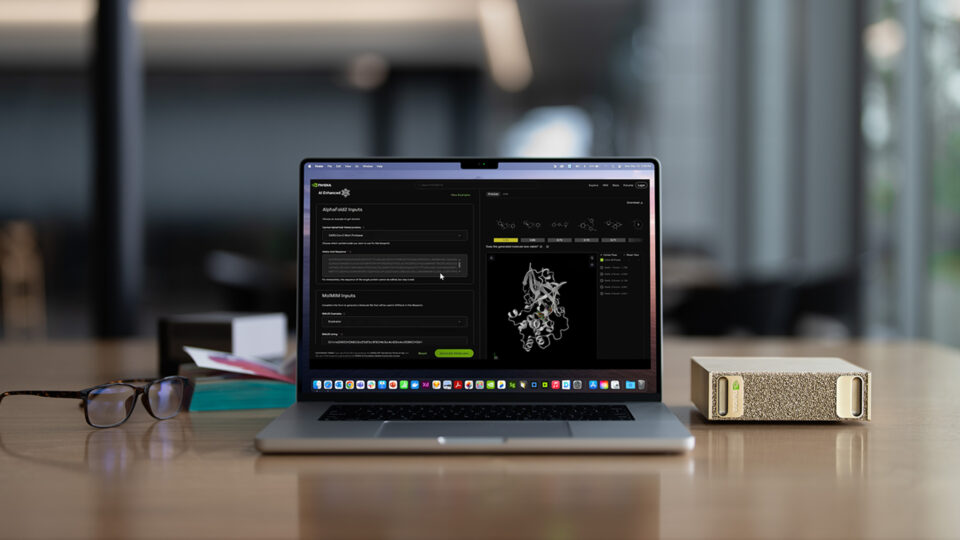
为满足日益增长的 AI 需求,加速智能体开发,NVIDIA 让开发者比以往更轻松地在 NVIDIA DGX Spark 个人 AI 超级计算机上应用代理式 AI,使其成为本地自主智能体的首选平台。
在 COMPUTEX,GTC 台北,NVIDIA 发布一项更新,让用户更容易使用智能体工作流。用户可以通过简化安装程序设置 NVIDIA NemoClaw Blueprint,在自己的系统上安全运行智能体。安装程序还会针对用户硬件设置最新的先进开放模型,为这些智能体提供高效且准确的支持。NemoClaw 安装程序在 OpenClaw 之外也支持 Hermes Agent。
NVIDIA 持续优化 DGX Spark 背后的推理软件栈,让顶级智能体模型在本地运行得更快、更高效。开发者在基于 vLLM 运行的顶级智能体模型 Qwen3.6 35B 上,推理速度提升至高可达 2.6 倍。这一表现得益于内核优化、NVFP4 量化以及多 token 预测等多项技术的协同作用。
对于需要更大算力规模的工作负载,NVIDIA Sync 桌面应用现已包含 Cluster Assistant,可引导用户将 2 到 4 台 DGX Spark 连接成多节点集群,自动配置 ConnectX-7 高带宽网络、验证用户账号并设置节点间 SSH。配置完成后,集群可以运行更大的模型,并使用集合通信库 (NCCL) 和 MPI 在多个节点之间扩展推理和微调工作负载。
结合这些进展,最新 DGX Spark playbook 的 NemoClaw 相关指南可帮助开发者更快地设置并进入智能体工作流。指南包括最新的 NemoClaw Setup 和 Example NemoClaw Agents。
自 OpenClaw、Hermes Agent 和 NVIDIA NemoClaw 推出以来,DGX Spark 的需求持续增长。
NVIDIA 正在代理式 AI 生态中开展广泛合作,让本地自主智能体更易于使用。这包括与开放模型提供商合作推进可直接调用工具的模型;优化 llama.cpp、vLLM 和 Ollama 等广泛使用的推理框架;并与宏碁、华硕、戴尔、技嘉、惠普、联想和微星等合作伙伴合作,扩大基于 NVIDIA Blackwell 系统的销售渠道。
这些努力优化了从模型、框架到硬件和工作流的完整软件栈,让开发者能在 DGX Spark 以及由合作伙伴推出的 NVIDIA GB10 系统上更快地构建智能体应用。
开发者可访问 GeForce.cn 探索 DGX Spark、获取资源,并参加实操课程,即刻开始在本地构建自主智能体。
扫描二维码参与 NVIDIA DGX Spark Playbook 调查问卷,赢取 NVIDIA 纪念品。

2026 年 6 月 1 日
全站加速:全球开发者全面启用 NVIDIA DGX Station

搭载 NVIDIA Grace Blackwell Ultra 桌面超级芯片的 NVIDIA DGX Station 台式超级计算机现已正式推出—— 由华硕、技嘉、微星和 Supermicro 提供的系统正于 COMPUTEX 展台展出。
研究人员和开发者正在使用这些系统不断拓宽 AI 的边界。DGX Station 配备 748GB 的一致性内存和高达 20 PetaFLOPS 的 FP4 AI 性能,使 AI 团队能够在桌边环境中迭代参数量高达 1 万亿的前沿规模模型,运行多模态工作流,并部署可长时间运行的自主智能体。
Andrej Karpathy 是首批获得该系统的科学家之一,他在神经网络和语言模型领域的研究成果影响了整整一代从业者对 AI 的认知。
当今对技术要求最严苛的 AI 内容创作者之一 Matt Berman,也已经通过与戴尔科技的合作获得了该系统,并正在用其进行开发。
DGX Station 为在本地开发和运行强大的始终在线的自主智能体奠定了基础。NVIDIA OpenShell 运行时提供安全和隐私管理,用于开发、部署和管理 AI 系统。凭借独立的智能体沙盒、策略执行引擎和策略管理网关,OpenShell 提供了一个安全的环境,使智能体能够在其中运行数小时或数天,以完成复杂任务。
适用于各行各业的桌边型超级计算
这些系统正在各行各业发挥着重要作用。
在医疗领域,DGX Station 结合 NVIDIA BioNeMo 平台,展示了实时药物研发和生物分子 AI 工作流:蛋白质生成、结构预测和分子设计管线在单一系统上进行本地运行。
在体育领域,SūmerSports 在 NVIDIA DGX Station 上测试了其 AI 驱动的橄榄球聊天机器人 SūmerBrain,与使用 NVIDIA Grace Hopper 超级芯片相比,其平均响应时间缩短了约 1.6 倍,复杂查询延迟降低了近 2 倍。
在能源领域,EPRI 对 NVIDIA Grace Blackwell Ultra 配置进行了全面评估,涵盖支持电网运营的 AI 天气预测和降尺度用例。
在建筑、工程和施工领域,Jacobs 部署了 DGX Station 来运行跨多模态融合训练和视觉语言模型推理的完整深度学习实验,并由 DGX Spark 负责处理整个管线的开发和验证。
在制造领域,是德科技正使用 DGX Station 为其自动化软件测试工具 Eggplant 提供支持,从而实现大语言模型的基准测试。DGX Station 帮助是德科技大规模评估模型性能,并更好地了解功能强大的开源 LLM 的能力。
在汽车领域,NVIDIA Alpamayo 开放模型与 DGX Station 将 NVIDIA 的辅助驾驶研究堆栈引入到桌面端,并在由 NVIDIA Cosmos 世界基础模型生成的虚拟环境中实现了闭环驾驶场景。
此外,NVIDIA 目前正在将 DGX Station 引入 Windows。适用于 Windows 的 NVIDIA DGX Station 是性能卓越的台式 AI 超级计算机,旨在构建、运行和连接始终在线的 AI 智能体到 Windows 应用和工作流,能够在本地运行高达 1 万亿参数的前沿 AI 模型。
华硕、戴尔科技、技嘉、惠普、微星和 Supermicro 正在构建基于搭载 Grace Blackwell Ultra 的 NVIDIA DGX Station 系统,合作伙伴将于本月开始发货。
2026 年 5 月 29 日
重塑计算机行业的必由之路

NVIDIA 创始人兼 CEO 黄仁勋与 MGX 生态系伙伴齐聚一堂,共同庆祝这些公司在打造 AI 工厂和推动产业创新方面的重要贡献。
黄仁勋表示:“我们与所有合作伙伴协同已久,为迎接这个 AI 无处不在、且不再仅仅局限于计算机的全新世界做好了充分准备。如今,AI 已将计算机行业彻底重塑为基础设施产业。每家企业都将获得 AI 的赋能,每个国家都将拥有支撑其社会运转、产业发展与企业成长的 AI 能力。”
谈到所有合作伙伴为之做出的贡献时,黄仁勋明确表示,没有这些合作伙伴的支持,NVIDIA 就无法实现这些愿景。
黄仁勋表示:“我要感谢各位的支持,没有你们,我做不到这一切。我们正在共同重塑计算机行业。更重要的是,我们正在共同重塑整个世界。”
2026 年 5 月 28 日
AI 产业最紧密的伙伴关系

台北 Brick Kiln 餐厅这场别具一格的聚会,用“气场相投”来形容再贴切不过。NVIDIA 创始人兼 CEO 黄仁勋在此招待了超过 30 位 CEO。
黄仁勋向在座的长期合作伙伴举杯致意,并感谢大家一路以来的通力协作与辛勤付出。出席晚宴的嘉宾均为当地供应链企业的负责人,正是这些企业促进了科技行业的变革,切实加速了计算与 AI 的发展。
黄仁勋逐桌与 CEO 和领导者们亲切交谈。整场晚宴氛围轻松随性,欢声笑语不断,展现了彼此间深厚的合作情谊。
晚宴尾声,黄仁勋还向媒体,以及站在餐厅外街道专程赶来的群众分发了伴手礼。

2026 年 5 月 28 日
NVIDIA 与广达电脑 —— 加速打造 AI 基础设施

星期三晚间,黄仁勋携家人与广达电脑团队共进晚餐,出席人员包括广达电脑公司创始人暨董事长林百里、副董事长兼总经理梁次震,庆祝双方多年来在 AI 基础设施制造领域的合作。
在现场媒体记者的提问下,黄仁勋透露了 2026 年接下来的产品规划:“今年下半年我们会非常忙碌,将推出 Grace Blackwell、Vera Rubin,还有一款尚未对外公布的惊喜新品。”
敬请期待。再过几天,GTC 台北大会将正式开幕,届时将全面展示更多细节以及 NVIDIA 在台湾地区快速发展的生态系统的成果。
谈及 GTC 重返台北,黄仁勋表示:“这些年这里的生态系统发展迅猛,我们认为在这里庆祝我们的生态系统再合适不过。很多年前我们只有 10 家合作伙伴,五年前大概有了 50 家,现在我们已经拥有了 150 家合作伙伴,所以庆祝我们的生态系统是很有意义的。”

2026 年 5 月 27 日
Constellation —— NVIDIA 在台北扩建园区

现代天文学公认有 88 个正式星座 —— 今日在台北市,黄仁勋向现场包括员工、当地领导人及其家人在内的观众揭晓了 NVIDIA Constellation。
台北市市长蒋万安出席了在新园区现场举行的庆祝活动,与黄仁勋握手并向他授予“城市之钥”。此外,他还赠送了黄仁勋一幅亲笔书写的传统书法卷轴。
“全世界都在见证 NVIDIA 如何定义 AI 的未来,” 蒋万安对在场人士说道。
黄仁勋在现场不仅回答了观众的提问,还用普通话与大家互动开玩笑,并向近期结婚的员工赠送了签名香槟酒瓶。当天的热门话题是专门售卖公司周边的 NVIDIA 周边商店。

“应大家的需求,周边商店将向公众开放,” 黄仁勋的话音刚落,现场便响起掌声。
新园区位于台北市北部的北投士林科技园区,占地面积近 4 公顷,设计可容纳约 4000 名员工。其建筑设计延续了 NVIDIA 位于圣克拉拉总部的标志性风格。

园区投入运营后,将成为亚太地区规模最大的 AI 研发中心之一。
黄仁勋在演讲中指出,当前代理式 AI 浪潮为 NVIDIA 及当地生态系统带来了巨大的增长机遇。展望未来,下一阶段的发展方向将是物理 AI。
黄仁勋对在场观众表示,“物理 AI 将变革制造业。NVIDIA 所有能够推进制造业变革的技术,都将惠及我们当地的合作伙伴。”
2026 年 5 月 26 日
NVIDIA 与台积电:长达数十年的合作

星期二晚间,台积电董事长暨总裁魏哲家博士与黄仁勋及 NVIDIA 团队共进晚餐,席间美食和欢声笑语相伴。NVIDIA 与台积电长期合作,不断突破先进半导体芯片的性能极限。如今,这一长达数十年的合作关系正在构建支撑全球 AI 工厂的基础设施。
晚餐期间,两位首席执行官两次离席,为餐厅外聚集的人群分发食物和饮品,并为大家签名。距离 COMPUTEX 期间的 NVIDIA 台北 GTC 大会只剩几天时间,精彩已经提前上演。

2026 年 5 月 25 日
与家人共进晚餐
黄仁勋与父母享用家宴,席间还特意将炸馒头分享给在场的媒体记者。


2026 年 5 月 24 日
来到台北不去饶河街夜市就不算完整。抹茶和芒果刨冰在这个温暖的夜晚来得恰到好处。

2026 年 5 月 23 日
NVIDIA 台北 GTC 大会进入倒计时
NVIDIA 创始人兼 CEO 黄仁勋在 GTC 台北大会开幕前,与行业领导者、政府官员、开发者及 NVIDIA 员工会面。

黄仁勋在抵达台北几小时后,便亲临 Meet-a-Claw 现场。NVIDIA 与当地开发者社区安排了演示、技术讲座和交流活动,参与者有机会体验自主智能体和 OpenClaw 技术。
OpenClaw 是开源项目,所有人都可以使用它并构建自己的 AI 智能体。黄仁勋介绍了由 NVIDIA OpenShell 提供安全保障的 OpenClaw 智能体的多种应用场景,涵盖软件编程、市场营销和内容创作等各个领域。
黄仁勋表示:“它已经成为一款非常强大的助手。实用 AI 时代已经到来。本次活动的目的就是向大家展示开源智能体的能力,你们可以去创造属于自己的智能体了。”
黄仁勋回答了在场媒体的几个问题,其中包括 NVIDIA 在建台北办公室的进展情况。黄仁勋微笑着给出了回应。
他说:“我打算本周向大家公布办公室的最新进展。这本来可能是个秘密,或许我会展示一下大楼的设计效果图。”
好吧,既然已经说出来了,这就不再是秘密了。敬请关注本博客,获取 COMPUTEX 期间的 NVIDIA 台北 GTC 大会开幕前的精彩动态。

星期六下午,NVIDIA 创始人兼 CEO 黄仁勋抵达台北,现场气氛热烈,大批记者到场等候。这为接下来几周的活动奠定了基调,也正式启动了 COMPUTEX 期间 NVIDIA 台北 GTC 大会的倒计时。
黄仁勋在现场接受媒体采访时表示:“Vera Rubin 可能是这里历史上规模最大的一次产品发布。每个 Vera Rubin 系统由近 200 万个零部件组成,有 150 家不同的生态合作伙伴参与了其制造过程。”
2026 年 5 月 21 日
NVIDIA 凭借 AI 工厂、机器人和智能汽车领域的创新荣获 COMPUTEX 2026 最佳选择奖
在亚洲领先的技术和电脑贸易展览会上,NVIDIA Vera Rubin NVL72、NVIDIA Jetson Thor 和 NVIDIA Alpamayo 在四个类别中荣获奖项。

在今年的 COMPUTEX“Best Choice Awards” (BCA,最佳选择奖) 上,NVIDIA 凭借在 AI 计算、集成电路和智能汽车开发上的创新荣获了多项荣誉。
其中,NVIDIA Vera Rubin NVL72 机架级 AI 超级计算机荣获金奖和可持续技术特别奖;NVIDIA Jetson Thor 边缘 AI 和机器人平台荣获金奖;用于智能汽车开发的 NVIDIA Alpamayo 开放平台荣获车辆技术和智能座舱类别奖。
最佳选择奖从参赛作品的功能、创新性和市场潜力三个维度进行了评估,并在本届计算机与技术行业盛会上进行了展示。
NVIDIA 创始人兼首席执行官黄仁勋将于北京时间 6 月 1 日 (星期一) 上午 11 点发表 COMPUTEX 主题演讲。
NVIDIA Vera Rubin NVL72 荣获 COMPUTEX 大奖
Vera Rubin NVL72 荣获金奖和可持续技术特别奖。Vera Rubin NVL72 连接了 36 个 NVIDIA Vera CPU 和 72 个 NVIDIA Rubin GPU,通过第六代 NVIDIA NVLink 交换机实现纵向扩展。该平台同时配备 ConnectX-9 SuperNIC 和 Spectrum-X 以太网硅光一体封装光学交换机用于横向扩展和跨区域扩展,以及 BlueField-4 DPU 用于加速存储和安全领域的数据处理。
Vera Rubin NVL72 可将每瓦特推理吞吐量最高可提高 10 倍,每 Token 成本仅为原平台的十分之一。与 NVIDIA Groq 3 LPX 搭配时,Vera Rubin NVL72 可将万亿参数模型的每瓦特吞吐量提升高达 35 倍。
它专为代理式 AI、推理和长上下文工作负载而设计,使 AI 工厂能够通过安全、持续可用的部署在机架内和整个数据中心扩展智能。
Vera Rubin NVL72 为可扩展性、可靠性和可持续的 AI 基础设施设定了标准。其无线缆、无软管、无风扇的模块化托盘设计将每个计算托盘的组装时间从 2 小时缩短到 5 分钟。
该系统的电源架可提供 6 倍以上的板载能源存储,以实现智能电源平滑,保护机架和更广泛的电网免受负载急剧波动的影响。此外,其全液冷架构可在 45 摄氏度下运行,这意味着它可以无缝集成到现有的液冷数据中心,并支持环境空气干冷器的设计,将原本用于冷却的电力转向 Token 生成。
更多 NVIDIA 技术荣获最佳选择奖
NVIDIA Jetson Thor 荣获金奖,它是专为物理 AI 和自主机器人打造的强大的边缘 AI 计算平台。基于 NVIDIA Blackwell GPU 架构,NVIDIA Jetson Thor 可提供高达 2070 FP4 TFLOPS 的 AI 性能,与上一代 NVIDIA Jetson Orin 相比,计算性能是之前的 7.5 倍,能效是之前的 3.5 倍,功率可配置在 40 W 到 130 W 之间。
Jetson Thor 已经在数百个应用中投入使用,旨在将生成式 AI 引入智能机器人、工业系统、医疗设备和自主机器,同时更大限度地提高运行时性能和内存优化。
此外,NVIDIA Alpamayo 凭借基于推理的开放式智能汽车开发这一开创性技术,荣获车辆技术和智能座舱类别奖。Alpamayo 旨在帮助开发者应对罕见、复杂的长尾驾驶场景,例如解读行人模糊的手势、在红绿灯和道路标记相互矛盾时确定通行权,以及安全地超过部分停在前方车道上的应急车辆,这些都超出了常规训练经验的覆盖范畴。
Alpamayo 开放平台包括 Alpamayo 1.5 和 Alpamayo 1,两款 100 亿参数思维链视觉-语言-动作推理模型 (Reasoning VLA),面向辅助驾驶研究;AlpaSim 面向高保真辅助驾驶开发、开源的端到端仿真框架;以及 NVIDIA 物理 AI 开放数据集,其中包括超过 1700 小时的驾驶数据,覆盖广泛的地理区域和环境条件。
如需详细了解 NVIDIA 的最新创新成果,请访问 NVIDIA GTC 台北大会。