案例简介
- 本案例中通过NVIDIA T4 GPU,通过Ronda平台调用Triton以及TensorRT, 整体提升开发和推理效能, 帮助腾讯PCG的多个服务整体效能提升2倍,吞吐量最大提升6倍,同时降低了40%的延时。本案例主要应用到 NVIDIA T4 GPU、TensorRT和Triton。
- 本案例主要应用到 NVIDIA T4 GPU、TensorRT和Triton。
Case Introduction
- In this case, NVIDIA T4 GPU is used to call Triton and TensorRT through the Ronda platform, which improves the overall development and inference performance, helps Tencent PCG’s multiple services to increase the overall performance by 2 times, the throughput by a maximum of 6 times, and reduce the 40% delay.
- This case is mainly applied to NVIDIA T4 GPU, TensorRT and Triton.
客户简介及应用背景
腾讯平台与内容事业群(简称 腾讯PCG)负责公司互联网平台和内容文化生态融合发展,整合QQ、QQ空间等社交平台,和应用宝、浏览器等流量平台,以及新闻资讯、视频、体育、直播、动漫、影业等内容业务,推动IP跨平台、多形态发展,为更多用户创造海量的优质数字内容体验。
腾讯PCG机器学习平台部旨在构建和持续优化符合PCG技术中台战略的机器学习平台和系统,提升PCG机器学习技术应用效率和价值。建设业务领先的模型训练系统和算法框架;提供涵盖数据标注、模型训练、评测、上线的全流程平台服务,实现高效率迭代;在内容理解和处理领域,输出业界领先的元能力和智能策略库。机器学习平台部正服务于PCG所有业务产品。
客户挑战
- 业务繁多,场景复杂
- 业务开发语言包括C++/Python
- 模型格式繁多,包括ONNX、Pytorch、TensorFlow、TensorRT等
- 模型预处理涉及图片下载等网络io
- 多模型融合流程比教复杂,涉及循环调用
- 支持异构推理
- 模型推理结果异常时,难以方便地调试定位问题
- 需要与公司内现有协议/框架/平台进行融合
应用方案
基于以上挑战,腾讯PCG选择了采用NVIDIA 的Triton推理服务器,以解决新场景下模型推理引擎面临的挑战,在提升用户研效的同时,大幅降低了服务成本。
NVIDIA Triton 是一款开源软件,对于所有推理模式都可以简化模型在任一框架中以及任何 GPU 或 CPU 上的运行方式,从而在生产环境中使用 AI。Triton 支持多模型ensemble,以及 TensorFlow、PyTorch、ONNX 等多种深度学习模型框架,可以很好的支持多模型联合推理的场景,构建起视频、图片、语音、文本整个推理服务过程,大大降低多个模型服务的开发和维护成本。
基于C++ 的基础架构、Dynamic-batch、以及对 TensorRT 的支持,同时配合 T4 的 GPU,将整体推理服务的吞吐能力最大提升 6 倍,延迟最大降低 40%,既满足了业务的低延时需求,成本也降低了20%-66%。
通过将Triton编译为动态链接库,可以方便地链入公司内部框架,对接公司的平台治理体系。符合C语言规范的API也极大降低了用户的接入成本。
借助Python Backend和Custom Backend,用户可以自由选择使用C++/Python语言进行二次开发。
Triton的Tracing能力可以方便地捕捉执行过程中的数据流状态。结合Metrics 和 Perf Analysis等组件,可以快速定位开发调试,甚至是线上问题,对于开发和定位问题的效率有很大提升。
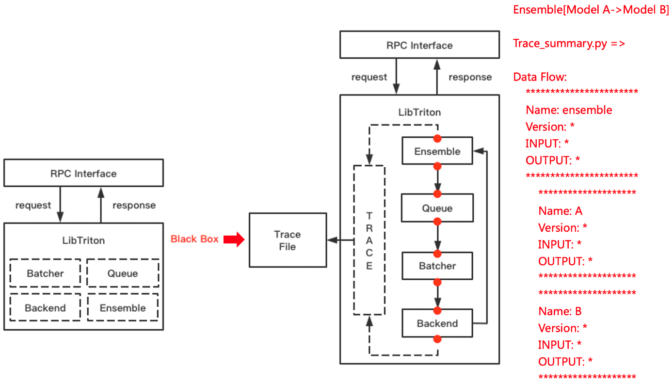
NVIDIA DALI 是 GPU 加速的数据增强和图像加载库。DALI Backend可以用于替换掉原来的图片解码、resize等操作。FIL Backend也可以替代Python XGBoost模型推理,进一步提升服务端推理性能。
方案效果及影响
借助NVIDIA Triton 推理框架,配合 DALI/FIL/Python 等Backend,以及 TensorRT,整体推理服务的吞吐能力最大提升 6 倍,延迟最大降低 40%。帮助腾讯PCG各业务场景中,以更低的成本构建了高性能的推理服务,同时更低的延迟降低了整条系统链路的响应时间,优化了用户体验。