
简介
- 本案例中,vivo AI 团队与 NVIDIA 团队合作,通过算子优化,提升 vivo 文本预训练大模型的训练速度。在实际应用中,训练提速 60%,满足了下游业务应用对模型训练速度的要求。
- 本案例主要做的优化包括:通过 NVIDIA Nsight Systems (nsys) 性能分析工具进行性能瓶颈分析,并在此基础上,针对 gather、dropout、softmax、scale、layernorm 等算子进行优化。
客户简介及应用背景
vivo 是一家以设计驱动创造伟大产品,以智能终端和智慧服务为核心的科技公司。自 2017 年开始,vivo 不断地思考着如何通过 AI 技术能力,为全球超过 4 亿的用户提供更好的智能服务。基于此愿景,vivo 打造了针对消费互联网场景的 1001 个 AI 便利。其中,vivo AI 团队研发了面向自然语言理解任务的文本预训练模型 3MP-Text。在中文语言理解测评基准 CLUE 榜单上,3MP-Text 1 亿参数模型效果排名同规模第一,7 亿参数模型排名总榜第十(不包括人类);在 vivo 内部的多个应用场景如内容理解、舆情分析、语音助手上测试,3MP-Text 1 亿模型效果明显优于同规模开源模型,展现出优秀的中文语言理解能力,具有良好的应用价值。
*如果您有任何疑问或需要使用此图片,请联系 vivo
客户挑战
为提升预训练模型的效果,往往需要对模型的结构做一定修改,(比如改变位置编码的实现方式,改变模型的宽度和深度等)而这些修改,可能造成模型训练速度的下降。
3MP-Text 模型,采用 Deberta V2[2]的模型结构,该结构使用相对位置编码,相对于绝对位置编码,效果更好,但其相对位置编码的实现过程,增加了模型在注意力机制部分的计算量,从而降低了模型的训练速度。如图 1 所示,在 NVIDIA GPU 单卡测试中,含有相对位置编码的注意力机制的计算耗时占了单次迭代耗时的 71.5%。
另一方面,已有的研究和实践验证显示,相同参数规模下,减小模型隐层维度,增加模型层数,能提升效果(效果对比见图 2),因此,3MP-Text 模型采用了这种 DeepNarrow 的结构。

| Param | Bert | Bert-DeepNarrow |
| Hidden size | 768 | 512 |
| intermediate_size | 3072 | 2048 |
| num_attention_heads | 12 | 8 |
| attention_head_size | 64 | 64 |
| num_hidden_layers | 12 | 24 |
| CLUE dev score | 67.48 | 68.22(+0.74) |
以上两点修改,使得 3MP-Text 模型,相比同参数规模的 BERT 模型,训练时间多 60%,训练成本相应增加,对模型在实际业务场景的应用,造成一定障碍。比如,采用领域预训练的方法,提升 3MP-Text 模型在手机舆情领域任务上的整体表现,由于模型训练时间比 BERT 长 60%,采用该模型会使业务功能的上线时间明显延迟,从而影响了正常迭代优化。
应用方案
本案例将以 NVIDIA GPU 单卡训练情况为例,展开介绍 NVIDIA 所进行的算子优化。
如上文提到,含有相对位置编码的注意力机制计算耗时占比达 71.5%,因此,NVIDIA 团队优先对该模块进行了优化,其中包括 gather 算子、dropout 算子、softmax 算子和 scale 算子的优化。
- Gather 算子优化:
对于 gather 操作本身,在 cuda kernel 实现方面,采用了 float4/half4 等数据类型进行向量化读写(一次读写 4 个 float 或 4个 half 元素),并且利用 shared memory 确保合并访问,从而优化 gather(前向)/scatter(反向)cuda kernels。
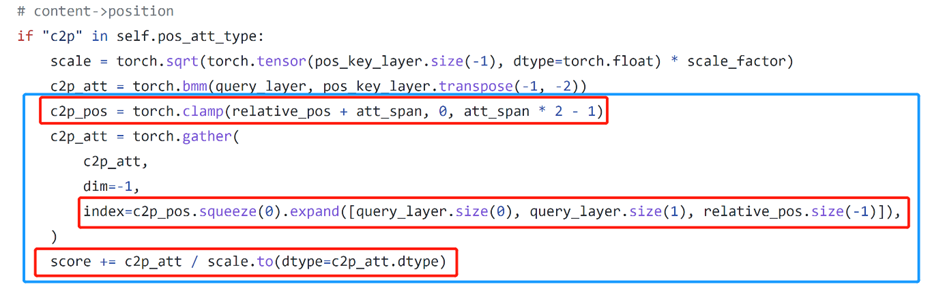
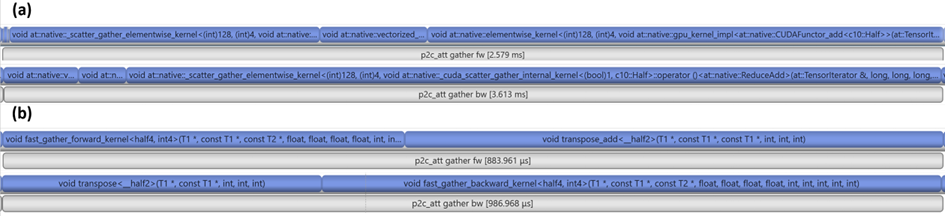
除了 gather 本身的优化外,如图 3 所示的 pytorch 代码中看到,有不少 elementwise 的操作(红框所示)可以通过 kernel 融合(kernel fusion)的优化手段,把它们都融合到一个 cuda kernel(蓝框所示)中,从而提升性能。如图 4 所示,在进行 kernel 融合前,完成相应计算需要 9 个 cuda kernels,kernel 融合后,只需 要4 个 cuda kernels。
综合 gather kernel 优化和 kernel 融合优化,该模块性能提升 3.3 倍。
- Dropout 算子优化:
在 debertaV2 中会使用 StableDropout,如果仔细对比 pytorch 代码,会发现其计算公式绝大部分情况下可以简化为:
Step 1. rand_data = torch.rand_like(input)
Step 2. x.bernoulli_(1 – dropout) == rand_data < (1 – dropout)
Step 3. mask = (1 – torch.empty_like(input).bernoulli_(1 – dropout)).to(torch.bool)
Step 4. input.masked_fill(mask, 0) * (1.0 / (1 – dropout))
显然上述操作涉及大量的 elementwise 的操作,因此把 step 2~4 融合到一个独立的 cuda kernel中,同时再次采用了 float4/half4 等数据类型进行向量化读写来优化 cuda kernel。
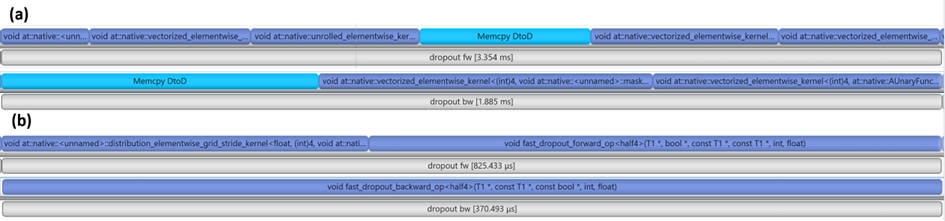
如图 5 所示,在进行 kernel 融合前,完成相应计算需要 9 个 cuda kernels,kernel 融合后,只需要 3 个 cuda kernels。
综合 dropout kernel 优化和 kernel 融合优化,该模块性能提升 4.5 倍。
- Softmax 算子优化:
与 dropout 类似,根据源码对 Softmax 算子的计算步骤进行如下划分:
Step 1. rmask = ~(mask.to(torch.bool))
Step 2. output = input.masked_fill(rmask, torch.tensor(torch.finfo(input.dtype).min))
Step 3. output = torch.softmax(output, self.dim)
Step 4. output.masked_fill_(rmask, 0)
把step 1~4 融合到一个独立的 cuda kernel 中。由于 softmax 计算中涉及 cuda 线程之间的同步操作,当采用float4/half4等数据类型进行向量化读写时,也减少了参与同步的 cuda 线程数目,从而减少了同步的开销。此外,NVIDIA 团队也利用寄存器数组来缓存数据,避免了多次从全局内存中读取数据。
在 softmax 优化中,只优化了其前向,沿用了原有的反向实现。如图 6 所示,经过优化后,该模块前向性能提升 4 倍。

- Scale 算子优化:
如图 7 所示,在 attention 部分,计算 attention score 时会有一个除以 scale 的操作,这个除法操作其实可以很容易通过 cublas 的 API 融合 到矩阵乘法之中,因此,直接调用 cublasGemmStridedBatchedEx() API,实现了一个融合 gemm + scale 的 torch op。取得了 1.9x 的加速比(优化前 1.42 ms,优化后 0.75 ms)。

- Layernorm 算子优化:
除了上述提到算子外,还通过改造 apex 中的 layer_norm 模块,以便在 hidden dim=512 情况下,优化 layernorm 算子,取得了 2.4 倍的加速比(优化前 0.53 ms,优化后 0.22 ms)。
使用效果及影响
使用 NVIDIA 做的算子优化,vivo 3MP-Text 模型的训练速度提升 60%,达到了和同规模 BERT 模型相同的速度,下游业务应用时,模型的训练速度不再成为瓶颈,训练成本进一步降低。另外,这些算子优化,也可以应用到其他使用 Deberta V2 模型的场景中。
未来,vivo AI 团队和 NVIDIA 将在大模型分布式训练、推理等方面持续合作,共同推进 生成式 AI 在手机场景行业的应用落地(如语音助手、智能创作、智能办公等)和性能提升。
[1] https://www.cluebenchmarks.com/rank.html
[2] DeBERTa: Decoding-enhanced BERT with Disentangled Attention, ICLR 2021