
基准测试是测量性能的重要工具,但在快速发展的领域中很难追上尖端技术的发展步伐。日前,Intel 就他们应允已久的 Xeon Phi 处理器公布了一些错误的“事实”。
如今,几乎没有几个领域的发展速度比得上深度学习。现在的神经网络与几年前相比已加深了 6 倍,并且功能也更加强大了。在多 GPU 扩展方面也出现了新的技术,可提供更快速的训练性能。
此外,从 Kepler 更换到 Maxwell,再到当前新推出的基于 Pascal 架构的系统(例如拥有八个 Tesla P100 GPU 的 DGX-1),我们的架构和软件已在一年内将神经网络的训练时间缩短了 10 多倍。
因此,刚刚踏入这个领域的人不清楚已在硬件和软件方面出现的种种发展,是可以理解的。
例如,Intel 日前刚刚发布了一些过时的测试基准,对使用 Knights Landing Xeon Phi 处理器进行深度学习的性能提出了以下三项主张:
- Xeon Phi 在训练方面的速度是 GPU 的 2.3 倍(1)
- Xeon Phi 可提供高出 GPU 38% 的节点可扩展性能(2)
- Xeon Phi 可提供高达 128 个节点的可扩展性能,而 GPU 无法做到这一点(3)
在此,我们要对这三点进行说明,并更正可能对读者造成的误解。
Caffe 的新旧之别
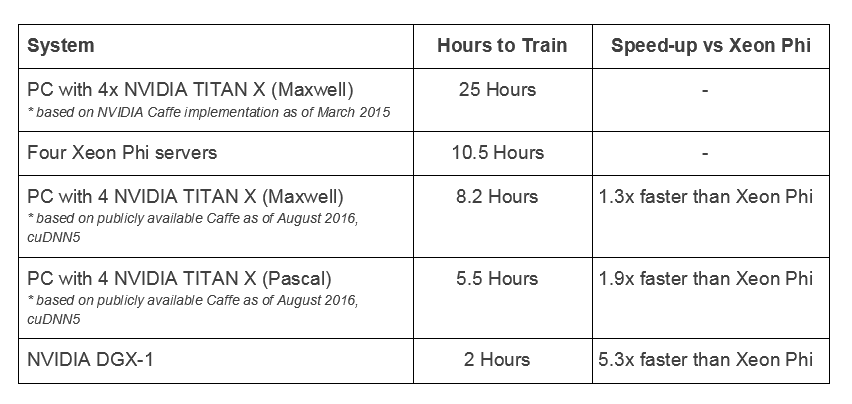
Intel 使用 18 个月前的 Caffe AlexNet 数据,将采用四个 Maxwell GPU 的系统与四个 Xeon Phi 服务器进行了比较。如果根据最近发布的 Caffe AlexNet 数据(可从此处公开获得),Intel 就会发现采用四个 Maxwell GPU 的同一系统在训练速度方面要比四个 Xeon Phi 服务器快 30%。
事实上,搭载四个基于 Pascal 架构的 NVIDIA TITAN X GPU 的系统在训练速度方面要快 90%,而一个 NVIDIA DGX-1 更是比四个 Xeon Phi 服务器的训练速度快上 5 倍。
高出 38% 的可扩展性能
Intel 将在 32 个 Xeon Phi 服务器上的 Caffe GoogleNet 训练性能,与在橡树岭国家实验室 Titan 超级计算机的 32 个服务器上的训练性能进行比较。Titan 使用的是四年前的 GPU (Tesla K20X) 和继承自更早以前 Jaguar 超级计算机的互联技术。Xeon Phi 的测试结果则是采用最新的互联技术。
借助较新的 Maxwell 架构 GPU 和互联技术,百度表示他们的语音训练工作负载可以线性扩展至多达 128 个 GPU。
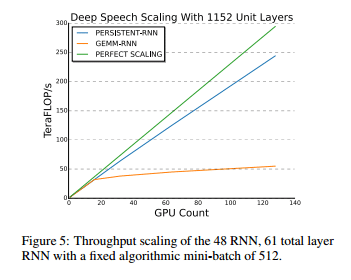
资料来源:Persistent RNNs:Stashing Recurrent Weights On-Chip, G.Diamos
可扩展性取决于代码与底层处理器中的互联技术和架构优化。GPU 可为像百度这样的客户提供优秀的可扩展性能。
强大的可扩展性能可达 128 个节点
Intel 声称 128 个 Xeon Phi 服务器的性能比一个 Xeon Phi 服务器的性能高出 50 倍,而 GPU 却无此相关可扩展数据。如上所述,百度公布的结果则显示可以近乎线性的方式扩展至多达 128 个 GPU。
在强大的可扩展性能方面,我们相信强节点要优于弱节点。一个拥有多个强大 GPU 的强大服务器相比多个弱节点来说,能提供更出色的性能,其中每个弱节点拥有一个或两个像 Xeon Phi 一样能力欠佳的处理器插槽。举例来说,一个 DGX-1 系统可比至少 21 个 Xeon Phi 服务器提供更高的可扩展性能(DGX-1 的速度是 4 个 Xeon Phi 服务器的 5.3 倍)。
人工智能时代
深度学习可能会使计算发生革命性变化、改善我们的生活、提升商业系统的效率和智能性,并以影响深远的方式协助人们在诸多领域取得进展。这正是我们多年来不断增强并行处理器的设计,打造出能够加速深度学习的软件和技术的原因。
我们深入且广泛地投入到深度学习的研究中。每个框架都会获得 NVIDIA 的倾力支持,且每个重量级的深度学习研究人员、实验室及企业也都在使用 NVIDIA 的 GPU。
尽管我们可以更正对方的每一个错误主张,但我们认为,对旧式 Kepler GPU 和已过时的软件版本进行深度学习测试是可以轻松修正的错误,这样才能让产业与时俱进。
很高兴 Intel 如今也在致力于深度学习领域的研究。这是人工智能时代尤为重要的计算革命,并且深度学习的浪潮已大到不可忽视。不过他们还是应该认清事实。