
编者注:本文属于《解码 AI》系列栏目,该系列的目的是让技术更加简单易懂,从而解密 AI,同时向 NVIDIA RTX PC 和工作站用户展示全新硬件、软件、工具和加速特性。
简化和优化生成式 AI 开发的工具备受追捧,需求与日俱增。借助基于检索增强生成 (RAG)(该技术通过从指定外部来源获取事实资料,来提高生成式 AI 模型的准确性和可靠性)的应用和自定义模型,开发者能够根据其具体需求调整 AI 模型。
此类工作在过去可能需要复杂的设置,而新工具使这项工作变得空前简单。
NVIDIA AI Workbench 可协助 AI 开发者构建自己的 RAG 项目、自定义模型等等,这些功能简化了开发者的工作流。该工具是本月初在 COMPUTEX 展会上推出的 RTX AI Toolkit 的一部分,它是一套用于自定义、优化和部署 AI 功能的工具和软件开发套件。复杂的技术任务有可能误导专家并让初学者难以上手,而 AI Workbench 使其复杂度大大降低。
NVIDIA AI Workbench 是什么?
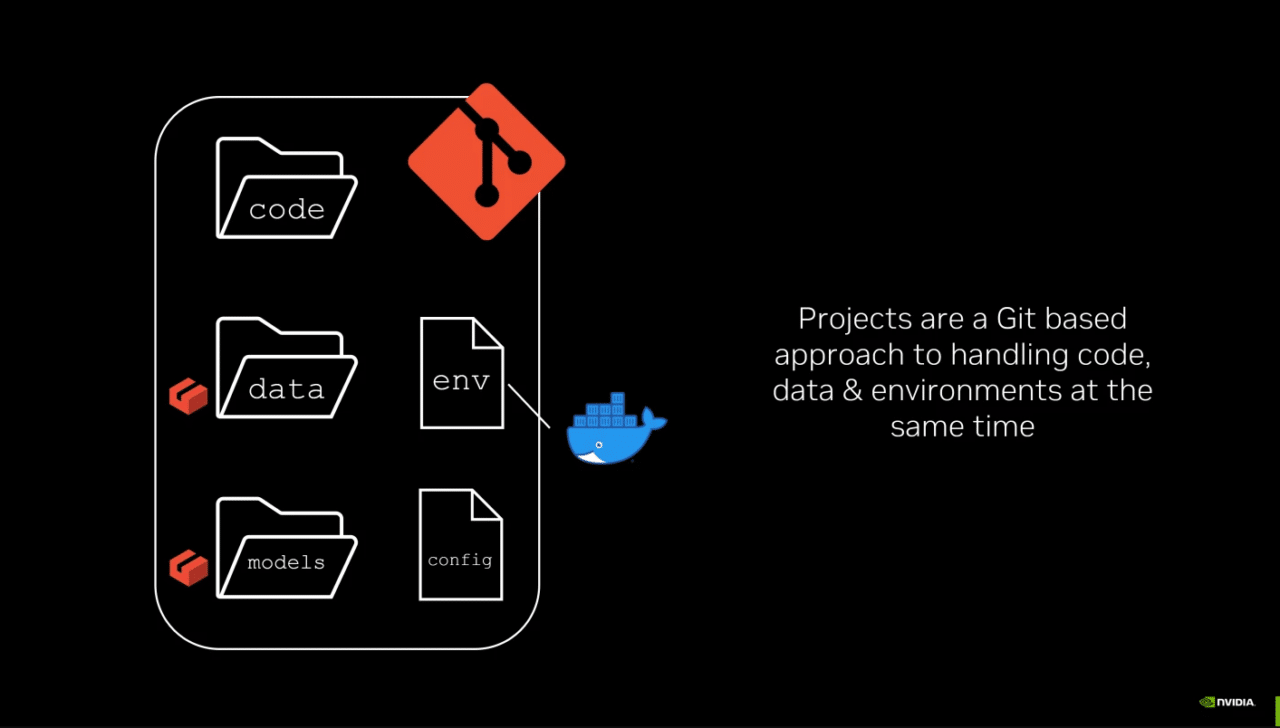
用户可免费使用 NVIDIA AI Workbench,用户能够在各类 GPU 系统(如笔记本电脑和工作站到数据中心和云计算)上开发、试验、测试 AI 应用和制作 AI 应用原型。该工具为各类用户跨系统创建、使用和共享 GPU 开发环境提供了新的方法。
用户只需花几分钟即可轻松安装,在本地或远程机器上启动并运行 AI Workbench。然后,用户就可以新建项目或从 GitHub 上的示例中复制一个项目。一切都通过 GitHub 或 GitLab 进行,因此用户可以轻松进行协作和分发工作。深入了解如何开始使用 AI Workbench。
AI Workbench 如何助力解决 AI 项目的挑战
开发 AI 工作负载从一开始就需要手动执行一些通常来说很复杂的流程。
设置 GPU、更新驱动和管理版本不兼容问题可能会很麻烦。在不同系统之间复制项目可能需要一遍又一遍地重复手动流程。复制项目时若出现数据碎片化和版本控制问题等不一致情况,还可能阻碍协作。各种设置流程、移动凭据和机密,以及更改环境、数据、模型和文件位置都会限制项目的可移植性。
借助 AI Workbench,数据科学家和开发者可以更轻松地跨异构平台管理工作和协作。该工具在开发流程的各个方面实现了集成和自动化,并具有以下特点:
- 易于设置:AI Workbench 简化了 GPU 加速的开发环境的设置流程,让技术知识有限的用户也能操作。
- 无缝协作:AI Workbench 与 GitHub 和 GitLab 等版本控制和项目管理工具集成,有助于减少协作时可能产生的不便。
- 从本地扩展到云端时保持一致性:AI Workbench 确保跨多个环境依然可以保持一致性,支持在本地工作站或 PC 和数据中心或云端之间扩容或缩容。
利用 RAG 处理文档,操作比以往更加顺畅
NVIDIA 提供 Workbench 项目开发示例,协助用户开始使用 AI Workbench。 混合式 RAG Workbench 项目就是一个例子:它在本地工作站、PC 或远程系统上运行基于文本的自定义 RAG Web 应用来处理用户的文档。
每个 Workbench 项目都在一个“容器”(即包含运行 AI 应用所需的所有必要组件的软件)中运行。混合式 RAG 示例将主机上的 Gradio 聊天界面前端与容器化 RAG 服务器配对,而后端负责处理用户请求并在向量数据库和所选的大语言模型之间传输数据。
该 Workbench 项目支持 NVIDIA GitHub 页面上提供的各种 LLM。此外,该项目的混合特性允许用户选择在何处运行推理。
开发者可以在主机上运行嵌入模型,并在 Hugging Face 文本生成推理服务器上本地运行推理,在目标云资源上使用 NVIDIA 推理端点(如 NVIDIA API 目录),或使用自托管微服务(如 NVIDIA NIM 或第三方服务)运行推理。
混合式 RAG Workbench 项目还包括:
- 性能指标:用户可以评估基于RAG和非RAG的用户查询在每种推理模式中的表现情况。这些指标包括检索时间、首 Token 延迟 (Time to First Token, TTFT) 和 Token 速率 (Token Velocity)。
- 检索透明度:面板会显示精确文本片段(在向量数据库中检索到的语义相关度最高的内容),并且这些片段会被输入到 LLM 中,以提高回复与用户请求的相关度。
- 响应自定义:用户可以使用各种参数调整响应,例如要生成的最大令牌数、温度和频率惩罚。
您只需在本地系统上安装 AI Workbench,即可开启此项目。您可将混合式 RAG Workbench 项目从 GitHub 带入到用户帐户并复制到本地系统。
如需了解详情,请前往 AI Decoded 用户指南获取更多资源。此外,社区成员还提供实用的视频教程,例如下面来自 Joe Freeman 的教程。
自定义、优化、部署
开发者经常试图针对特定用例自定义 AI 模型。微调是一种通过使用额外数据训练模型,进而改变模型的技术,该技术可用于风格迁移或改变模型行为。AI Workbench 也有助于进行微调。
Llama-factory AI Workbench 项目提供适用于各种模型的 QLoRa (一种可大幅减少内存需求的微调方法),并可通过简单的图形用户界面实现模型量化。开发者可以使用公开或自有的数据集来满足其应用的需求。
微调完成后,用户即可对模型进行量化以提高性能并减少显存占用,然后将其部署到原生 Windows 应用进行本地推理或部署到 NVIDIA NIM 进行云推理。如需了解该项目的完整教程,请在 NVIDIA RTX AI Toolkit 仓库中进行查找。
真正的混合式设计:随时随地运行 AI 任务
上述的混合式 RAG Workbench 项目在多个方面采用混合式设计。除了提供推理模式选择外,该项目还可以在 NVIDIA RTX 工作站和 GeForce RTX PC 上本地运行,或扩展到远程云服务器和数据中心。
用户可以在自己选择的系统上运行所有 Workbench 项目,并且不会在设置基础设施方面产生开销。在 AI Workbench 快速入门指南中查找更多关于微调和自定义的示例和说明。
请订阅《解码 AI》时事通讯,我们每周都会将新鲜资讯直接投递到您的收件箱。