
上海硅程科技 (Silicon Thread) 是一家聚焦于 AI 与 EDA 技术融合的创新公司,其面向芯片设计与制造的协同优化场景,开发新一代 AI EDA 软件。
在本案例中,Silicon Thread 将深度神经网络、物理约束层与 TensorRT、CUDA 等技术结合,构建了可直接处理大规模芯片设计的 AI OPC 软件。该软件面向完整的芯片设计版图,自动完成版图读取、数据预处理、GPU 并行计算和基于标准格式 (GDSII/OASIS) 的版图输出。该软件能够将传统 OPC 流程中 15 轮的迭代修正压缩到 3 轮。
在配备 4 张 NVIDIA RTX 5880 Ada GPU 的单台工作站上,软件在 4 小时内完成了 10mm × 10mm、28nm 工艺、Metal 1 层的 OPC 任务。过去,这类工业级任务通常需要调度 1000 核以上高性能 CPU。这类长期由大规模计算基础设施承担的关键任务,开始能够在工作站平台上完成,这也意味着,GPU 能够大幅提升传统计算任务的运行效率。

背景
芯片制造并不是将芯片设计版图直接给光刻机“曝光打印”出来,实际流程极其复杂。
芯片设计中包含亿万级的微小电路结构。它们小到在光刻过程中,会受到光学衍射、光刻胶显影等的极大影响,图形结构会产生大量的畸变。原本笔直的线条,可能会变窄;原本方正的拐角,会变圆;彼此靠近的图形,还会互相影响。随着工艺节点持续演进,这种畸变会越来越明显。
如果不提前修正这些畸变,最终制造出来的芯片图形就会偏离原始设计,严重影响芯片性能、可靠性和良率。因此,在先进半导体工艺中,光学邻近效应修正 (OPC,Optical Proximity Correction) 是最为关键的一环。
OPC (Optical Proximity Correction) 是用于补偿光刻机在光刻过程中,由光学衍射和光刻胶成像引入的图形畸变。在芯片正式制造之前,OPC 软件将对芯片设计版图做多轮精细的“预修正”,使光刻后得到的图形,与原始设计保持一致。这些修正,决定了芯片能否被制造出来。
挑战
在 OPC (Optical Proximity Correction) 过程中,光学衍射、光刻胶显影的效应需要基于芯片版图进行光刻仿真。随着芯片关键结构尺寸的缩小,芯片图形密度的上升,光刻效应的耦合关系也越复杂,所需计算量也爆炸式增长。在先进芯片制造中,OPC 成为当前最重、最慢的计算任务。
在传统流程中,OPC 需要多轮迭代。软件先做一次仿真,然后修正评估,再继续仿真、修正与评估。这个过程通常要持续 10 轮以上。每增加一轮,就增加一轮计算时间。在先进制程中,这种时间和算力的开销迅速被放大。

过去,这类工业级 EDA 任务通常需要数千核以上高性能 CPU。CPU 计算集群虽然能解决问题,但运行时间成为一个关键瓶颈 (多达数周),并且运维成本较高。对于很多先进芯片的设计和制造协同团队来说,这会直接影响验证节奏、项目周期和基础设施的投入。
行业长期面对的是这样一个现实问题:OPC 极其重要,但计算量又非常重。将这项关键任务做得更快、更精准,能够直接转化为芯片制造中的实际价值。
方案
上海硅程科技的思路,是把 AI 引入到 OPC 的核心环节中,把“重复迭代”变成“快速推理 + 约束控制”。硅程科技的 AI OPC 软件,将深度神经网络、GPU 并行计算和物理约束结合起来,构造了一套全新的 OPC 工程方法。
在算法层,深度神经网络负责快速生成修正结果。它能够从大量样本中学习复杂图形与 OPC 修正行为之间的关系,根据局部图形的几何关系,做出快速推理。这样,大量依赖反复迭代的修正,转变为更高效的推理过程。
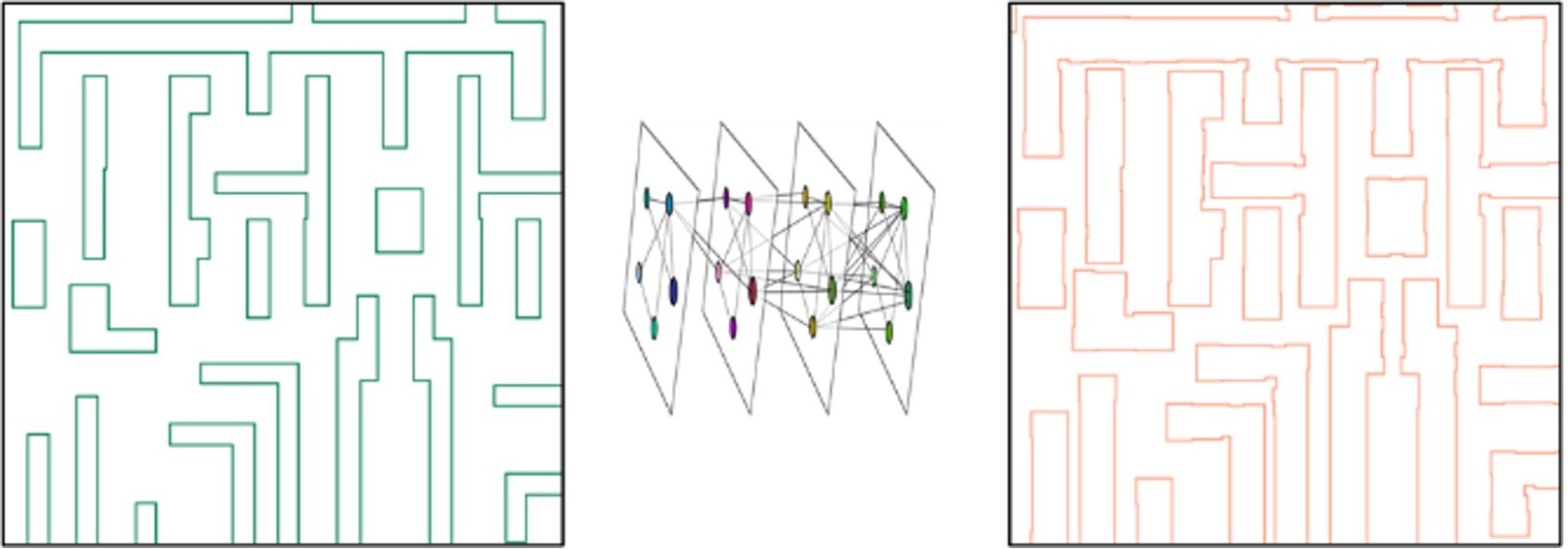
在可靠性层,软件引入了物理约束层。这一步非常关键。因为工业软件不仅要快,还要 100% 准确。物理约束层会对修正幅度和修正形态设置硬性边界约束,把修正限制在可制造的范围内,确保结果不会出现超出约束边界的异常偏移。
在流程效果上,这套方案将传统 OPC 的 15 轮迭代压缩到 3 轮。对于客户而言,这直接意味着大幅缩短的流程时间,更快的优化节奏,以及更高频率推进验证和制造协同。
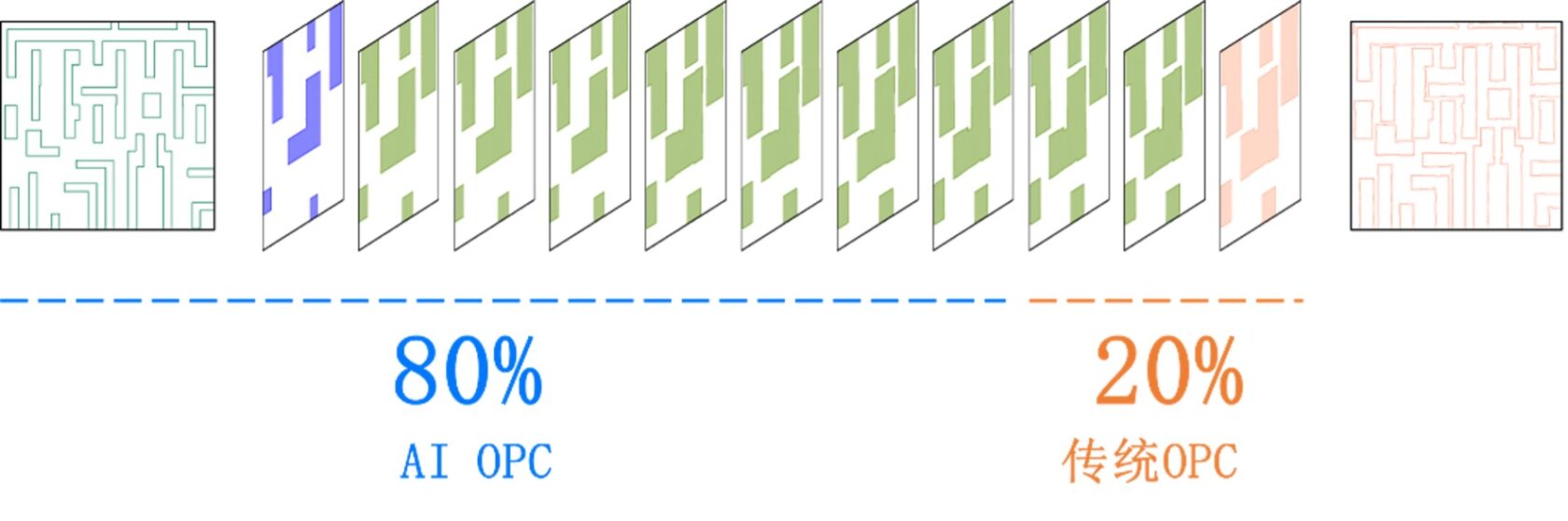
AI 软件真正进入半导体工业流程,难点不仅在模型本身,还在于软件能否吃下生产级的任务。
硅程科技的 AI OPC 软件将超大规模芯片设计自动切分成百万级的处理单元,再将处理单元送入 GPU。这类任务具有极高的并行性,每个处理单元都可以进入相似的推理与后处理流程,非常适合 GPU 的大规模并行计算架构。
在部署测试时,团队采用了 NVIDIA RTX 5880 Ada 作为核心算力平台,并结合 NVIDIA TensorRT 与 NVIDIA CUDA 技术进行推理优化和多卡调度。最终,这套方案在 4 张 NVIDIA RTX 5880 Ada GPU 组成的单台工作站上,于 4 小时内完成了 10mm × 10mm、28nm 工艺、Metal 1 层的 OPC 任务。同样的传统 OPC 任务,需要调度 1000 核以上的高性能 CPU 来运行。
影响
芯片设计与制造的发展,始终依赖设计工具、制造设备和计算平台的共同进步。随着工艺持续演进,传统流程的计算与时间成本急剧攀升。硅程科技的技术创新路径很清晰:用深度神经网络提升效率,用物理约束层确保结果可控,用 NVIDIA TensorRT 和 NVIDIA CUDA 释放 GPU 的计算潜力,用软件架构来整合工业级应用。其中 AI 不是辅助工具,GPU 也不是硬件附属,它们正在真正切入芯片制造前最关键、最耗时的工业级计算任务。
本文中图片由上海硅程科技提供,如果您有任何疑问或需要使用图片,请联系上海硅程科技。
NVIDIA 初创加速计划
上海硅程科技 (Silicon Thread) 是 NVIDIA 初创加速计划会员企业。
NVIDIA 初创加速计划 (NVIDIA Inception) 为免费会员制,旨在培养颠覆行业格局的优秀创业公司。该计划联合国内外知名的风投机构、创业孵化器、创业加速器、行业合作伙伴以及科技创业媒体等,打造创业加速生态系统。能够提供产品折扣、技术支持、市场宣传、融资对接、业务推荐等一系列服务,加速创业公司的发展。