
NVIDIA 首席科学家兼高级研究副总裁 Bill Dally 近日在面向处理器和系统架构师的年度活动 —— Hot Chips 上的主题演讲中表示,硬件性能的巨大提升催生了生成式 AI,并为未来的加速提供了丰富的思路,以推动机器学习能力再创新高。
Dally 是全球最重要的计算机科学家之一,并曾任斯坦福大学计算机科学系主任。他在演讲中介绍了一系列正在研究中的技术,其中一些已经展现出令人印象深刻的成果。
他表示:“在硬件的推动下,AI 取得了巨大的进步,但同时也受限于深度学习硬件。”
例如,他展示了已被数百万人使用的大语言模型(LLM)ChatGPT 如何为他生成演讲提纲。他表示,这些能力所具有的预见性在很大程度上要归功于 GPU 过去十年在 AI 推理性能方面的进步。
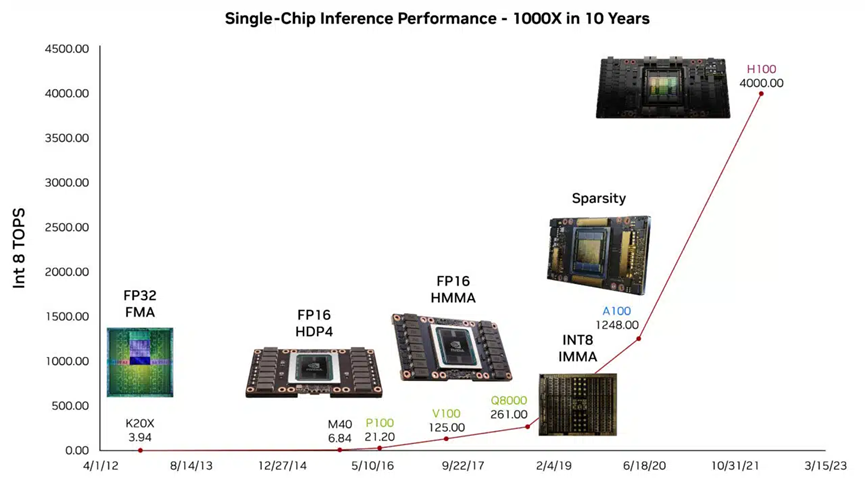
研究实现 100 TOPS 的每瓦性能
研究人员正在为下一轮的性能提升做准备。Dally 介绍了一种测试芯片,该芯片在 LLM 上能够实现 100 TOPS 的每瓦性能。
该实验展示了一种能够进一步加速生成式 AI 中所用 Transformer 模型的节能方法,所使用的四位运算是有望在未来取得成果的几种简化的数值计算方法之一。
展望未来,Dally 介绍了使用对数数学加快计算速度和节省能源的方法,NVIDIA 在 2021 年的一项专利中详细介绍了这种方法。

为 AI 量身定制硬件
Dally 还探索了其他六种通常通过定义新的数据类型或操作为特定 AI 任务定制硬件的技术。
Dally 介绍了简化神经网络的方法,用一种名为结构化稀疏性的方法来修剪突触和神经元。这种方法在 NVIDIA A100 Tensor Core GPU 中首次得以采用。
他表示:“我们并未停止在稀疏性方面的研究。我们需要在激活方面开展一些工作,还可以提高稀疏性的权重。”
他表示,研究人员需要同时设计硬件和软件,慎重地决定将宝贵的精力花在哪方面。例如,存储器和通信电路需要最大程度地减少数据移动。
Dally 表示:“对于计算机工程师来说,这是一个有趣的时代,这是因为虽然我们正在推动 AI 这场巨大的革命,但还没有完全意识到这场革命的规模有多大。”
更加灵活的网络
在另一场演讲中,NVIDIA 网络副总裁 Kevin Deierling 介绍了 NVIDIA BlueField DPU 和 NVIDIA Spectrum 网络交换机独有的灵活性,它们可根据不断变化的网络流量或用户规则来分配资源。
这些芯片能够在几秒钟内动态切换硬件加速流程,从而在实现最大吞吐量的情况下保持负载平衡,同时将核心网络的适应性提升至新高。这对于防御网络安全威胁尤其有用。
Deierling 表示:“如今,生成式 AI 工作负载和网络安全使一切都在不断发展变化,因此我们将关注点转向了运行时可编程性和可以动态更改的资源。”
此外,NVIDIA 和莱斯大学的研究人员正在开发能够让用户使用常用的 P4 编程语言来充分利用运行时灵活性的方法。
Grace 引领服务器 CPU
Arm 在介绍其 Neoverse V2 核心的演讲中谈到了 NVIDIA Grace CPU 超级芯片的性能更新。该超级芯片是首款采用 Neoverse V2 核心的处理器。
测试表明,在相同功率下,Grace 系统在各种 CPU 工作负载下的吞吐量比当前的 x86 服务器高出两倍。此外,Arm 的 SystemReady 计划证明了 Grace 系统无需任何更改就能运行现有的 Arm 操作系统、容器和应用。
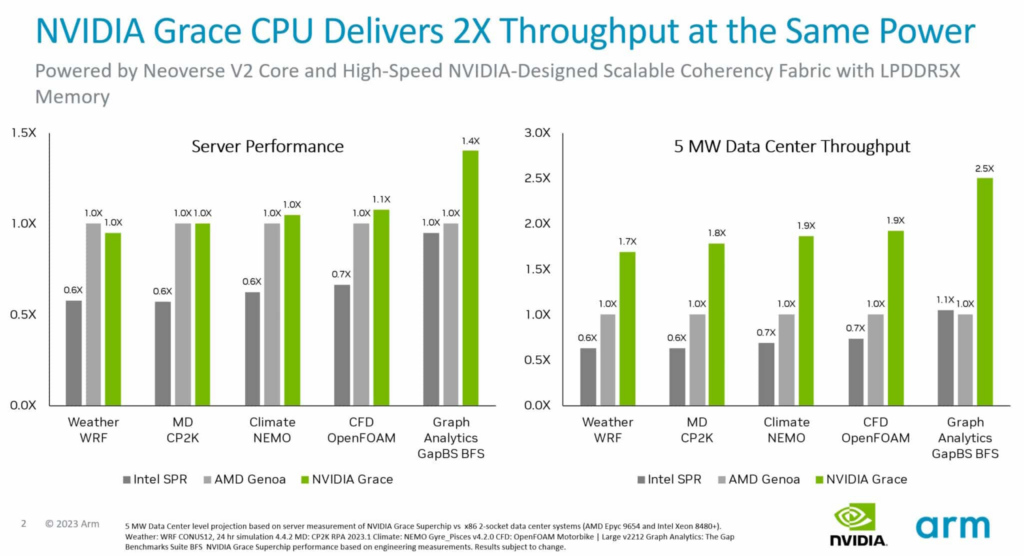
Grace CPU 使用一种超快速结构,在每个裸片中连接 72 颗 Arm Neoverse V2 核心,然后使用某个版本的 NVLink 将其中两个裸片连接到同一封装中,实现了 900 GB/s 的带宽。它是首款使用服务器级 LPDDR5X 内存的数据中心 CPU,在保持成本基本不变的情况下将内存带宽提升 50% 以上,而功率仅仅是普通服务器内存的八分之一。
Hot Chips 于 8 月 27 日至 29 日举办,并提供一整天的现场培训课程,其中也包含了 NVIDIA 专家于大会首日发表了关于 AI 推理和芯片间互连协议的演讲。