
案例简介
- 本案例中,金山办公与 NVIDIA 团队合作,通过 NVIDIA GPU、TensorRT 提升图像文档识别与理解的推理效率;借助 NVIDIA Triton 推理服务器的部署,成功优化 GPU 利用率,提供高推理吞吐量。
- 本案例主要应用到 NVIDIA T4 Tensor Core GPU、NVIDIA Triton 推理服务器及 NVIDIA TensorRT。
客户简介及应用背景
金山办公是一家办公软件和服务提供商 ,主要从事 WPS Office 办公软件产品及服务的设计研发及销售推⼴。产品包括 WPS Office 办公软件、⾦⼭⽂档等协同办公产品、图像文档识别与理解业务,可在 Windows、Linux、macOS、Android、iOS 、Harmony 等众多主流操作平台上应⽤,于全球也有越来越多的用户乐享金山办公提供的产品和服务。
在办公场景中,文档类型图像被广泛使用,比如证件、发票、合同、保险单、扫描书籍、拍摄的表格等,这类图像包含了大量的纯文本信息,还包含有表格、图片、印章、手写、公式等复杂的版面布局和结构信息。早前这些信息均采用人工来处理,需要耗费大量人力,很大程度上阻碍了企业的办公效率 。其图像文档识别与内容理解业务就是为了解决此类用户痛点。
自 2017 年以来的不断耕耘,金山办公在图像文档识别与理解领域已达到了国内领先水平。其主要使用了 CV(Computer Vision)与 VIE (Visual Information Extraction 视觉信息抽取) 等相关深度学习技术,例如通过 CV 技术识别发票和 PDF 大纲并获取其中的数据关系,其日请求次数已达上亿次。
客户挑战
图像识别与理解是一个很复杂的过程,一个任务的 pipeline 用到的深度学习模型多达 20+ 个,且日请求量级较大(上亿级别)需要大量的计算资源。当业务落地时,团队主要面临以下两个挑战:
- 任务的绝对耗时不能过长。
- 成本问题。
应用方案
为了解决上诉的两个挑战,金山办公采用了 NVIDIA T4 Tensor Core GPU 进行推理、NVIDIA TensorRT 8.2.4 进行模型加速、NVIDIA Triton 推理服务器 22.04 在 K8S 上进行模型部署与编排。
长链路(多达 20+ 个模型的 pipeline)意味着长耗时,若基于 CPU 推理的话,pipeline 耗时会长达 15 秒左右,通过 GPU 推理和 TensorRT 加速,成功将耗时降低到了 2.4 秒左右。 模型部署的时候,常见的做法是推理与业务代码(前后处理)放在一个进程空间里,每个模型需要在每个进程中加载一次,由于显存的限制,很多时候难以得到较高的单卡GPU使用率。就算采用了进程池的方式提高了单卡的 GPU 利用率,也会因 CPU 的限制,出现机器整体的 GPU 利用率不高。而在引入了 Triton 推理服务器进行推理部署后,将推理与业务代码解耦,初步实现将 GPU 资源池化调度。最终在同等业务规模情况下,部署成本节省了23%。
模型耗时
| 模型 | 格式 | 精度 | 平均耗时 | 设备 |
| 段落检测 | pytorch | fp32 | 20ms | T4 |
| onnx | fp32 | 20 ms | T4 | |
| 46 ms | cpu | |||
| tensorrt | fp32 | 14 ms | T4 | |
| tensorrt | fp16 | 11 ms | T4 | |
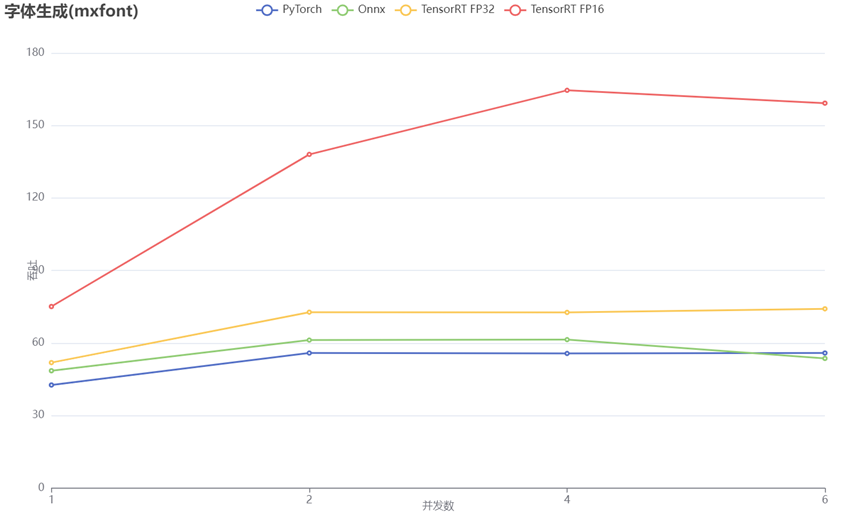
| 字体生成 | pytorch | fp32 | 23 ms | T4 |
| onnx | fp32 | 20 ms | T4 | |
| 124 ms | cpu | |||
| tensorrt | fp32 | 19 ms | T4 | |
| tensorrt | fp16 | 13 ms | T4 | |
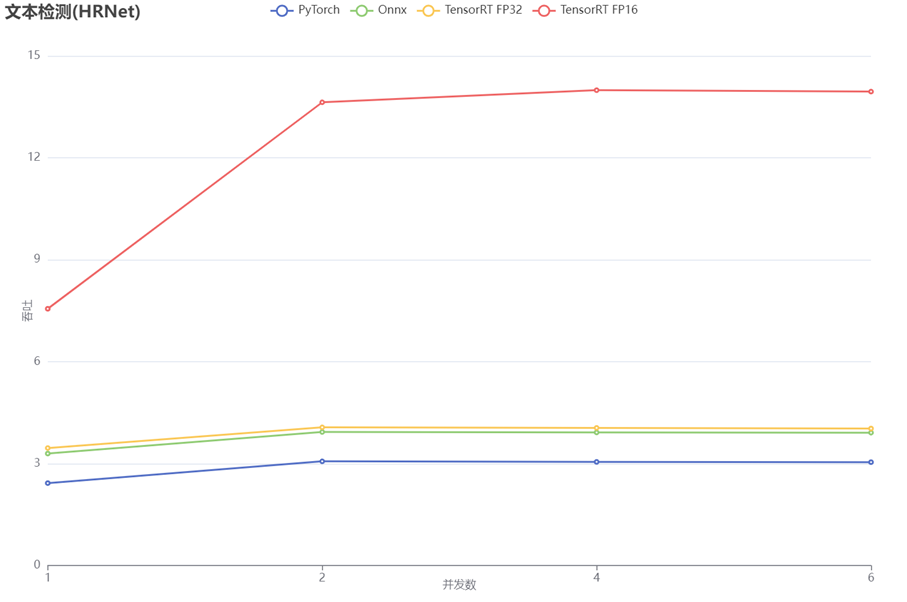
| 文本检测 | pytorch | fp32 | 407 ms | T4 |
| onnx | fp32 | 298 ms | T4 | |
| 1402 ms | cpu | |||
| tensorrt | fp32 | 286 ms | T4 | |
| tensorrt | fp16 | 127 ms | T4 |
模型吞吐量对比图

WPS 生成式 AI 的最新进展
WPS AI 紧跟业界潮流,再发布新 AI 能力,覆盖文字、表格、PPT、PDF 四大办公组件。这部分 AI 新能力集中在阅读理解、问答、人机交互等方面。在 PPT 中,WPS AI 现已支持输入主题,一键生成 PPT 演示文稿,并会根据用户要求进行细化调节,如更改主题风格、单页美化、更改字体、更改配色、生成演讲稿等等。
在 PDF 中,WPS 则展示了阅读分析和理解能力。WPS AI 能够阅读包括论文、合同、课件等文档,用户以问答方式则可以获得关键信息。并且,问答助手也会提供文档溯源功能,确保用户能够得知信息来源。 户能够通过手机等移动设备拍摄相关文档,而后 WPS 给出相关翻译、概括、分析等功能。


使用效果及影响
金山办公图像文档识别与理解业务,通过采用 NVIDIA T4 Tensor Core GPU 及 TensorRT 加速,相比于 CPU 其 pipeline 耗时共下降 84%;而采用 NVIDIA Triton 推理服务器部署,其部署成本节省了 23%。
金山办公 CV 团队总监熊龙飞表示:”我们有多个业务后边的 AI 服务已经通过采用该方案提高了速度和资源利用率,不仅给用户端带去了更高的速度响应,提高了用户体验,也为公司节约了大量的服务端 GPU 资源,收获了更高的效益。我们在文档识别与理解领域的应用案例也可以启发到 OCR 和版式识别领域的其他公司和学者,相信随着更多客户通过采用 TensorRT 加速会给行业带来很大的收益。