
基础模型是在大量无标签数据集上训练的 AI 神经网络,可处理从翻译文本到分析医学影像等各种工作。
1956 年,一间录音室里的麦克风开着,磁带在不停地转动,Miles Davis Quintet 正在里面为 Prestige Records 录制几十首曲子。
当一名录音工程师问起下一首歌曲叫什么时,Davis回答道:“等我演奏完后,再告诉你它叫什么。”
如同这位多产的爵士乐小号手兼作曲家一样,研究人员也一直在以疯狂的速度生成 AI 模型,探索新的架构和用例。他们把精力都放到了开拓新领域上,因此有时会让其他人来分类他们的工作。
一支百来名斯坦福大学研究人员组成的团队在2021年夏天发布了一篇论文,共同完成了这项工作。
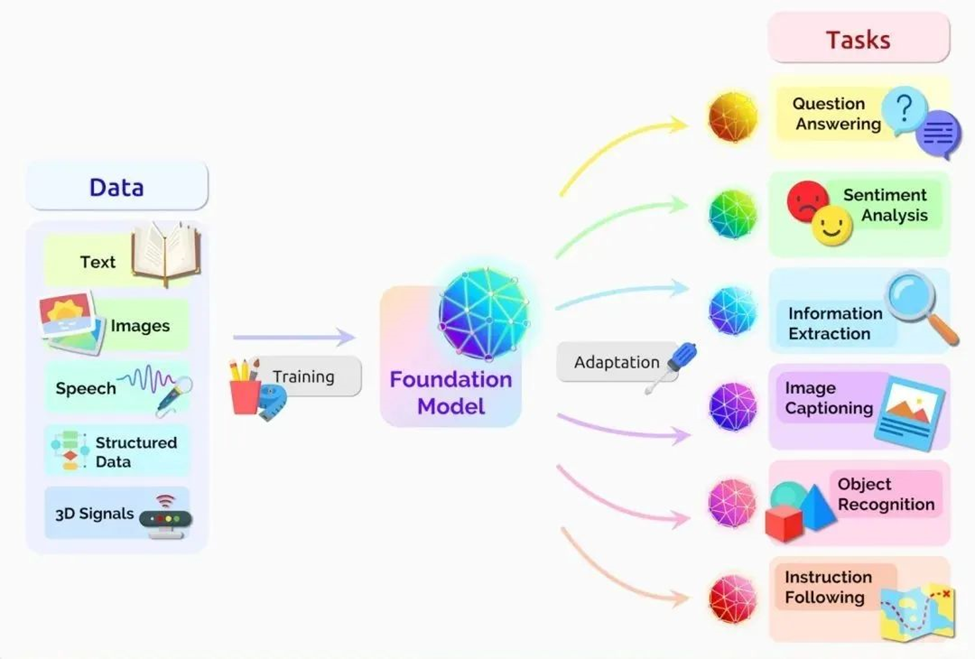
研究人员在 2021 年的一篇论文中表示,基础模型的用途正在变得越来越广泛。
他们把Transformer模型、大型语言模型(LLM)和其他仍在构建的神经网络归入到这个被他们称之为基础模型的重要新类别中。
基础模型的定义
这篇论文将基础模型定义为一种在大量原始数据的基础上通过无监督学习训练而成的AI神经网络,可适应各种任务。
他们在论文中写道:“过去几年中,基础模型的规模和范围超出了我们的想象。”
在定义这个总括性的类别时考虑了两个重要的概念:是否让数据采集变得更容易以及是否有无边无垠的可能性。
没有标签,但有无限的可能性
基础模型通常使用无标签数据集进行学习,节省了手动描述大量数据集内各个项目的时间和费用。
早期的神经网络会被针对特定任务进行严格的调整。在经过略微调整后,基础模型就可以负责从翻译文本到分析医学影像等各类工作。
该团队在其研究中心网站上表示,基础模型正展现出“惊人的行为”并且正在被大规模部署。到目前为止,团队内部研究人员已经发布了50多篇关于基础模型的论文。
中心主任Percy Liang在第一次基础模型研讨会开场演讲中表示:“我认为我们现在只开发了现今基础模型很小一部分的能力,更不用说未来的模型了。”
AI 的涌现和同质化
在那次演讲中,Liang 创造了两个术语来描述基础模型:
涌现指仍在发掘的 AI 特征,比如基础模型中的许多新生技能。他还把 AI 算法和模型架构的混合称为同质化,该趋势推动了基础模型的形成(见下图)。
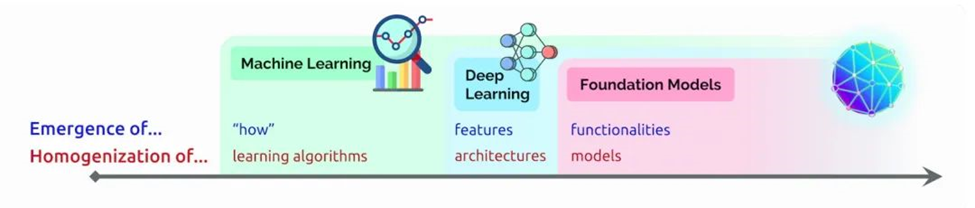
这个领域正在继续快速发展。
在该团队定义基础模型一年后,其他科技观察家创造了一个与之相关的术语——生成式AI。这个总括性的术语指Transformer、大型语言模型、扩散模型等凭借创造文本、图像、音乐、软件等内容的能力拓展人们想象力的神经网络。
风投公司红杉资本的高管在最近的AI播客节目中表示,生成式AI可能创造数万亿美元的经济价值。
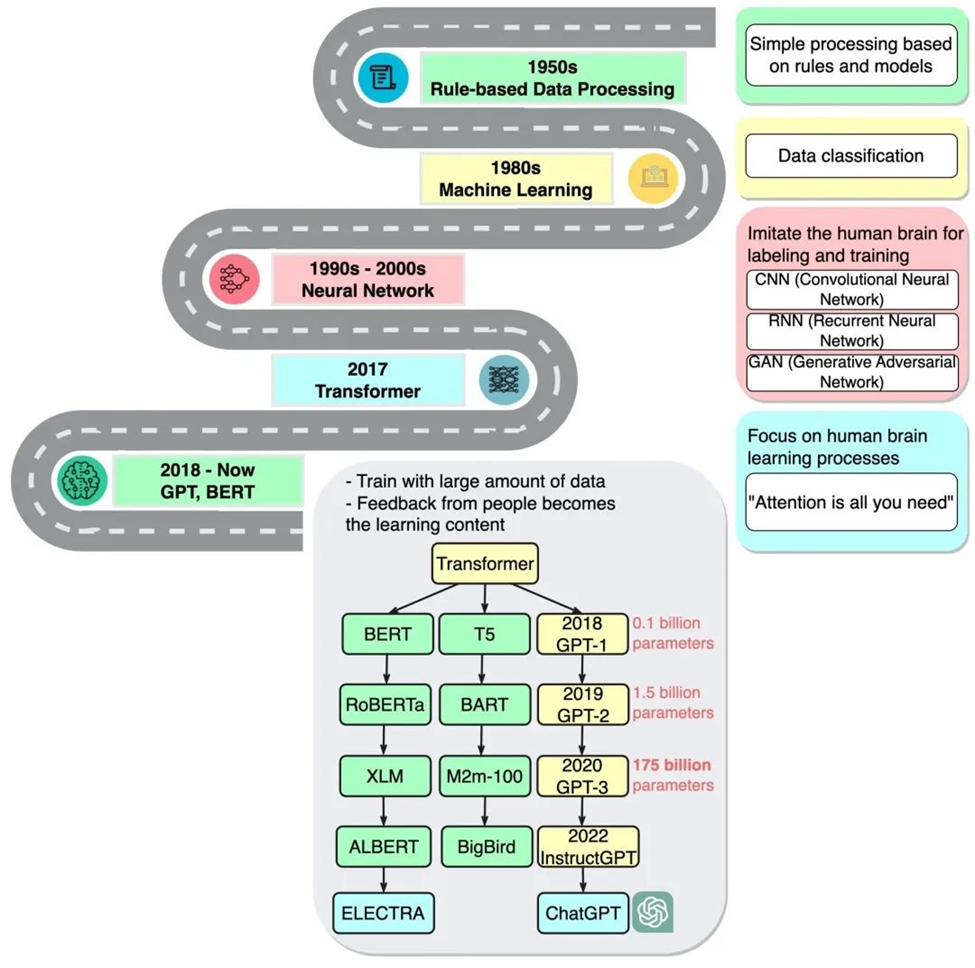
基础模型简史
企业家兼Google Brain前高级研究科学家Ashish Vaswani表示:“我们已进入到一个通过神经网络这样的简单方法就能成倍增加新能力的时代。”他曾领导2017年那篇关于Transformer的开创性论文的研究工作
这篇论文启发了创建BERT和其他大型语言模型的研究人员。2018年末的一篇AI报告写道,2018年是自然语言处理的“分水岭”。
谷歌将BERT作为开源软件发布,催生了一系列后续产品并点燃了一场构建更大、更强的大型语言模型的竞赛。之后,谷歌将该技术应用于其搜索引擎,使用户可以使用简单的句子提问。
2020年,OpenAI的研究人员发布了另一个具有里程碑意义的Transformer —GPT-3。仅仅过了几周,人们就用它来创作诗歌、程序、歌曲、网站等等。
研究人员表示:“语言模型对社会有着各种有益的用途。”
他们的工作也显示了这些模型庞大的规模和计算量。GPT-3 是在一个含近万亿个单词的数据集上训练的,并且拥有高达 1750 亿个参数。而参数量是衡量神经网络能力和复杂性的一个关键指标。
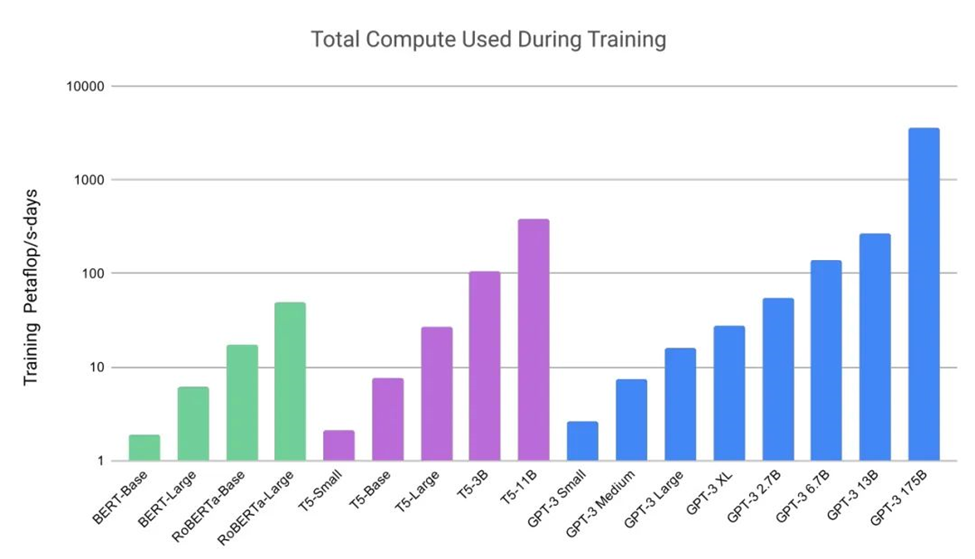
(来源:GPT-3论文)
Liang 在谈到 GPT-3 时说道:“我只记得当时我被它能做的事情吓了一跳。”
而在 10000 个 NVIDIA GPU 上训练而成的最新版本——ChatGPT 更加轰动,在短短两个月内就吸引了超过 1 亿用户。ChatGPT 帮助许多人了解了可以如何使用这项技术,它的发布被称为人工智能的“iPhone 时刻”。
(来源:blog.bytebytego.com)
从文本到图像
大约在 ChatGPT 首次亮相的同时,另一类被称为扩散模型的神经网络也引起了轰动。其将文本描述转化为艺术图像的能力吸引了众多业余用户用它们来创造惊艳的图像并在社交媒体上疯传。
第一篇描述扩散模型的论文在2015年悄无声息地发布,但就像Transformer一样,这项新技术很快就火遍全球。
根据牛津大学AI研究员James Thornton维护的一份清单,研究人员去年发布了200多篇关于扩散模型的论文。
Midjourney首席执行官David Holz透露,其基于扩散模型的文本-图像转换服务已有440多万用户。他在一次采访中表示,为这些用户提供服务需要超过1万颗NVIDIA GPU,这些GPU主要用于AI推理。
数十种正在使用的模型
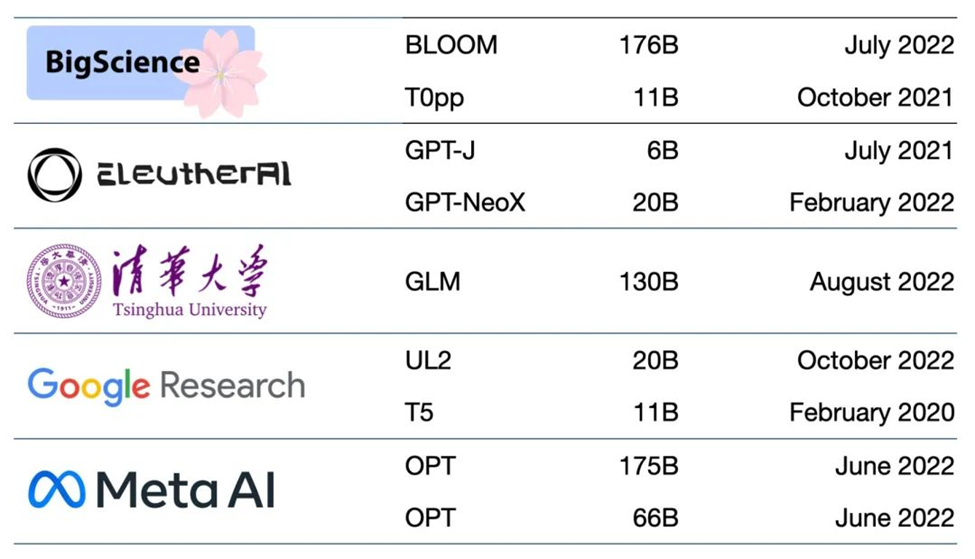
目前有数以百计的基础模型。有一篇论文对50多个主要的Transformer模型进行了编目和分类(见下图)。
斯坦福大学的研究小组对 30 个基础模型进行了基准测试。他们表示,该领域的发展太快,以至于他们没能在这次测试对一些最新和突出的模型进行评估。
初创企业NLP Cloud是领先初创企业培育计划——NVIDIA初创加速计划的成员。该公司表示其在为航空公司、药店和其他用户服务的一项商业产品中使用了大约25个大型语言模型。专家们预计,越来越多的模型将在如Hugging Face的模型中心等网站开放源码。
基础模型也在不断变得更大、更复杂。所以许多企业已经在定制预训练的基础模型来加快向 AI 转型的速度,而不是从头开始构建新的模型。
云中的基础模型
一家风险投资公司列出了从广告生成到语义搜索等33个生成式AI用例。
各大云服务使用基础模型已经有一段时间了。例如微软Azure与NVIDIA一起为其Translator服务构建了一个Transformer。该Transformer帮助救灾人员在应对7.0级地震时理解海地克里奥尔语。
今年2月,微软宣布计划使用ChatGPT和相关创新来改进其浏览器和搜索引擎,表示:“我们将这些工具视为网络中的AI副驾驶。”
谷歌发布了实验性对话式AI服务Bard,计划将其众多产品与LaMDA、PaLM、Imagen、MusicLM等基础模型相结合。
该公司的博客写道:“AI 是我们今天正在研究的最具影响力的技术。”
初创企业也从中获益
初创企业 Jasper 预计其为 VMware 等公司编写文案的产品将带来 7500 万美元的年收入。该企业正在领导由十几家公司组成的文本生成领域,其中包括 NVIDIA 初创加速计划成员 Writer。
该领域的其他初创加速计划成员包括:位于东京的rinna和特拉维夫的Tabnine。前者创造出了被日本数百万人使用的聊天机器人;后者运营的一项生成式AI服务将全球一百万开发者所编写的代码中的30%自动化。
医疗平台
初创企业Evozyne的研究人员利用NVIDIA BioNeMo中的基础模型生成了两种新的蛋白质。其中一种蛋白质可以治疗一种罕见的疾病,另一种可以帮助捕捉大气中的碳。。
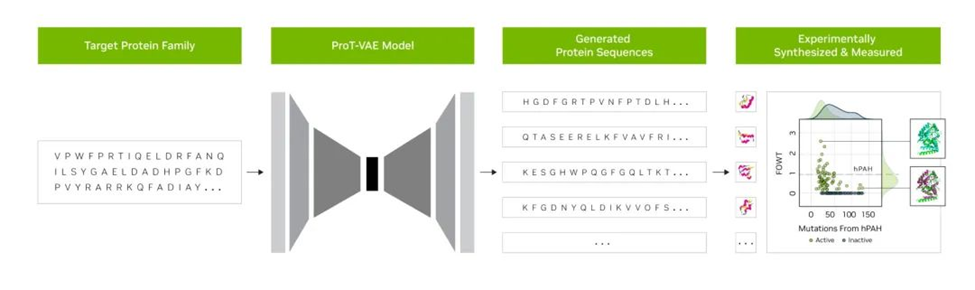
BioNeMo是用于药物研发的生成式AI软件平台和云服务。它提供各种用于训练、运行推理和部署自定义生物分子AI模型的工具,包括由NVIDIA和阿斯利康联合开发的化学生成式AI模型——MegaMolBART。
阿斯利康分子AI、发现科学和研发部门主管Ola Engkvist在宣布该模型时表示:“正如AI语言模型可以学习句子中单词之间的关系一样,我们的目标是让在分子结构数据上训练的神经网络能够学习真实分子中原子之间的关系。”
佛罗里达大学的学术健康中心与NVIDIA研究人员联合创建了大型语言模型GatorTron,该模型能够从大量临床数据中提炼出加速医学研究的洞察。
斯坦福大学的一座中心正在使用最新的扩散模型来推进医学成像。NVIDIA还帮助医疗公司和医院将AI用于医学影像,以便加快对致命疾病的诊断。
商业 AI 基础模型
另一个新框架NVIDIA NeMo Megatron旨在让所有企业能够创建自己的十亿或万亿参数Transformer来驱动自定义聊天机器人、个人助手和其他AI应用。
它创造了拥有5300亿个参数的Megatron-Turing自然语言生成模型(MT-NLG)。该模型驱动了2022年NVIDIA GTC大会上发表了部分主题演讲的“Toy Jensen”虚拟化身。
与NVIDIA Omniverse等3D平台相连的基础模型将是让3D互联网——元宇宙的开发变得更加简单的关键。这些模型将驱动娱乐和工业用户的应用与资产。
工厂和仓库已在数字孪生内使用基础模型,依靠这种逼真的模拟寻找更高效的工作方式。
基础模型可以让训练在工厂车间和物流中心协助人类的自动驾驶汽车和机器人变得更轻松,还可以通过创造现实环境来帮助训练自动驾驶汽车。
基础模型每天都能出现新的用途,但随之而来的还有应用方面的挑战。
有几篇关于基础和生成式 AI 模型的论文描述了一些风险,比如:
- 放大用于训练模型的大量数据集内所隐含的偏见
- 在图像或视频中加入不准确或误导性的信息
- 侵犯现有作品的知识产权
斯坦福大学的一篇关于基础模型的论文写道:“鉴于未来的 AI 系统可能会严重依赖基础模型,我们整个行业必须共同为基础模型制定更严格的原则并提供如何负责任地开发和部署基础模型方面的指导。
目前的一些保障措施包括过滤提示和它们的输出结果、在使用中重新校准模型、清洗大规模数据集等。
NVIDIA 应用深度学习研究副总裁 Bryan Catanzaro 表示:“这些都是我们这些研究人员正在努力解决的问题。为了真正能够广泛部署这些模型,我们必须在安全方面投入大量人力物力。”
这是 AI 研究人员和开发人员在创造未来的过程中所需要探索的又一个领域。