案例简介
- 本案例中合作,腾讯云计算加速套件 TACO Kit 包含 TACO Train 和 TACO Infer 两个 AI组件。基于 GPU 异构计算平台针对业界 AI 训练和推理任务进行了全方位的加速优化。TACO Kit 不仅大大提升了 GPU 集群上多机多卡分布式训练的效率,对于 GPU 上的模型推理也通过集成 NVIDIA TensorRT 带来了显著加速。双方团队就 GPU 推理加速这一话题将进行持续深入的合作,推出定制化的优化方案,为业界客户带来显著的性能收益。
- 本案例主要应用到 NVIDIA GPU,NVIDIA TensorRT,NVIDIA NCCL。
Case Introduction
- In this case, Tencent Cloud Accelerated Computing Optimization Kit provides comprehensive acceleration optimization based on the GPU heterogeneous computing platform for AI training and inference tasks in the industry. TACO Kit not only greatly improves the efficiency of multi-machine, multi-card distributed training on GPU clusters, but it also brings significant acceleration for model inference on GPUs by integrating NVIDIA TensorRT. Both sides will continue to work together on GPU inference acceleration, introducing customized optimization solutions that will bring significant performance benefits to industry customers.
- This case involves NVIDIA GPUs, NVIDIA TensorRT, and NVIDIA NCCL.
客户简介及应用背景
腾讯云计算加速套件 TACO Kit(Tencent Cloud Accelerated Computing Optimization Kit)是一种异构计算加速软件服务,具备领先的 GPU 共享技术和业界唯一的 GPU 在离线混部能力,搭配腾讯自研的软硬件协同优化组件和硬件厂商特有优化方案,支持物理机、云服务器、容器等产品的计算加速、图形渲染、视频转码各个应用场景,帮助用户实现全方位全场景的降本增效。
其中,AI 加速引擎 TACO Train 和 TACO Infer 是腾讯云虚拟化团队依托云帆团队,立足于腾讯内部丰富的 AI 业务场景,深耕训练框架优化、分布式框架优化、网络通信优化、推理性能优化等关键技术,携手打造的一整套 AI 加速方案。为了更好的服务用户,腾讯云决定将内部深度优化的加速方案免费提供给公有云用户,助力广大用户提高 AI 产品迭代效率。
客户挑战
无论对于 AI 训练或AI推理,如何有效提升 AI 任务的性能,节省硬件资源成本,是业界持续追求的目标。在训练方面,随着 AI 模型规模的扩大及训练数据的增多,用户对模型的迭代效率要求也随之增长,单个 GPU 的算力已无法满足大部分业务场景,使用单机多卡或多机多卡训练已成为趋势。但用户在部署分布式训练系统时,时常面临着难以充分利用 GPU 资源、训练效率低下的问题,而分布式训练性能调优却是需要同时进行通信优化、计算优化的极其复杂的问题。
在推理方面,对多种多样的工作负载进行推理加速也是业界共同的需求。这需要考虑如何对不同框架训练的模型进行统一的高效部署;如何整合各类加速软件和技术,对接不同模型和业务场景。
应用方案
在训练方面,TACO Train 推出 Tencent TensorFlow(以下简称 TTF), 针对特定业务场景的 XLA,Grappler 图优化,以及自适应编译框架解决冗余编译的问题,并对 TensorFlow 1.15 添加了对 CUDA 11 的支持,让用户可以使用 NVIDIA A100 Tensor Core GPU 来进行模型训练。另外,TACO Train 推出 LightCC 这一基于 Horovod 深度优化的分布式训练框架,在保留了原生 Horovod 的易用性上,增加了性能更好的通信方式。相比 Horovod,LightCC 能够对 2D AllReduce 充分利用通信带宽;在 GPU 上训练时提供高效的梯度融合方式;并使用 TOPK 压缩通信,降低通信量,提高传输效率。最后,腾讯云自研了用户态网络协议栈 HARP,可以通过 Plug-in 的方式集成到 NVIDIA NCCL 中,无需任何业务改动,加速云上分布式训练性能,从而解决了目前普遍使用的内核网络协议栈存在着一些必要的开销导致其不能很好地利用高速网络设备的问题。
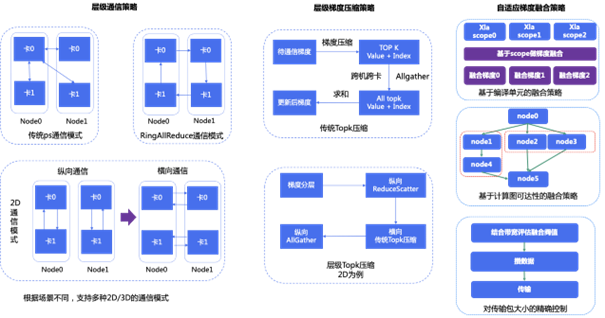
在推理方面,TACO Infer 通过跨平台统一的优化接口赋能用户,让渴望加速计算的用户轻松驾驭腾讯云上丰富的异构算力。TACO Infer 针对 GPU 推理任务,集成了 NVIDIA TensorRT,利用其极致的模型优化能力,使推理过程能够达到令人满意的性能。此外,TACO 也将自定义的高性能 kernel 实现与 TensorRT 相结合,极大地提升用户的推理效率。
使用效果及影响
TACO Kit 针对 GPU 的训练优化,为诸多业务带来了显著的性能提升。在某电商平台推荐业务Wide & Deep 模型训练任务中,TACO Train 提供的方案通过定制化高性能 GPU 算子,使延迟从 14.3ms 下降至 2.8ms;整体训练性能提升 43%,成本下降 11%;在另一电商推荐场景 MMoE 模型的训练任务中,TACO Train 提供的训练方案,在 NVIDIA V100 Tensor Core GPU 集群上,使计算速度性价比相比于 CPU 集群提升了 3.2 倍,收敛速度性价比相比于 CPU 集群提升了 24.3 倍。
目前,腾讯云 TACO Kit 与 NVIDIA 双方团队仍持续为 AI 推理加速进行合作。未来也将针对一些常见的业务模型,围绕 TensorRT 进行联合优化,将模型推理的性能推向更高的水准,为业界有推理加速需求的客户提供一站式的优化方案。