
借助 NVIDIA AI Enterprise 构建 MaaS 平台
本案例中,九州未来的团队基于 NVIDIA AI Enterprise 的全栈软件套件,构建其 MaaS 大模型一体化开发及部署平台,该平台同时支持云端部署和私有化部署,通过九州未来开发的算力调度平台软件,实现云端资源与大模型一体机的算力协调和开发协同。
客户简介
浙江九州未来信息科技有限公司是国内首批提供 OpenStack 云服务的企业,在中国边缘云解决方案市场中位列第二[1]。基于 10 年的技术积累,为客户提供成熟的云基础设施和 AI 智算中心解决方案。围绕算力效率及成本优化目标,九州未来在传统裸算力的简单资源管理方式基础上,通过软件定义精算力,在模型训练效率、硬件资源利用率、基于需求的算法优化及部署简化等方面实现技术突破,以多元化方式管理 GPU,提升 GPU 的附加值,加速垂直模型和应用落地的效率。
目前,九州未来自主研发了“软件+硬件+服务”一体化的大模型一体机,深度集成 NVIDIA AI Enterprise 平台,大模型微调和推理性能相比开源推理框架有大幅提升。内置多种开源大模型和行业大模型,通过强大的推理和微调能力,为客户提供快速、可落地的 AIGC 解决方案。
兼顾企业级的安全性、可靠性和性能
随着大模型的持续发展,特别是垂直领域大模型,提出了对于数据安全性及私密性、模型工具链及平台的通用性和可靠性、模型上线部署的易用性及推理性能等诸多方面提出了更多的诉求。面对快速增长的市场及客户需求,九州未来基于 NVIDIA AI Enterprise 自主开发了其大模型 MaaS 平台,不仅支持端到端的垂直领域大模型的开发全流程,同时支持线下一体机部署与云端资源协调模式,在最大化保护企业数据安全性的同时,兼顾灵活的算力调度与协调供给。
九州未来创始人兼 CEO 张淳先生表示,“AIGC 促进智能算力爆发式增长,并正加速迈入全面应用时代,今后一定不是裸算力简单的资源管理方式,一定需要用软件定义精算力来多元化的管理并提升 GPU 的附加价值,助力加速垂直模型和应用落地的效率。”
为构建自定义生成式 AI 应用提供支持
NVIDIA AI Enterprise 是一个为企业提供生产就绪型全栈的软件解决方案,提供并保证其可靠的 AI 正常运行和不间断的 AI 卓越表现,实现利用生成式 AI 进行创新的企业加速开发。
九州未来通过 10 余年云边自主研发软件的技术积累,结合近年来赋能智算中心的不断落地,通过 NVIDIA AI Enterprise 深度的技术整合,以大模型为基础、轻量化微调的 MaaS 服务作为其核心服务能力之一,基于基础模型训练后的行业大模型,使用相关行业数据进行微调或知识检索能力的导入,再通过 NVIDIA TensorRT-LLM 及 NVIDIA Triton 推理服务器的推理优化和实现一键部署后,可以为特定行业提供高质量高性能的大模型 AI 应用。

上图的大模型 MaaS 平台,端到端包含 Animbus PaaS 平台(集成 NVIDIA GPU Operator 和 Network Operator)、NVIDIA AI Enterprise 软件套件(包括 NeMo Framework – Training Container 和 Inference Container)、MaaS 大模型服务及应用 UI 交互界面,以上所有的软件以及对应的操作系统镜像会打包到一个 U 盘里面,实现一个 U 盘即可快速启动大模型一体机的服务。
NVIDIA NeMo Framework 加速行业大模型开发
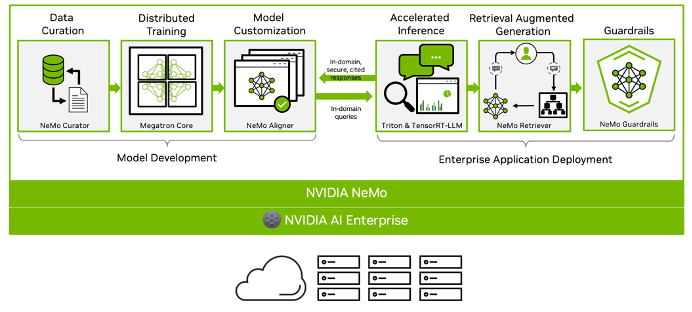
在 MaaS 平台的二次开发和深度整合的过程中,九州未来团队使用 NVIDIA AI Enterprise 中的 NeMo Framework,一款端到端面向企业级交付,云原生大模型的框架,可以灵活地构建、定制和部署生成式 AI 模型。
该平台承载了诸多优质的大模型精选体验,结合特有的行业知识快速导入能力,用户能够很好的训练、微调、评估、优化及部署模型。对于选择好基础模型的用户,提供全流程的向导式服务,训练过程中的训练数据实时可查,用户可轻松基于数据集、使用最好的超参数完成微调任务,在模型完成评估后,实现大模型的一键优化部署。
主要支持训练及优化功能:
- 基础大模型仓库
- SFT/PEFT/提示词工程
- 推理优化及一键部署
- 知识导入及向量数据库服务
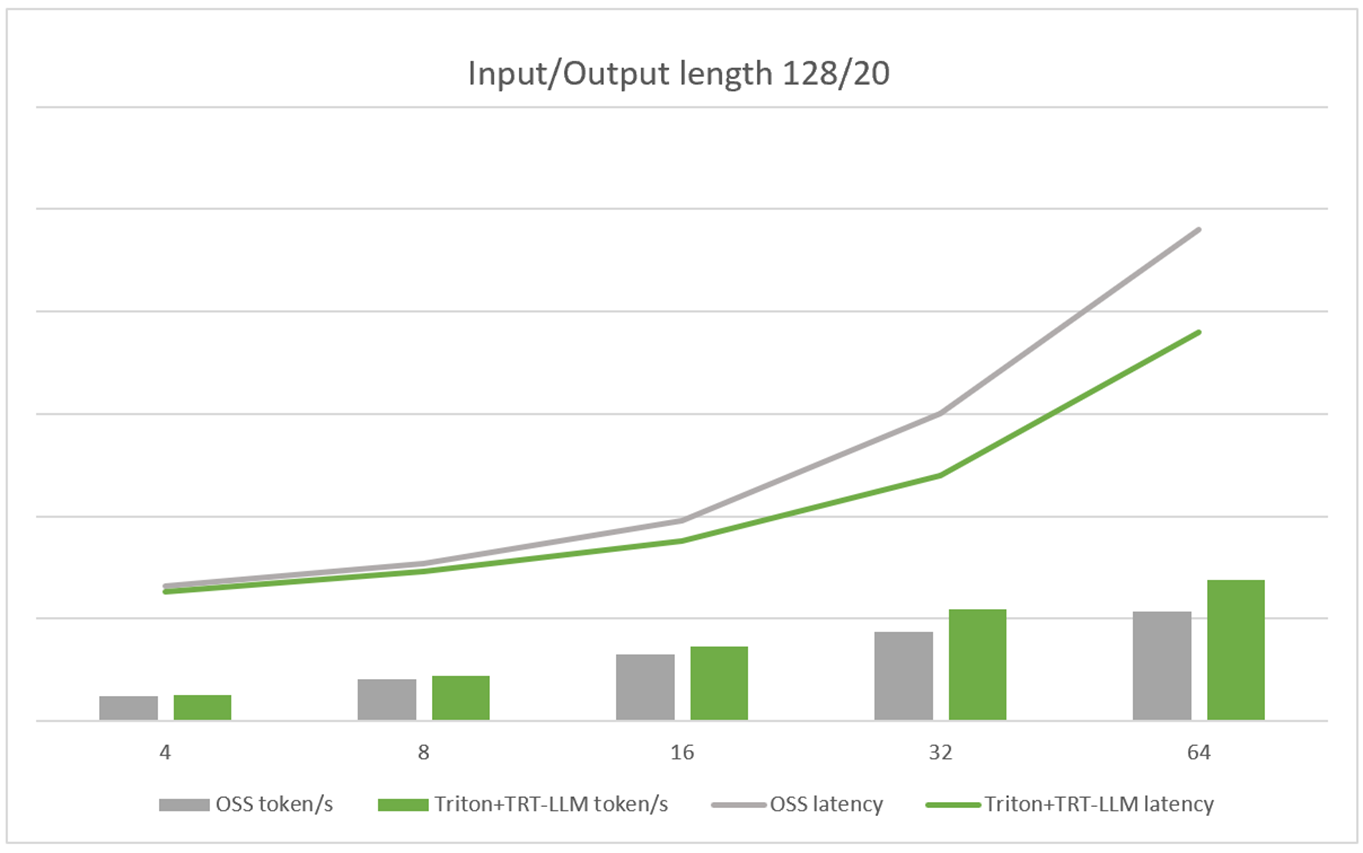
通过 NVIDIA AI Enterprise 整体软件栈的加速,大模型微调和推理性能相比开源推理框架有大幅提升。
[1] 资料来源于 IDC《中国边缘云市场跟踪研究,2022H2》报告