
在企业 AI 领域,理解和使用多种语言不再是可选项,而是满足全球员工、客户和用户需求的必要能力。
多语种信息检索(即跨语言搜索、处理和检索知识的能力)在助力 AI 输出更加准确、更与全球相关联的结果方面发挥着关键作用。
企业可以使用 NVIDIA API 目录中提供的 NVIDIA NeMo Retriever 嵌入和重排序 NVIDIA NIM 微服务,将生成式 AI 成果扩展至准确的多语种系统。这些模型由于能够理解各种语言和格式(如文档等)记录的信息,因此可以大规模地生成准确且符合上下文的结果。
借助 NeMo Retriever,企业现在可以:
- 从大型、多样化的数据集中提炼知识,以提供更多的上下文信息,从而给出更加准确的回答。
- 将生成式 AI 无缝连接到大多数全球主要语言的企业数据,以扩大用户群体。
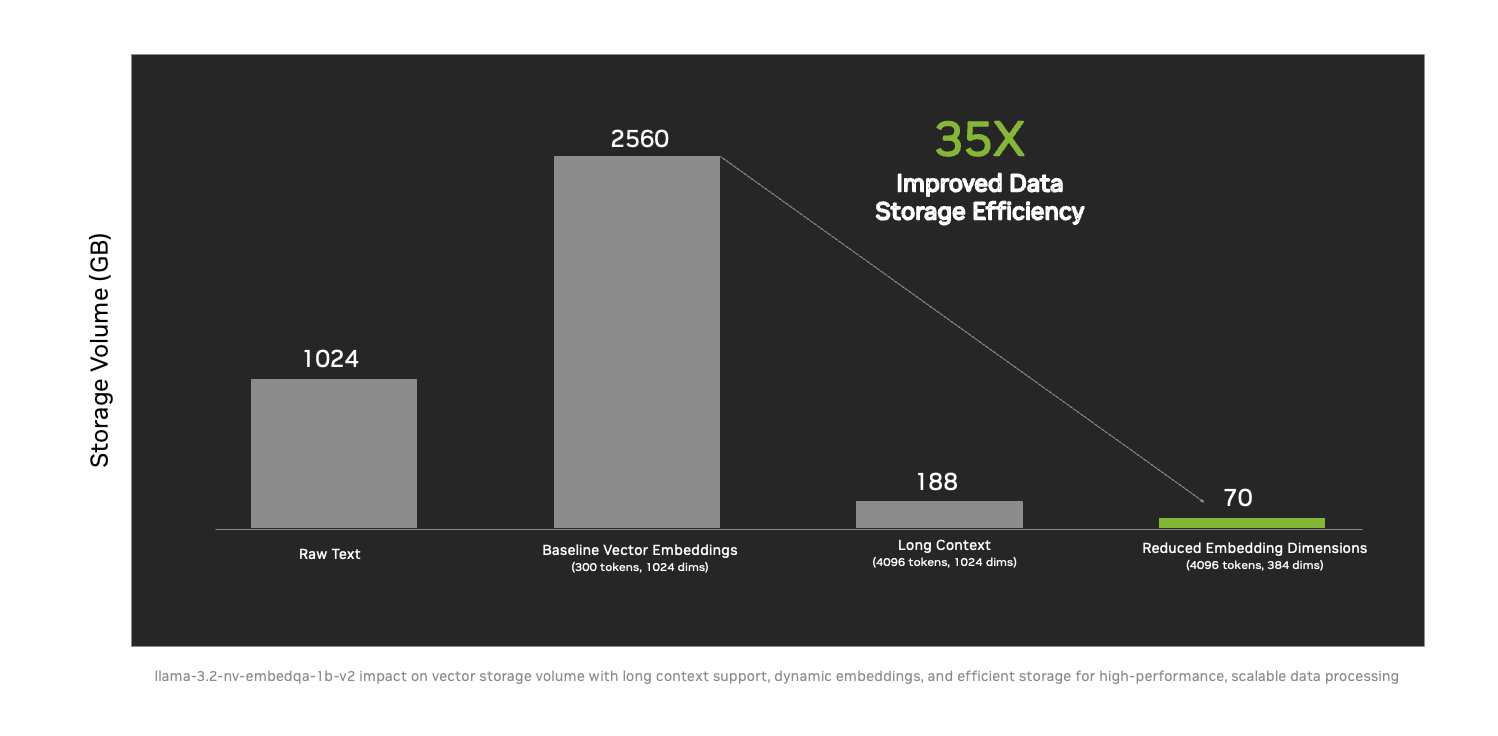
- 通过长上下文支持、动态嵌入大小调整等新技术,数据存储效率提升了 35 倍,进而能够更大规模地提供可操作的智能。
DataStax、Cohesity、Cloudera、Nutanix、SAP、VAST Data 和 WEKA 等 NVIDIA 领先合作伙伴已采用这些微服务,帮助各行各业的企业安全打通定制模型与各种大型数据源。通过使用检索增强生成 (RAG) 技术,NeMo Retriever 使 AI 系统能够访问更丰富、更相关的信息,有效填补了语言和上下文的鸿沟。
Wikidata 将数据处理时间从 30 天缩短至 3 天内
Wikimedia 与 DataStax 共同使用 NeMo Retriever 对 Wikipedia 的内容进行矢量嵌入,为数十亿用户提供服务。矢量嵌入也被称作“矢量化”,是一种将数据转换为 AI 可以处理和理解的格式,以便提炼洞察和推动智能决策的过程。
Wikimedia 使用 NeMo Retriever 嵌入和重排序 NIM 微服务,在 3 天内就将 1000 多万个 Wikidata 条目矢量化为 AI 可处理的格式,而这一过程在过去需要 30 天。这样的 10 倍加速使得对全球最大开源知识图谱之一的可扩展、多语种访问成为可能。
这个开创性的项目保证了数十万个条目的实时更新,每天都有成千上万的贡献者对这些条目进行编辑,为开发者和用户进一步打通了获取全球信息的途径。凭借 Astra DB 的无服务器模型和 NVIDIA AI 技术,DataStax 产品可提供近乎为零的延迟和出色的可扩展性,满足 Wikimedia 社区的动态需求。
DataStax 正在使用 NVIDIA AI Blueprint,并将 NVIDIA NeMo Customizer、Curator、Evaluator 和 Guardrails 微服务集成到 LangFlow AI 代码生成器中,使开发者生态系统能够针对自己的独特用例优化 AI 模型和工作流,帮助企业扩展 AI 应用。
具有语言包容性的 AI 正在对全球企业产生影响
NeMo Retriever 帮助全球企业克服语言和语境障碍,充分释放数据的潜力。通过部署强大的 AI 解决方案,企业可以获得准确、可扩展和具有影响力的结果。
NVIDIA 的平台和咨询合作伙伴在确保企业高效采用和集成生成式 AI 功能(例如全新的多语种 NeMo Retriever 微服务)方面起到了关键作用。他们帮助企业根据自己的特殊需求和资源调整 AI 解决方案,使生成式 AI 变得更易获得和更加有效。这些合作伙伴包括:
- Cloudera 计划扩大 NVIDIA AI 在 Cloudera AI Inference Service 中的集成规模。Cloudera AI Inference 目前已嵌入了 NVIDIA NIM,并将在今后加入 NVIDIA NeMo Retriever,以提高多语种用例的洞察速度和质量。
- Cohesity 推出了业界首款基于生成式 AI 的对话搜索助手,使用备份数据提供富有洞察力的响应。该搜索助手使用 NVIDIA NeMo Retriever 重排序微服务,提高了检索的准确性并显著提升了各种应用的洞察速度和质量。
- SAP 正在使用 NeMo Retriever 的基础功能,为其智能副驾 Joule 的问答功能以及从自定义文档中的信息检索添加上下文。
- VAST Data 正与 NVIDIA 一起在 VAST Data InsightEngine 上部署 NeMo Retriever 微服务,对新数据进行即时分析。这样就可以通过捕捉和组织实时信息加快识别业务洞察,实现 AI 驱动的决策过程。
- WEKA 正在将其 WEKA AI RAG Reference Platform (WARRP) 架构与 NVIDIA NIM 和 NeMo Retriever 集成到其低延迟数据平台,创造出每秒处理数十万个 token 的可扩展多模态 AI 解决方案。
借助多语种信息检索突破语言障碍
多语种信息检索对于企业 AI 满足实际需求来说至关重要。NeMo Retriever 支持针对多语种和跨语种数据集的高效、准确文本检索。它专为搜索、问题解答、摘要和推荐系统等企业用例而设计。
此外,NeMo Retriever 还解决了企业 AI 所面临的一个重大挑战——处理数量庞大的大型文件。借助长上下文支持,这些新的微服务可以处理冗长的合同或详细的医疗记录,而且能够在长时间的交互中保持准确性和一致性。
这些功能有助于企业更有效地使用数据,为员工、客户和用户提供精准、可靠的结果,同时通过优化资源实现可扩展性。NeMo Retriever 等先进的多语种检索工具,可以使 AI 系统在全球化世界中具有更强的适应能力、更易访问和产生更大的影响。
可用性
开发者可以在 NVIDIA API 目录中,或者通过免费的 90 日 NVIDIA AI Enterprise 开发者许可证访问和使用多语种 NeMo Retriever 微服务以及其他适用于信息检索的 NIM 微服务。
进一步了解全新 NeMo Retriever 微服务的更多信息,以及如何使用它们构建高效的信息检索系统。