
从8小时到80秒:NVIDIA作为唯一一家提交了全部6项基准测试的公司,实现了AI训练用时大突破。
“天下武功,唯快不破”,你需要以“快”制胜。
如今,全球顶级公司的研究人员和数据科学家团队们都在致力于创建更为复杂的AI模型。但是,AI模型的创建工作不仅仅是设计模型,还需要对模型进行快速地训练。
这就是为什么说,如果想在AI领域保持领导力,就首先需要有赖于AI基础设施的领导力。而这也正解释了为什么说今日发布的MLPerf AI训练结果如此之重要。
通过完成全部6项MLPerf基准测试,NVIDIA展现出了全球一流的性能表现和多功能性。NVIDIA AI平台在训练性能方面创下了八项记录,其中包括三项大规模整体性能纪录和五项基于每个加速器的性能纪录。
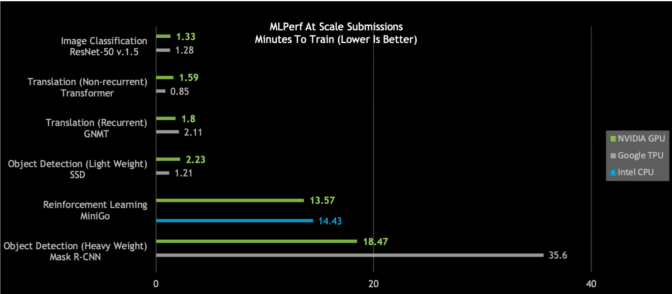
表1:NVIDIA MLPerf AI纪录。
每个加速器的比较基于早前报告的基于单一NVIDIA DGX-2H(16个 V100 GPU)、与其他同规模相比较的MLPerf 0.6的性能(除MiniGo采用的是基于8个V100 GPU的NVIDIA DGX-1 ) |最大规模MLPerf ID:Mask R-CNN:0.6-23,GNMT:0.6-26,MiniGo:0.6-11 |每加速器MLPerf ID:Mask R-CNN,SSD,GNMT,Transformer:全部使用0.6-20,MiniGo:0.6-10
以上测试结果数据由谷歌、英特尔、百度、NVIDIA、以及创建MLPerf AI基准测试的其他数十家顶级技术公司和大学提供背书,能够转化为具有重要意义的创新。
简而言之,NVIDIA的AI平台如今能够在不到两分钟的时间内完成此前需要一个工作日才能完成的模型训练。
各公司都知道,释放生产力是一件重中之重的要务。超级计算机如今已经成为了AI的必备工具,树立AI领域的领导力首先需要强大的AI计算基础设施支持。
NVIDIA最新的MLPerf结果很好地展示了将NVIDIA V100 Tensor核心 GPU应用于超算级基础设施中所能带来的益处。
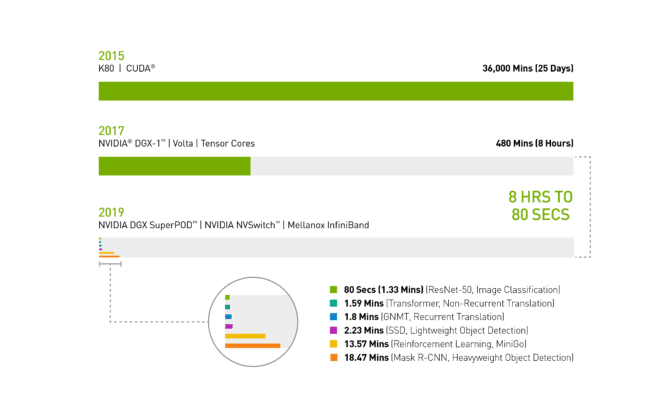
在2017年春季的时候,使用搭载了V100 GPU的NVIDIA DGX-1系统训练图像识别模型ResNet-50,需要花费整整一个工作日(8小时)的时间。
而如今,同样的任务, NVIDIA DGX SuperPOD使用相同的V100 GPU,采用Mellanox InfiniBand进行互联,并借助可用于分布式AI训练的最新NVIDIA优化型AI软件,仅需80秒即可完成。
80秒的时间,甚至都不够用来冲一杯咖啡。
图1:AI时间机器
2019年MLPerf ID(按图表从上到下的顺序):ResNet-50:0.6-30 | Transformer:0.6-28 | GNMT:0.6-14 | SSD:0.6-27 | MiniGo:0.6-11 | Mask R-CNN:0
AI的必备工具:
DGX SuperPOD 能够更快速地完成工作负载
仔细观察今日的MLPerf结果,会发现NVIDIA DGX SuperPOD是唯一在所有六个MLPerf类别中耗时都少于20分钟的AI平台:
图2:DGX SuperPOD打破大规模AI纪录
大规模MLPerf 0.6性能 | 大规模MLPerf ID:RN50 v1.5:0.6-30,0.6-6 | Transformer:0.6-28,0.6-6 | GNMT:0.6-26,0.6-5 | SSD:0.6-27,0.6-6 | MiniGo:0.6-11,0.6-7 | Mask R-CNN:0.6-23,0.6-3
更进一步观察会发现,针对重量级目标检测和强化学习,这些最困难的AI问题,NVIDIA AI平台在总体训练时间方面脱颖而出。
使用Mask R-CNN深度神经网络的重量级目标检测可为用户提供高级实例分割。其用途包括将其与多个数据源(摄像头、传感器、激光雷达、超声波等)相结合,以精确识别并定位特定目标。
这类AI工作负载有助于训练自动驾驶汽车,为其提供行人和其他目标的精确位置。另外,在医疗健康领域,它能够帮助医生在医疗扫描中查找并识别肿瘤。其意义的重要性非同小可。
NVIDIA的“重量级目标检测”用时不到19分钟,性能几乎是第二名的两倍。
强化学习是另一有难度的类别。这种AI方法能够用于训练工厂车间机器人,以简化生产。城市也可以用这种方式来控制交通灯,以减少拥堵。NVIDIA采用NVIDIA DGX SuperPOD,在创纪录的13.57分钟内完成了对MiniGo AI强化训练模型的训练。
咖啡还没好,任务已完成:
即时AI基础设施提供全球领先性能
打破基准测试纪录不是目的,加速创新才是目标。这就是为什么NVIDIA构建的DGX SuperPOD不仅性能强大,而且易于部署。
DGX SuperPOD全面配置了可通过NGC容器注册表免费获取的优化型CUDA-X AI软件,可提供开箱即用的全球领先AI性能。
在这个由130多万名CUDA开发者组成的生态系统中,NVIDIA与开发者们合作,致力于为所有AI框架和开发环境提供有力支持。
我们已经助力优化了数百万行代码,让我们的客户能够将其AI项目落地,无论您身在何处都可以找到NVIDIA GPU,无论是在云端,还是在数据中心,亦或是边缘。
AI基础设施如今有够快
未来会更快
更好的一点在于,这一平台的速度一直在提升。NVIDIA每月都会发布CUDA-X AI软件的新优化和性能改进,集成型软件堆栈可在NGC容器注册表中免费下载,包括容器化的框架、预先训练好的模型和脚本。
借助在CUDA-X AI软件堆栈上的创新,NVIDIA DGX-2H服务器的MLPerf 0.6吞吐量比NVIDIA七个月前发布的结果提升了80%。
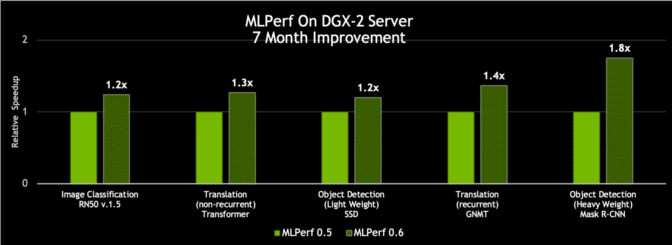
图3:基于同一服务器,性能提升高达80%
对单个历元上单一DGX-2H服务器的吞吐量进行比较(数据集单次通过神经网络)| MLPerf ID 0.5 / 0.6比较:ResNet-50 v1.5: 0.5-20/0.6-30 | Transformer: 0.5-21/0.6-20 | SSD: 0.5-21/0.6-20 | GNMT: 0.5-19/0.6-20 | Mask R-CNN: 0.5-21/0.6-20
所有这些成果结合在一起,其背后所代表的是数百亿美元的投资和努力,这一切都是为了让你能够快速完成工作,而且未来还会更快。