
我们正将人工智能推广至每个计算平台、每个架构、以及人类的每项工作中。
本月,GPU技术大会(GPU Technology Conference)取得了巨大成功,向人工智能的怀疑论者充分证明了该革命性技术势不可挡的力量。
在此次硅谷举行的为期四天的大会里,世界领先的媒体和娱乐、制造、医疗和运输公司的代表们相互分享了GPU计算带来的重大突破。
数字说明了一切。第八届年度GPU技术大会堪称有史以来规模最大的一次盛会,吸引了7000多名与会者和150家参展商,同时召开了600场技术会议。全球前十大科技公司,全球十大汽车制造商,以及100多家专注于人工智能和VR的初创公司悉数到场。
这些数字背后是势不可挡的聚合趋势。计算能力正在推动人工智能飞跃发展,足以抵消摩尔定律的放缓步伐。人工智能开发人员加快构建新的架构,以解决我们当前最大的挑战。他们希望能广泛运行人工智能软件,从功能强大的云服务到云端设备不一而足。
人工智能计算时代 — GPU计算时代

在GPU技术大会上,我们推出了Volta,这是自统一计算设备架构(CUDA)发明以来我们这个时代最大的技术飞跃。它集成了210亿个晶体管,采用12nm NVIDIA优化的TSMC工艺以及三星最快的HBM内存。Volta运行全新数字格式和CUDA指令,可以超高速执行4×4矩阵运算,进行元素级深度学习。
每个Volta GPU都拥有高达120 teraflops的浮点运算能力,我们的DGX-1 AI超级计算机将八台Tesla V100 GPU连接起来,能够实现每秒近千万亿次浮点运算的深度学习性能。
谷歌的 TPU
同样在上周,谷歌在其I/O会议上推出TPU2芯片,其性能可达到45 teraflops。
令人高兴的是,两个领先的人工智能团队虽然互相竞争,但也保持全面的深入合作,例如,调整TensorFlow性能,使用NVIDIA CUDA GPU加速谷歌云计算。人工智能是人类历史上最伟大的技术力量,所有实现人工智能大众化并使其迅速推广的努力都值得称道。
发展动力源自摩尔定律失效
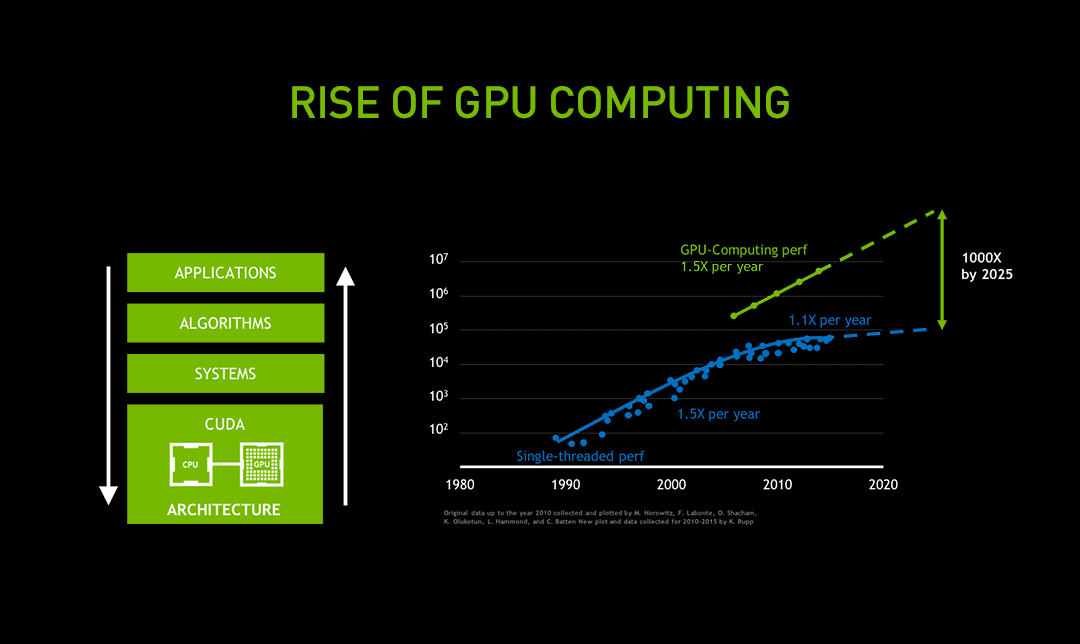
人工智能革命已经到来,尽管摩尔定律融合了Dennard缩放和CPU架构的领先优势,而摩尔定律已在近十年前就开始失效。Dennard缩放通过降低晶体管尺寸和电压,能够使设计者在保持功率密度的同时增加晶体管密度和速度,但现在Dennard缩放遇到了元件物理的瓶颈。
CPU架构师只能获得一定的指令级并行性(ILP),而电路和能耗却已大幅度增加。所以在后摩尔定律时代,CPU晶体管和能耗大幅上升导致应用性能只有小幅增长。最近,其性能每年只增长10%,而过去每年的增幅为50%。
我们开创的加速计算方法针对特定的算法领域;添加专门的处理器来替代CPU;吸引各个行业的开发人员优化我们的架构,并加速自己的应用。我们致力于整个算法、求解器和应用程序栈,消除所有瓶颈,实现光速。
这就是Volta能为人工智能工作负载提供惊人加速的真正原因。它比当前NVIDIA GPU架构Pascal的性能提升了5倍,达到峰值万亿次浮点运算,优于两年前推出的Maxwell架构15倍,远远超过摩尔定律的预测。
加速人工智能的各种方法

性能的长足进展吸引了各个行业的创新者,过去一年,GPU驱动的人工智能服务创业公司数量增加了4倍多,达到1300家。
没人想错过下一个技术突破。Marc Andreessen认为,这是一个软件为王的世界,但人工智能正在主导软件。
在过去两年里,基于GitHub开放源代码软件库支持领先人工智能架构的软件开发人员已从不足5000人增至75,000多人。
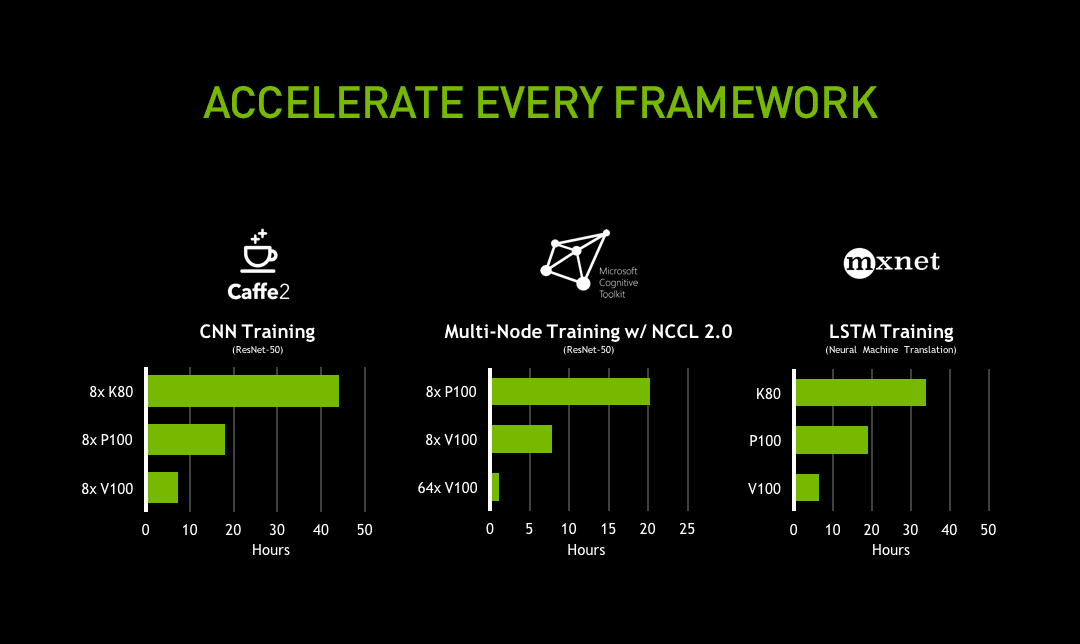
深度学习是各大科技公司的战略重点。它越来越多地渗透到基础构架、工具、产品制造等各个方面。我们与各个架构制造商倾力合作,力求性能尽善尽美。通过优化GPU的每个架构,我们可以将训练一个模型所需的数百次迭代缩短至数小时或数天,从而提高工程师的工作效率。Caffe2、Chainer、Microsoft Cognitive Toolkit、MXNet、PyTorch、TensorFlow等网络都将针对Volta得到精心优化。
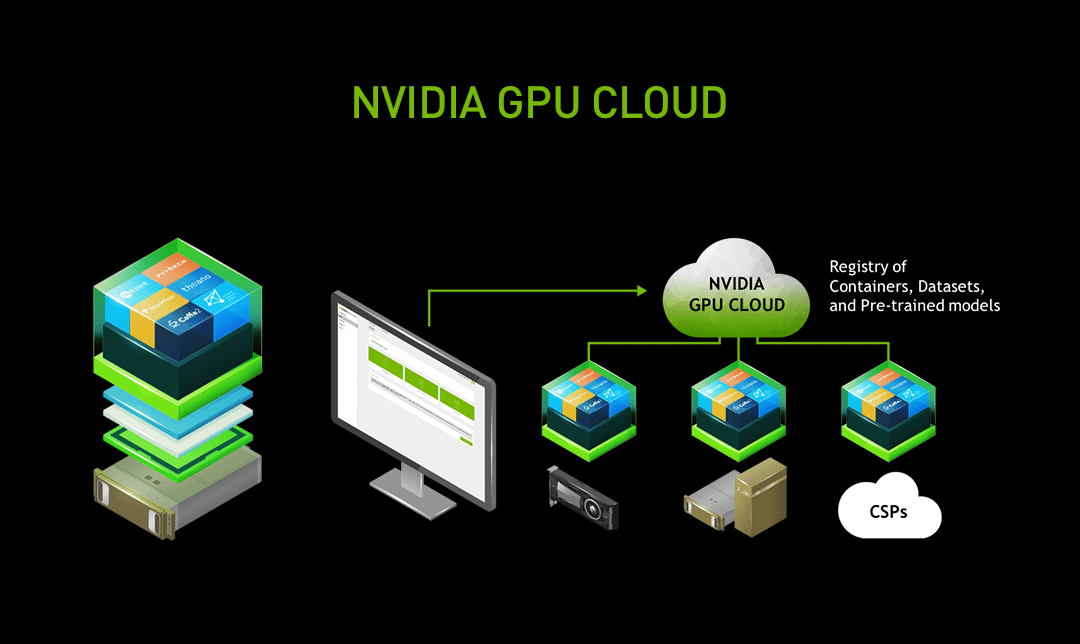
我们希望营造出一种大环境,以帮助开发人员随时随地在任何架构内完成工作。对于希望内部保管数据的企业,我们在GPU技术大会期间特意推出了功能强大的新型工作站和服务器。
眼下,价值2470亿美元的公共云服务市场也许最具活力。阿里巴巴、亚马逊、百度、Facebook、谷歌、IBM、微软和腾讯都已在各自的公有云采用了NVIDIA GPU。
为帮助创新者无缝迁移到云服务,我们在此次GPU技术大会上推出了NVIDIA GPU Cloud云平台,该平台包含每个架构的预配置和优化栈注册表。每一层软件和所有组合都已经过调整、测试和打包,并整体放入NVDocker容器内。我们将不断加强和维护该平台,修复每一个错误;而现在,一切运行良好。
自动化机器的“寒武纪大爆炸”
深度学习的原始数据检测功能为自动化机器——具有人工智能的物联网的“寒武纪大爆炸”创造了条件。未来将有数十亿,甚至数万亿设备由人工智能所驱动。
我们在GPU技术大会上宣布,世界十大公司之一、备受瞩目的丰田汽车公司现已与NVIDIA携手合作开发无人驾驶汽车。
我们还推出了促进机器人制造的虚拟机器人Isaac。今天的机器人都是手动编程,只能按照编程操作。例如,卷积神经网络为我们提供了解决无人驾驶所需的计算机视觉突破,加强学习和模拟学习可能是我们必须攻克的机器人技术难题。

经过训练后,机器人的大脑将下载到我们的人工智能超级计算机Jetson中。机器人可以承受和适应虚拟和现实世界之间的任何差异。新一代机器人诞生了。Isaac在GPU技术大会上演示了如何学会打冰球和高尔夫球。
最后,我们正在实现深度学习加速器(DLA)的开源化——它是NVIDIA版本的专职推理TPU,专为人工智能汽车Xavier超级芯片而打造。我们希望人工智能以最快的速度遍地开花。其他人不再需要投资开发推理式TPU,它将由我们全球最好的芯片设计师设计并免费提供。
助力当今时代的爱因斯坦和达·芬奇
以上种种只是NVIDIA GPU计算如何成为我们这个时代中爱因斯坦和达·芬奇基本工具的最新示例。对于他们来说,我们的发明不亚于一台时间机器。基于3D图形无尽的技术需求和游戏市场规模,NVIDIA已经将GPU发展为计算机大脑,在虚拟现实与人工智能激动人心的交汇点开启创新的大门。