
AI 正在推动新一轮工业革命——这是一场由 AI 工厂驱动的革命。
与传统数据中心不同,AI 工厂不仅仅存储和处理数据,它们还大规模地生产智能,将原始数据转化为实时见解。对于全球各地的企业和各国而言,这意味着价值实现的速度大幅提升,即将 AI 从长期投资转变为实现竞争优势的直接驱动力。目前投资于专门建设 AI 工厂的企业将在创新、效率和市场差异化方面占据领先地位。
传统数据中心面向通用计算,通常处理各种各样的工作负载,而 AI 工厂则经过优化,以便利用 AI 来创造价值。它们涵盖 AI 的整个生命周期,从数据采集到训练、微调,以及最为关键的大规模推理。
对 AI 工厂来说,智能并非副产品,而是主要产品。这种智能通过 AI token 吞吐量来衡量,也就是那些驱动决策、自动化和全新服务的实时预测。
传统数据中心短期内不会消失,但其未来是将演变成 AI 工厂还是连接到 AI 工厂,将取决于企业的商业模式。
无论企业如何选择,NVIDIA 驱动的 AI 工厂已经在大规模地生产智能,正在改变 AI 的构建、优化和部署方式。
驱动计算需求的扩展定律
在过去几年里,AI 领域的热点是训练大模型。但随着近期 AI 推理模型大量涌现,推理已经成为 AI 经济的主要驱动力。三条关键的扩展定律(scaling law)揭示了其中的原因:
- 预训练扩展:更大的数据集和更多的模型参数能够带来可预见的智能水平提升,但这需要在专业技术专家、数据整理和计算资源方面进行大量投入。在过去五年中,预训练扩展使计算需求增长了 5000 万倍。不过,一旦模型训练完成,就会大幅降低其他人在此基础上进行开发的门槛。
- 后训练扩展:针对特定真实应用对 AI 模型进行微调时,在 AI 推理过程中所需的算力是预训练的 30 倍。随着各机构根据自身独特需求而调整现有模型,对 AI 基础设施的累积需求也会急剧飙升。
- 测试时扩展(又称长思考):像代理式 AI 或物理 AI 这类先进的 AI 应用需要进行迭代推理,即模型在做出最佳响应之前会探索多种可能的答案。这个过程所需的算力比传统推理多出 100 倍。
传统数据中心并非为 AI 新时代而设计。AI 工厂则专门进行了优化以持续满足这种巨大的算力需求,为 AI 推理和部署提供了一条理想的发展路径。
用 Token 重塑产业与经济
全球范围内,各国政府与企业都在竞相建设 AI 工厂,以刺激经济增长、促进创新并提升效率。
欧洲高性能计算联合体(EuroHPC JU)近期宣布,计划与 17 个欧盟成员国携手打造 7 座 AI 工厂。
在此之前,全球已掀起 AI 工厂投资热潮,各个企业和国家都在加速利用 AI 驱动各行业、各地区的经济增长:
- 印度:Yotta Data Services 与 NVIDIA 合作推出了 Shakti 云平台,致力于让更多人能够获得先进的 GPU 资源。通过集成 NVIDIA AI Enterprise 软件与开源工具,Yotta 为 AI 开发与部署打造了一个无缝的环境。
- 日本:包括 GMO Internet、Highreso、KDDI、Rutilea 和 SAKURA internet 在内的多家日本领先的云服务提供商,正在构建 NVIDIA 驱动的 AI 基础设施,以推动机器人、汽车、医疗和电信等行业的变革。
- 挪威:Telenor 集团推出了一座基于 NVIDIA 打造的 AI 工厂,目的是在北欧地区加快 AI 应用,重点关注劳动力技能提升与可持续发展。
这些行动充分表明,AI 工厂正在全球范围内迅速成为与电信、能源同样重要的国家基础设施。
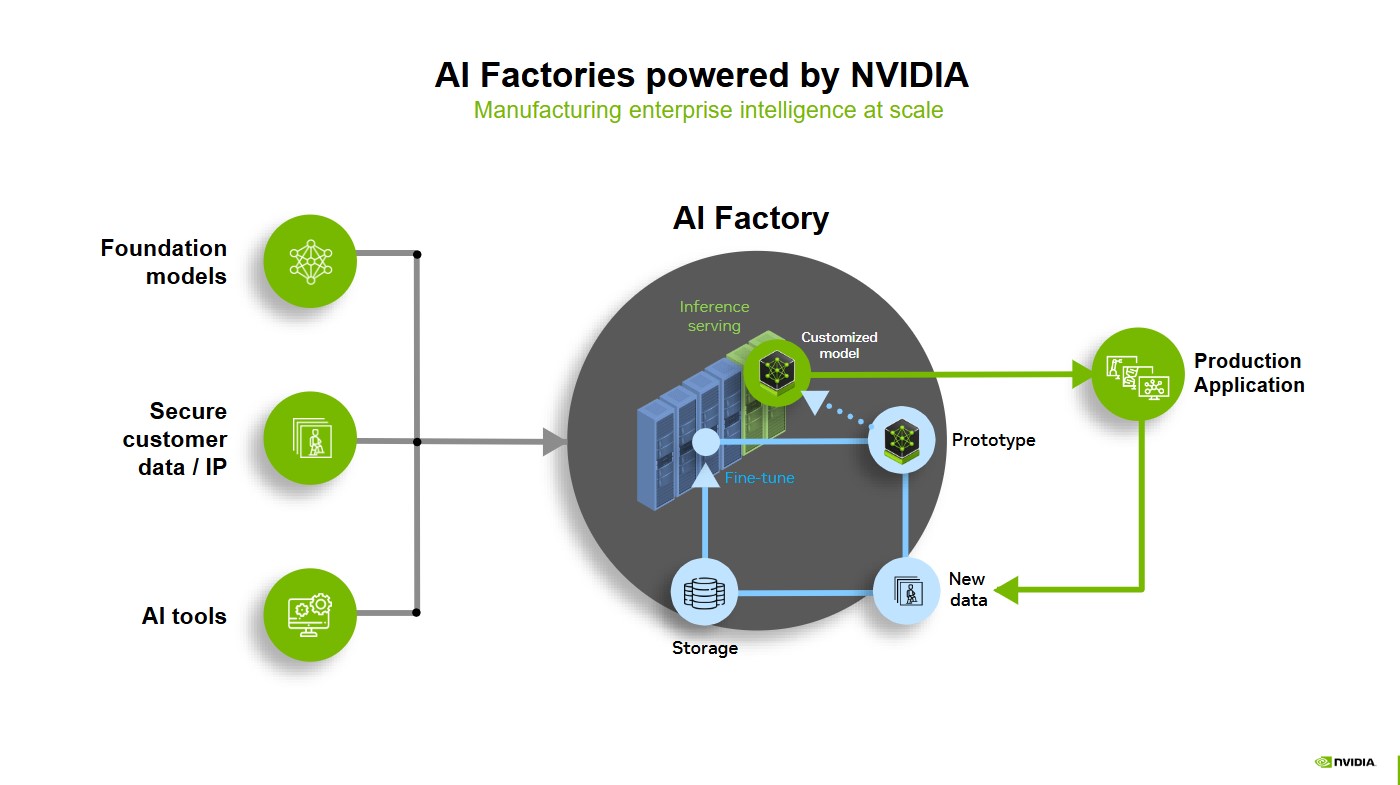
走进 AI 工厂:生产智能的地方
基础模型、安全的客户数据以及 AI 工具就是 AI 工厂的原材料。在 AI 工厂中,推理服务、原型设计和微调塑造出强大的定制化模型,可以随时投入实际应用。
当这些模型被部署到真实的应用场景中时,它们会不断地从新数据中学习。这些新数据通过数据飞轮进行存储、优化,然后再反馈到系统中。这种优化循环确保了 AI 能够持续地适应变化、保持高效并不断改进,以前所未有的规模推动企业智能化发展。
利用全栈 NVIDIA AI 打造 AI 工厂的优势
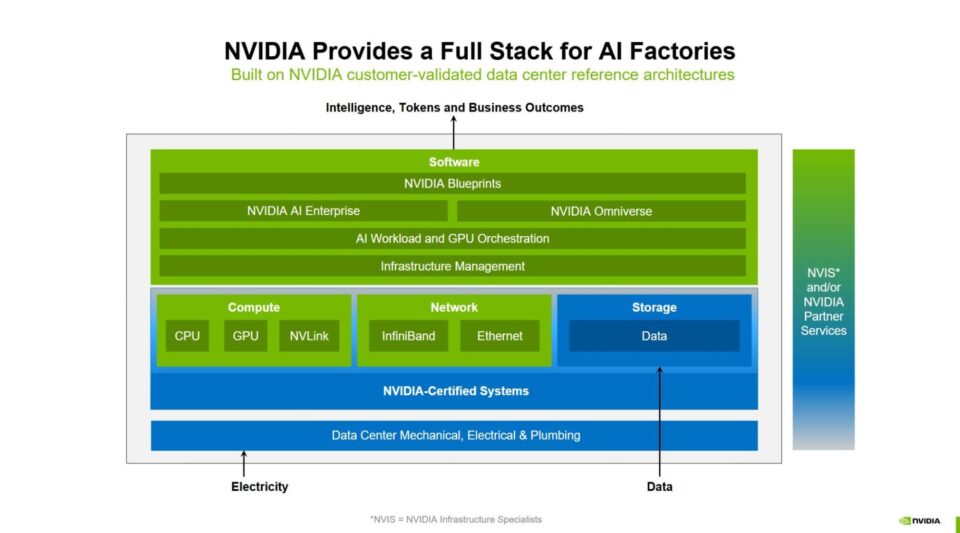
NVIDIA 提供完整、集成的 AI 工厂堆栈,从芯片到软件的每一层都针对大规模训练、微调及推理进行了优化。这种全栈式方法确保企业能够部署经济高效、高性能且面向未来的 AI 工厂,以应对 AI 的指数级增长。
通过生态系统合作伙伴,NVIDIA 打造了全栈 AI 工厂的构建模块,这一全栈方案包括以下模块:
- 强大的计算性能
- 先进的网络
- 基础设施管理和工作负载编排
- 最庞大的 AI 推理生态系统
- 存储和数据平台
- 设计与优化的各种蓝图
- 参考架构
- 适用于各类企业的灵活部署方案
强大的计算性能
任何 AI 工厂的核心都在于其算力。从 NVIDIA Hopper 到 NVIDIA Blackwell,NVIDIA 为这场新的工业革命提供全球最强大的加速计算。借助基于 NVIDIA Blackwell Ultra 的 NVIDIA Grace Blackwell 机架式解决方案,AI 工厂的 AI 推理输出最高可提升 50 倍,树立了效率和规模的新标杆。
NVIDIA DGX SuperPOD 是交钥匙式企业 AI 工厂的典范,聚合了 NVIDIA 加速计算的优势。NVIDIA DGX Cloud 提供的 AI 工厂能在云端提供高性能的 NVIDIA 加速计算。
全球各地的系统合作伙伴正利用 NVIDIA 加速计算技术,为其客户打造全栈 AI 工厂。目前的加速计算平台包括了基于 Blackwell 和 Blackwell Ultra 的 NVIDIA Grace Blackwell 机架式解决方案。
先进的网络
大规模地传输智能需要在整个 AI 工厂堆栈中实现高性能的无缝连接。NVIDIA NVLink 和 NVLink Switch 支持高速的多 GPU 通信,加速节点内部和节点之间的数据传输。
AI 工厂还需要强大的网络骨干。NVIDIA Quantum InfiniBand、NVIDIA Spectrum-X 以太网网络平台和 NVIDIA BlueField 网络平台可减少瓶颈,确保在大规模 GPU 集群上实现高效、高吞吐量的数据交换。这种端到端的集成对于将 AI 工作负载扩展到百万 GPU 级别至关重要,实现了突破性的训练和推理性能。
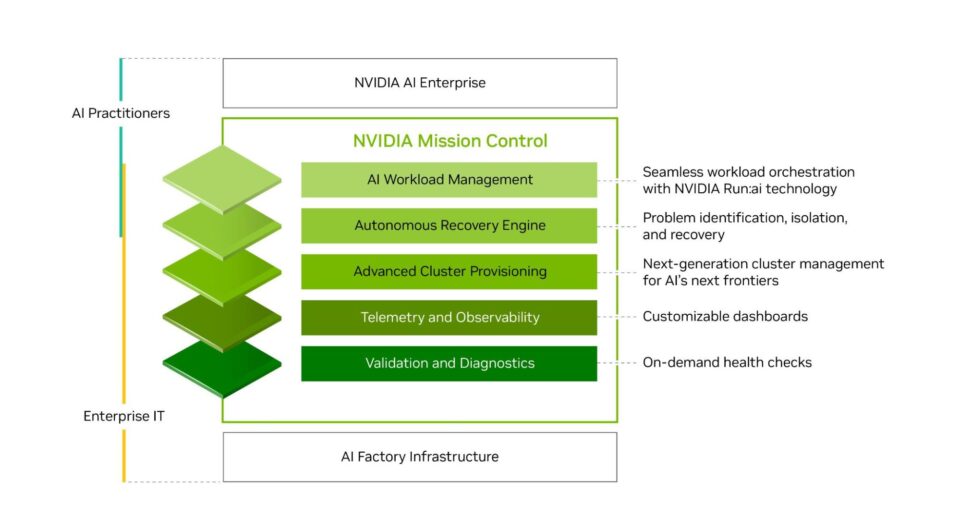
基础设施管理和工作负载编排
企业需要既能利用超大规模云服务提供商那样敏捷、高效且大规模的 AI 基础设施,又无需承担高昂成本、复杂性且具备 IT 专业知识等的负担。
借助 NVIDIA Run:ai,企业能够无缝实现 AI 工作负载编排和 GPU 管理,在加速 AI 实验进程和扩展工作负载的同时,还可以优化资源利用率。NVIDIA Mission Control 软件集成了 NVIDIA Run:ai 技术,优化了从工作负载到基础设施的 AI 工厂运营流程,通过全栈智能实现业界领先的基础设施韧性。
最庞大的 AI 推理生态系统
AI 工厂需要合适的工具才能将数据转化为智能。NVIDIA AI 推理平台(涵盖了 NVIDIA TensorRT 生态系统)、NVIDIA Dynamo 以及 NVIDIA NIM 微服务——这些均已成为或即将成为 NVIDIA AI Enterprise 软件平台的一部分,可提供行业内最全面的 AI 加速库和经过优化的软件套件,同时提供非凡的推理性能、超低延迟以及高吞吐量。
存储和数据平台
数据是 AI 应用的驱动力,但企业数据迅速增长且越来越复杂,常常使得有效利用这些数据的成本过高且耗时过长。为了在 AI 时代蓬勃发展,企业必须充分释放其数据的全部潜力。
NVIDIA AI 数据平台是一个可定制的参考设计,用于为要求苛刻的 AI 推理工作负载构建新型 AI 基础设施。NVIDIA 认证存储合作伙伴正与 NVIDIA 合作,开发定制化的 AI 数据平台,这些平台能够充分利用企业数据,针对复杂的查询进行推理并提供答案。
设计与优化蓝图
为了设计和优化 AI 工厂,团队可以使用用于 AI 工厂设计和运营的 NVIDIA Omniverse Blueprint。它让工程师能够在部署前利用数字孪生技术对 AI 工厂基础设施进行设计、测试和优化。通过降低风险和不确定性,它有助于避免代价高昂的停机,这对于 AI 工厂的运营者来说是一个关键因素。
对于规模达到 1 吉瓦的 AI 工厂而言,停机一天造成的损失可能超过 1 亿美元。通过提前消除复杂性并让 IT、机械、电气、电力和网络工程等团队能够并行工作,用于 AI 工厂设计和运营的 NVIDIA Omniverse Blueprint 加快了部署速度,并确保了运营的韧性。
参考架构
NVIDIA 企业参考架构和 NVIDIA 云合作伙伴参考架构为设计和部署 AI 工厂的合作伙伴提供了路线图。借助包含 NVIDIA AI 软件堆栈的 NVIDIA 认证系统以及合作伙伴生态系统,企业和云服务提供商将能够构建可扩展、高性能且安全的 AI 基础设施。
AI 工厂堆栈的每一层都依赖高效的计算来满足不断增长的 AI 需求。NVIDIA 加速计算是整个堆栈的基础,它提供最高的每瓦性能,确保 AI 工厂保持最高的能效。借助节能的架构和液冷技术,企业在扩展 AI 规模的同时,还能控制能源成本。
适用于各类企业的灵活部署方案
借助 NVIDIA 的全栈技术,企业能够轻松地构建和部署 AI 工厂,使之契合客户偏好的 IT 使用模式和运营需求。
一些机构选择搭建本地 AI 工厂,以便完全掌控数据和性能,而另一些机构则采用云端解决方案,以实现可扩展性和灵活性。许多企业还会从其信赖的全球系统合作伙伴那里购买预集成解决方案,以加快部署进程。

本地部署
NVIDIA DGX SuperPOD 是交钥匙式 AI 工厂基础设施解决方案,为要求最严苛的 AI 训练和推理工作负载提供具有可扩展性能的加速基础设施。它的特点是将 AI 计算、网络架构、存储和 NVIDIA Mission Control 软件进行了优化设计组合,使企业能够在几周内(而非数月)让 AI 工厂投入使用,并且具备一流的正常运行时间、韧性和利用率。
通过 NVIDIA 的全球企业技术合作伙伴生态系统,AI 工厂解决方案也以 NVIDIA 认证系统的形式提供。这些合作伙伴提供领先的硬件和软件技术,结合数据中心系统专业知识和液冷创新技术,帮助企业降低 AI 项目的风险,并更快地从 AI 工厂投资中获得回报。
这些全球系统合作伙伴正在基于 NVIDIA 参考架构提供全栈解决方案,将 NVIDIA 加速计算、高性能网络和 AI 软件集成在一起,帮助其客户成功地部署 AI 工厂并大规模地生产智能。
云端部署
对于希望采用云端 AI 工厂解决方案的企业,NVIDIA DGX Cloud 在领先的云上提供了一个统一的平台,用于构建、定制和部署 AI 应用。DGX Cloud 的每一层都进行了优化并由 NVIDIA 全面管理,它具备 NVIDIA AI 在云端的优势,并依托领先的云服务提供商构提供企业级软件和构建大规模的连续集群,尤其适合为要求最严苛的 AI 训练工作负载提供可扩展的计算资源。
DGX Cloud 还包括一个动态、可扩展的无服务器推理平台,该平台在混合云和多云环境中提供极高的 AI token 吞吐量,显著降低了基础设施的复杂性和运营开销。
通过提供一个集成了硬件、软件、生态系统合作伙伴和参考架构的全栈平台,NVIDIA 正在帮助企业构建经济高效、可扩展、高性能的 AI 工厂,使其有能力迎接下一次工业革命。
有关 NVIDIA AI 工厂的更多信息。
有关软件产品信息,请查阅相关服务条款。