
一次医疗领域的诊断洞察、一次互动游戏中角色的对话、一次来自客服代理的自主解决方案——这些由 AI 驱动的交互,皆基于同一智能单元:一个 token。
要扩展这些 AI 交互,企业需要考虑是否能够承担更多 token 成本。答案在于更优的 Token 经济学(tokenomics)——其核心在于降低每个 token 的成本。这种下降趋势正在各行各业中显现。
近期麻省理工学院研究发现,基础设施与算法效率的提升使前沿水平性能的推理成本正逐年降低至原来的 1/10。
要理解基础设施效率如何提升 tokenomics,可以把它类比为一台高速印刷机。如果这台印刷机只需在油墨、能源和设备本身上进行小幅追加投资,就能实现 10 倍的产出,那么每页印刷成本自然会下降。同理,对 AI 基础设施的投资如果能带来远超预期的 token 产出,就会显著降低每个 token 的成本。
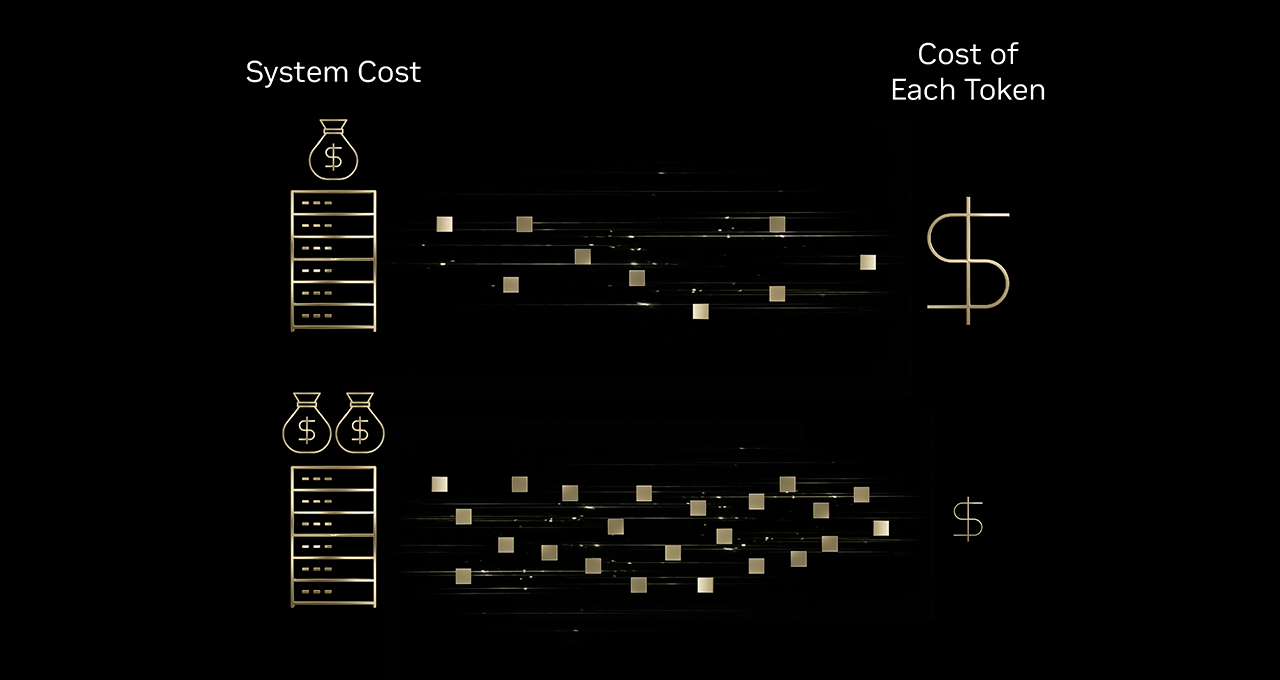
正因如此,包括 Baseten、DeepInfra、Fireworks AI 和 Together AI 在内的领先推理服务提供商纷纷采用 NVIDIA Blackwell 平台。Blackwell 平台帮助这些企业将每个 token 的成本最多可降至 NVIDIA Hopper 平台的 1/10。
这些提供商托管着先进的开源模型,其智能水平现已达前沿级别。通过融合开源的前沿智能、NVIDIA Blackwell 极致的软硬件协同设计以及自主优化的推理堆栈,这些服务商正助力各行各业的企业实现 token 成本的大幅降低。
医疗领域——Baseten 与 Sully.ai 将 AI 推理成本降低 9 成
在医疗领域,诸如医疗编码、病历记录和保险表格管理等繁琐耗时的任务,会占用医生与患者交流的时间。
Sully.ai 通过开发能够处理医疗编码和记录笔记等常规任务的”AI 员工”来解决这一问题。随着公司平台规模扩大,其自有的闭源模型面临着三大瓶颈:实时临床工作流程中的延迟不可预测、推理成本增长速度比收入增长更快,以及对模型质量和更新的控制不足。
为突破这些瓶颈,Sully.ai 采用了 Baseten 的模型 API,该 API 可在 NVIDIA Blackwell GPU 上部署 gpt-oss-120b 等开源模型。Baseten 采用低精度 NVFP4 数据格式、NVIDIA TensorRT-LLM 库及 NVIDIA Dynamo 推理框架以实现优化的推理。该公司选择 NVIDIA Blackwell 运行 Model API,因其每美元投入的吞吐量较 NVIDIA Hopper 平台提升 2.5 倍。
结果显示,Sully.ai 的推理成本因此降低了 90%,成本降低至原来的闭源实现方案的 1/10。同时在病历生成等关键工作流的响应速度提升了 65%。该公司已为医生节省了超过 3000 万分钟的时间,这些时间原本耗费在数据录入及其他手动操作上。
游戏领域——DeepInfra 与 Latitude 将每 token 成本降至原来的 1/4
Latitude 正通过其 AI 冒险故事游戏 AI Dungeon 及即将推出的 AI 驱动角色扮演游戏平台 Voyage,打造 AI 原生游戏的未来。玩家可在这些平台中自由创建或探索世界,选择任何行动,书写专属故事。
该公司的平台采用大型语言模型响应玩家操作——但这带来了扩展难题,因为每次玩家操作都会触发推理请求。成本随玩家参与度增长而攀升,而响应速度必须保持足够快才能确保游戏体验的流畅性。

Latitude 运行的大型开源模型基于由 NVIDIA Blackwell GPU 和 TensorRT-LLM 驱动的 DeepInfra 推理平台。对于大规模混合专家模型(MoE),DeepInfra 将每百万 token 的成本从 NVIDIA Hopper 平台的 0.20 美元降至 Blackwell 平台的 0.10 美元。通过迁移至 Blackwell 原生低精度 NVFP4 格式,其成本进一步降至每百万 token 0.05 美元——现每 token 成本降至之前的 1/4,同时保持了客户期望的准确性。
在 DeepInfra 基于 Blackwell 的平台上运行这些大型 MoE 模型,使 Latitude 能够以经济高效的方式提供快速可靠的响应。DeepInfra 的推理平台在保证性能的同时,还能稳定应对流量峰值,让 Latitude 得以部署更强大的模型而不影响玩家体验。
智能体聊天代理——Fireworks AI 与 Sentient Foundation 合作,将 AI 成本降低高达 50%
Sentient Labs 致力于汇聚 AI 开发者,共同构建强大的开源推理 AI 系统。其目标是通过在安全自主性、智能体架构和持续学习领域开展研究,加速 AI 解决更复杂的推理难题。
Sentient Labs 的首款应用 Sentient Chat 能够编排复杂的多智能体工作流,并整合来自社区的十余个专业 AI 智能体。正因如此,Sentient Chat 面临着巨大的计算需求——单个用户查询可能触发一系列自主交互,通常会导致高昂的基础设施开销。
为应对这种规模和复杂性任务,Sentient 采用基于 NVIDIA Blackwell 运行的 Fireworks AI 推理平台。借助 Fireworks 针对 Blackwell 优化的推理堆栈,Sentient 的成本效率相比之前基于 Hopper 的部署方案提升了 25% 到 50%。
更高的每 GPU 吞吐量使该公司能够以相同成本服务更多并发用户。该平台的可扩展性支持了病毒式传播的用户增长——24 小时内新增 180 万候补用户,单周处理 560 万次查询,同时保持了稳定的低延迟表现。
客户服务——Together AI 与 Decagon 实现成本降至原来的 1/6
使用语音 AI 的客服服务通话往往令人感到挫败,因为哪怕是轻微的延迟都可能导致用户打断语音助手、挂断电话或失去信任。
Decagon 为企业客户支持构建 AI 智能体,其中 AI 驱动的语音服务要求最为苛刻。Decagon 需要一套能够在不可预测的流量负载下实现亚秒级响应的基础设施,并具备支持全天候语音部署的 tokenomics。

Together AI 在 NVIDIA Blackwell GPU 上为 Decagon 的多模型语音技术栈运行生产级推理。两家公司在多项关键优化上展开合作:采用推测解码技术,通过训练小型模型实现更快的响应速度,同时在后台由大模型验证准确性;缓存重复对话元素以加速响应;构建自动扩展机制,在应对流量激增时保持性能稳定。
Decagon 即使在每条查询处理数千个 token 的情况下,也能实现低于 400 毫秒的响应时间。与使用闭源专有模型相比,每条查询的成本(即完成一次语音交互的总成本)降低至原来的 1/6。这一成果得益于 Decagon 的多模型方案(部分采用开源模型,部分在 NVIDIA GPU 上自主训练)、NVIDIA Blackwell 芯片的极致协同设计以及 Together 平台的优化推理堆栈的协同作用。
通过极致协同设计优化 tokenomics
在医疗、游戏和客户服务等领域取得的显著成本节省,得益于 NVIDIA Blackwell 的高性能。NVIDIA Grace Blackwell 机架式解决方案进一步扩大了这一优势,其推理 MoE 模型的每 token 成本降至 NVIDIA Hopper 的 1/10,实现了成本的突破性降低。
NVIDIA 涵盖了计算、网络和软件等跨各个层级堆栈的极致协同设计,以及其合作伙伴生态系统,正在大幅度降低每 token 成本。
这一势头延续至 NVIDIA Rubin 平台上——通过将六款全新芯片集成于一台 AI 超级计算机中,其性能较 Blackwell 提升 10 倍,token 成本降至 Blackwell 的 1/10。
探索 NVIDIA 的全栈推理平台,深入了解其如何为 AI 推理提供更优的 tokenomics。