文章摘要:新的加速计算库在数据处理、生成式 AI、推荐系统、AI 数据策管、数据处理、6G 研究、AI 物理学等方面提供了数量级的加速,并降低了能耗与成本,包括:
- LLM 应用:用于创建自定义数据集的 NeMo Curator,增加了图像策管功能和用于生成高质量合成数据的 Nemotron-4 340B。
- 数据处理:用于矢量搜索的 cuVS 可将建立索引的时间从原来的数日缩短至数分钟;新的 Polars GPU 引擎已进入开放测试阶段。
- 物理 AI:Warp 利用新的 TIle API 加快了物理仿真的计算速度;Aerial 为无线网络仿真添加了更多用于光线追踪和仿真的地图格式;Sionna 为链路级无线仿真添加了新的实时推理工具链。
越来越多的全球企业开始采用 NVIDIA 加速计算技术,来加速其最初仅在 CPU 上运行的应用,实现了极快的运行速度和惊人的节能效果。
位于休斯敦的 CPFD 是一家专为工业应用开发计算流体动力学仿真软件的公司,其产品包括帮助设计下一代回收设施的 Barracuda Virtual Reactor 软件等。塑料回收设施可在 NVIDIA 加速计算驱动的云实例中运行 CPFD 的软件。借助由 CUDA GPU 提供加速的虚拟机,这些软件可以高效扩展和运行仿真,比使用基于 CPU 的工作站快 400 倍、节能 140 倍。

某常用的视频会议应用每小时可为数十万场虚拟会议生成字幕。在使用 CPU 创建实时字幕时,该应用每秒可查询 Transformer 驱动的 AI 语音识别模型三次。而在迁移到云端 GPU 后,该应用的吞吐量增加至每秒 200 次查询,速度提高了 66 倍,能效提高了 25 倍。
某电子商务网站每天通过由深度学习模型驱动的高级推荐系统,连接全球数亿消费者与他们需要的产品。这套系统目前在 NVIDIA 加速云计算系统上运行。在从 CPU 迁移到云端 GPU 上后,该网站的延迟大大降低,速度和能效分别是原来的 33 倍和近 12 倍。
伴随着数据的指数级增长,云端加速计算将带来更多的创新应用场景。
基于 CUDA GPU 的 NVIDIA 加速计算是可持续计算
根据 NVIDIA 估算,假如目前仍在 CPU 服务器上运行的所有 AI、高性能计算和数据分析工作负载均切换到使用 CUDA GPU 加速,那么数据中心每年将节省 40 太瓦时的能源,相当于近 500 万个美国家庭的用电需求。
加速计算利用 CUDA GPU 的并行处理能力,其工作速度比 CPU 提高了数个数量级,在提高生产力的同时,大幅降低了成本和能耗。
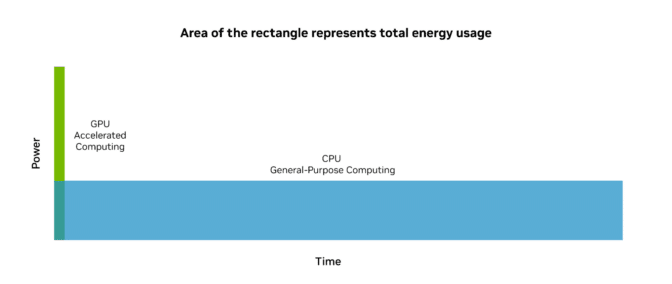
虽然在只有 CPU 服务器中添加 GPU 会增加峰值功率,但 GPU 加速可以快速完成任务,然后进入低功耗状态。GPU 加速计算的总能耗远低于通用 CPU,并且性能卓越。
在过去十年中,NVIDIA AI 计算处理大语言模型的能效提升了约 10 万倍。可见,假如汽车的能效提升幅度与 NVIDIA 加速计算平台上的 AI 能效提升幅度相当,那么汽车每消耗一加仑汽油,就可以行驶 50 万英里,这意味着你可以用不到 1 加仑的汽油开车到月球。
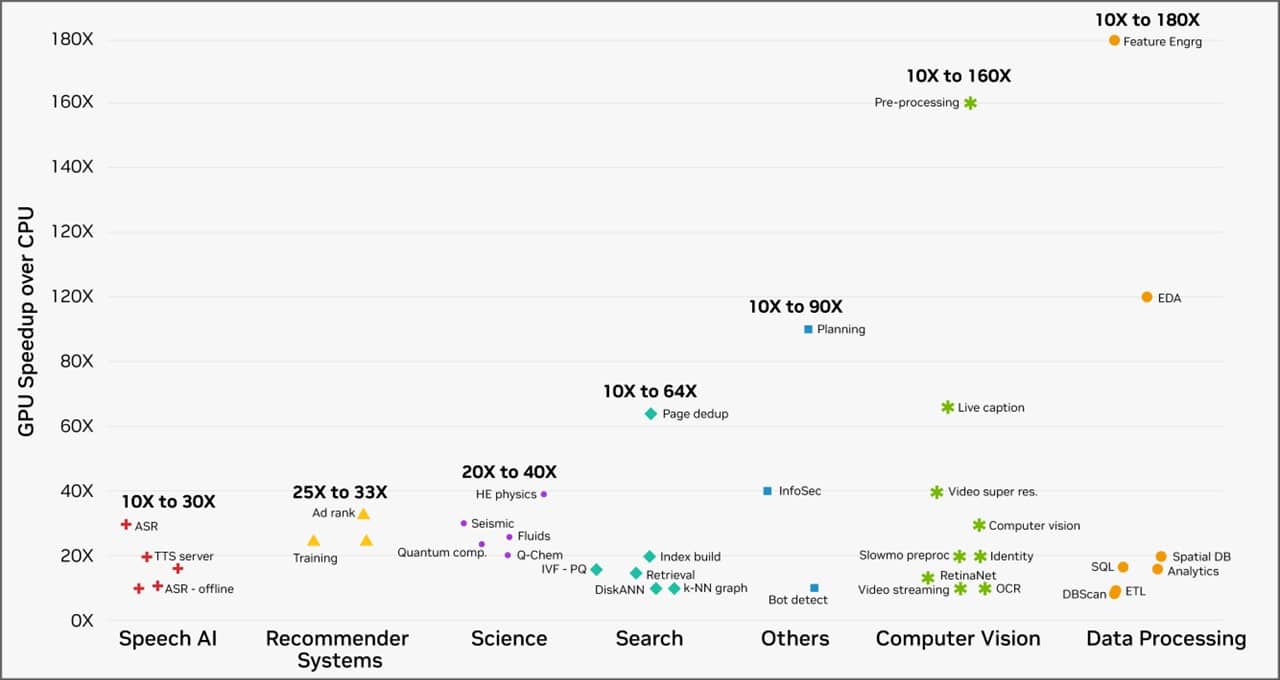
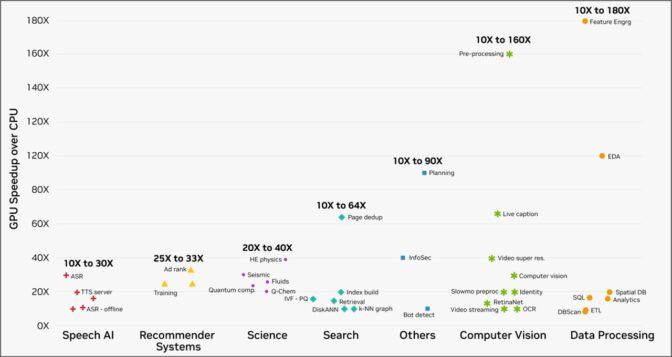
除了大幅提升 AI 工作负载的效率外,GPU 计算的速度也远快于 CPU。如下图所示,当 NVIDIA 加速计算平台的客户在云服务提供商上运行工作负载时,无论是数据处理还是计算机视觉,各种实际任务的速度均是原来的 10-180 倍。
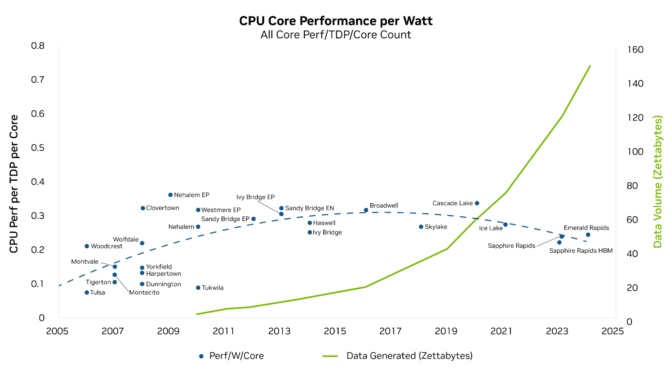
由于工作负载对算力的需求仍在呈指数级增长,而 CPU 一直在努力提供必要的性能,因此性能差距变得越来越大,“计算通胀”的速度也在加快。下图描绘了多年来数据增长幅度远超 CPU 每瓦计算性能增长幅度的趋势。
GPU 加速节省了原本将被浪费的成本和能效。
由于能够大幅减少能耗,加速计算是一种可持续的计算。
为每种工作提供合适的工具
GPU 无法加速为通用 CPU 编写的软件。专门的工作负载需要专门的算法软件库提供加速。如同机械师有一个从螺丝刀到扳手应有尽有的全套工具箱,来应对不同的任务,NVIDIA 也提供了多种不同的库来执行数据解析和计算等底层功能。
每个 NVIDIA CUDA 库都经过优化,以利用 NVIDIA GPU 特有的硬件功能。这些库组合在一起可发挥出 NVIDIA 平台的强大力量。
CUDA 平台路线图还将继续添加新的更新,扩展到各种用例:
LLM 应用
NeMo Curator 使开发者能够在大语言模型(LLM)用例中快速、灵活地创建自定义数据集。最近,我们宣布将功能扩展到文本之外的多模态支持,包括图像策管。
SDG(合成数据生成)利用高质量的合成数据来增强现有数据集,以定制和微调模型与 LLM 应用。我们发布的 Nemotron-4 340B 是一套专为 SDG 构建的新模型,使企业和开发者能够使用模型输出结果并构建自定义模型。
数据处理应用
cuVS 是一个用于 GPU 加速矢量搜索和聚类的开源库,能够为 LLM 和语义搜索带来惊人的速度和效率。最新的 cuVS 可将大型索引的创建时间从数日缩短至数小时,并实现对索引进行大规模搜索。
Polars 是一个利用查询优化和其他技术,在单台机器上高效处理数亿行数据的开源库。由 NVIDIA cuDF 库驱动的全新 Polars GPU 引擎将在开放测试版本中提供。与 CPU 相比,它提供了高达 10 倍的性能提升,为数据从业人员及其应用带来了加速计算的节能效果。
物理 AI
Warp 用于高性能 GPU 仿真和图形,帮助加速空间计算,使物理仿真、感知、机器人和几何处理的可微分程序的编写变得更加容易。Warp 的下一个版本将支持新的 Tile API,使开发者能够使用 GPU 内的 Tensor Core 来进行矩阵和傅立叶计算。
Aerial 是一套包含 Aerial CUDA 加速 RAN 和 Aerial Omniverse 数字孪生的加速计算平台,可用于设计、模拟和运行适用于商业应用与行业研究的无线网络。Aeria 的下一个版本将加入新的扩展,通过更多的地图格式提高光线追踪和仿真的精度。
Sionna 是一个适用于无线和光通信系统链路级仿真的 GPU 加速开源库。借助 GPU,Sionna 的模拟速度加快了多个数量级,实现了对这些系统的交互探索,为下一代物理层研究铺平了道路。Sionna 的下一个版本将加入设计、训练和评估基于神经网络的接收器所需的整个工具链,包括使用 NVIDIA TensorRT 对此类神经接收器进行实时推理支持。
NVIDIA 提供共计超过 400 个库。其中一些库(如 CV-CUDA)擅长用户生成视频、推荐系统、地图绘制和视频会议中常见的计算机视觉任务的预处理和后处理。还有一些库(如 cuDF)可加速数据科学中 SQL 数据库和 pandas 的核心数据框架与表格。
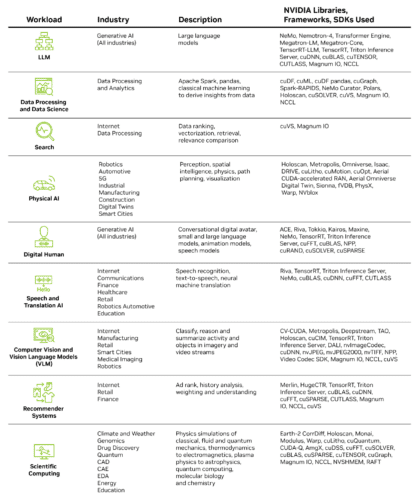
这些库中有许多是通用库,例如适用于多种工作负载的线性代数加速库 cuBLAS;而有些则是专注于特定用例的高度专门化库,例如用于芯片计算光刻技术的 cuLitho。
如果研究者不想使用 NVIDIA CUDA-X 库构建自己的管线,NVIDIA NIM 也能通过将多个库和 AI 模型打包进优化的容器中,为这些研究者提供一条简化的生产部署路径。这种容器化的微服务具有更高的开箱即用吞吐量。
增强这些库性能的是不断增加的基于硬件的加速功能,这些功能能以最高的能效提供加速。例如 NVIDIA Blackwell 平台包含一个解压缩引擎,该引擎的内联数据文件解压缩速度最高可达到 CPU 的 18 倍。这大大加快了数据处理应用的速度,这些应用需要频繁访问存储系统中的压缩文件(如 SQL、Apache Spark 和 pandas 等),并将这些文件解压缩以用于计算运行时。
将 NVIDIA 专门的 CUDA GPU 加速库集成到云计算平台中,可在各种工作负载下提供出色的速度和能效。这一组合能够为企业节省大量成本,并且在推动可持续计算方面起到至关重要的作用,帮助数十亿依赖云工作负载的用户从更加经济、可持续的数字生态系统中获益。
进一步了解 NVIDIA 在可持续计算方面的工作,并使用能效计算器,发现潜在的节能减排空间。
参见有关软件产品信息的公告。