
各项结果都表明,一个节能计算的新时代正在到来。
在真实工作负载测试中,NVIDIA Grace CPU超级芯片在相同的功率范围内运行主流数据中心CPU应用的性能比X86处理器提高了2倍,这将带来许多新的可能性。
这意味着数据中心可以处理两倍的峰值流量并减少多达一半的电费。它们还可以在空间有限的网络边缘实现更大的性能,甚至可以同时实现上述优势。
节能已成为数据中心的优先事项
数据中心经理需要依靠这些方案在当今这个节能时代中快速发展。
摩尔定律实际上已经过时。物理学不再允许工程师在保持空间和功耗不变的情况下加入更多的晶体管。
这就是为什么新一代 X86 CPU 的性能提升相比前一代产品还不到30%” ,这也是为什么越来越多的数据中心设置了功率上限。
再加上全球气候变暖的威胁,数据中心电力供应已经没有增容的余地,但它们仍然需要满足不断增长的算力需求。
在保持功率不变的情况下提高性能
麦肯锡的一项研究显示,美国的计算需求每年增长10%,并将在2022至2030年的八年内翻倍。
麦肯锡表示:“因此,确保数据中心可持续性的压力很大,一些监管机构和政府正在对新建的数据中心推行可持续性标准。”
根据麦肯锡所引用的一项调查,随着摩尔定律的终结,数据中心在计算效率上的进展已停滞不前(见下图)。
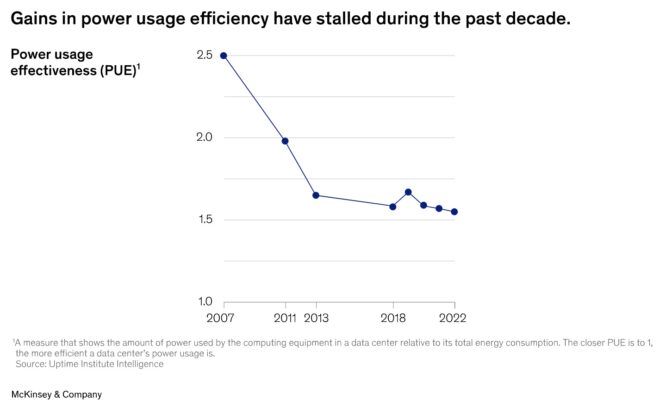
在当今的环境下,NVIDIA Grace所实现的2倍提升等于实现了惊人的多代飞跃,符合当今数据中心高管的需求。
全球服务商Equinix管理着240多座数据中心。该公司的边缘基础设施负责人Zac Smith在一篇关于节能计算的文章中描述了这些需求。
“我们需要在减少碳排放的前提下提高性能。”
“我们有1万家客户指望我们在这个过程中提供帮助。他们需要更多的数据和更高的智能化水平,而且往往要求使用AI。另外,他们希望以可持续的方式来实现这一目标。”
三项CPU创新
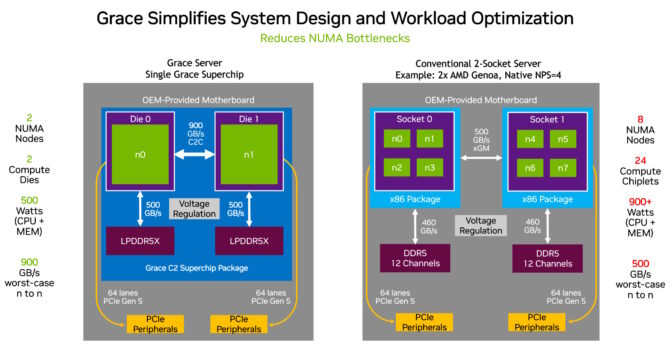
得益于三项创新,Grace CPU提供了高效性能。
它在一块对分带宽(一项吞吐量指标)为3.2 TB/s的裸芯片中使用一种超快的结构将72个Arm Neoverse V2核心连接在一起,然后使用NVIDIA NVLink-C2C互连技术在一个超级芯片封装中连接其中的两块裸片,实现900GB/s的带宽。
最后,它是第一个使用服务器级LPDDR5X内存的数据中心CPU。这帮助它在成本相仿的情况下增加了高达50%的内存带宽,且功耗只有常规服务器内存的八分之一。紧凑的尺寸使其密度比典型的卡式内存设计增加了2倍。
首批结果揭晓
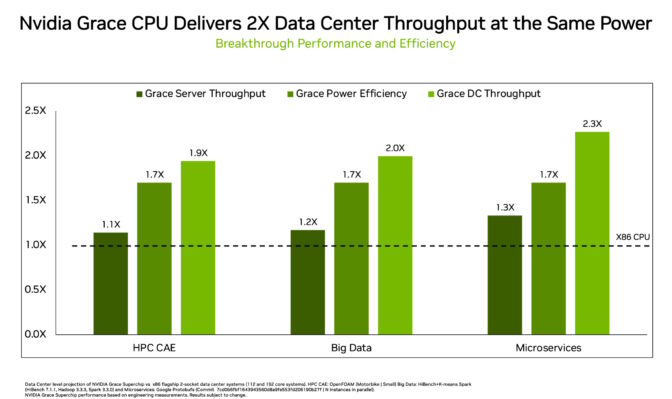
现今,NVIDIA工程师在Grace上运行了真实的数据中心工作负载。
他们发现,在相同的功率下,相比数据中心现有的x86 CPU,Grace更具优势:
- 运行微服务的速度快2.3倍
- 内存密集型数据处理性能快2倍
- 在多个技术计算应用上运行流体力学计算工作时,速度快1.9倍。
如下图所示,数据中心通常需要等到两代或两代以上的CPU才能获得以上优势。
甚至在这些CPU工作结果出炉之前,用户就对Grace的创新做出了反应。
美国洛斯阿拉莫斯国家实验室在5月宣布将在Venado中使用Grace。这台10 EXAFLOP AI超级计算机将推动该实验室在材料科学和可再生能源等领域的工作。同时,欧洲和亚洲的数据中心正在评估Grace的工作负载。
NVIDIA Grace目前正在提供样品,将在下半年投入生产。华硕、Atos、技嘉、慧与、高通、超微、纬创和ZT Systems正在建造使用该产品的服务器。
深入了解可持续计算
想要深入了解细节,请阅读这份关于Grace架构的白皮书。
在NVIDIA GTC的在端到端AI时代最大程度地提高企业机构可持续性和成功的三个策略分会上进一步了解可持续计算。
阅读有关NVIDIA BlueField DPU的白皮书,了解如何构建节能型网络。