
编者注:本文是 Nemotron Labs 系列博客文章,探讨最新的开放模型、数据集和训练技术如何帮助企业在 NVIDIA 平台上构建专用的 AI 系统和应用。每篇文章都强调了在生产中使用开放堆栈来提供价值的实际方法,涵盖了从透明的研究 Copilot 到可扩展的 AI 智能体等领域。
截至 2026 年初,开源项目 OpenClaw 已成为一种现象级应用。今年 1 月,随着开发者兴趣的激增,其 GitHub 星标数突破了 10 万。据社区数据看板和流量分析显示,其单周访问量超过 200 万。截至 3 月,OpenClaw 的星标数量已超过 25 万,仅 60 天就超越 React,成为 GitHub 上星标数第一的软件项目。
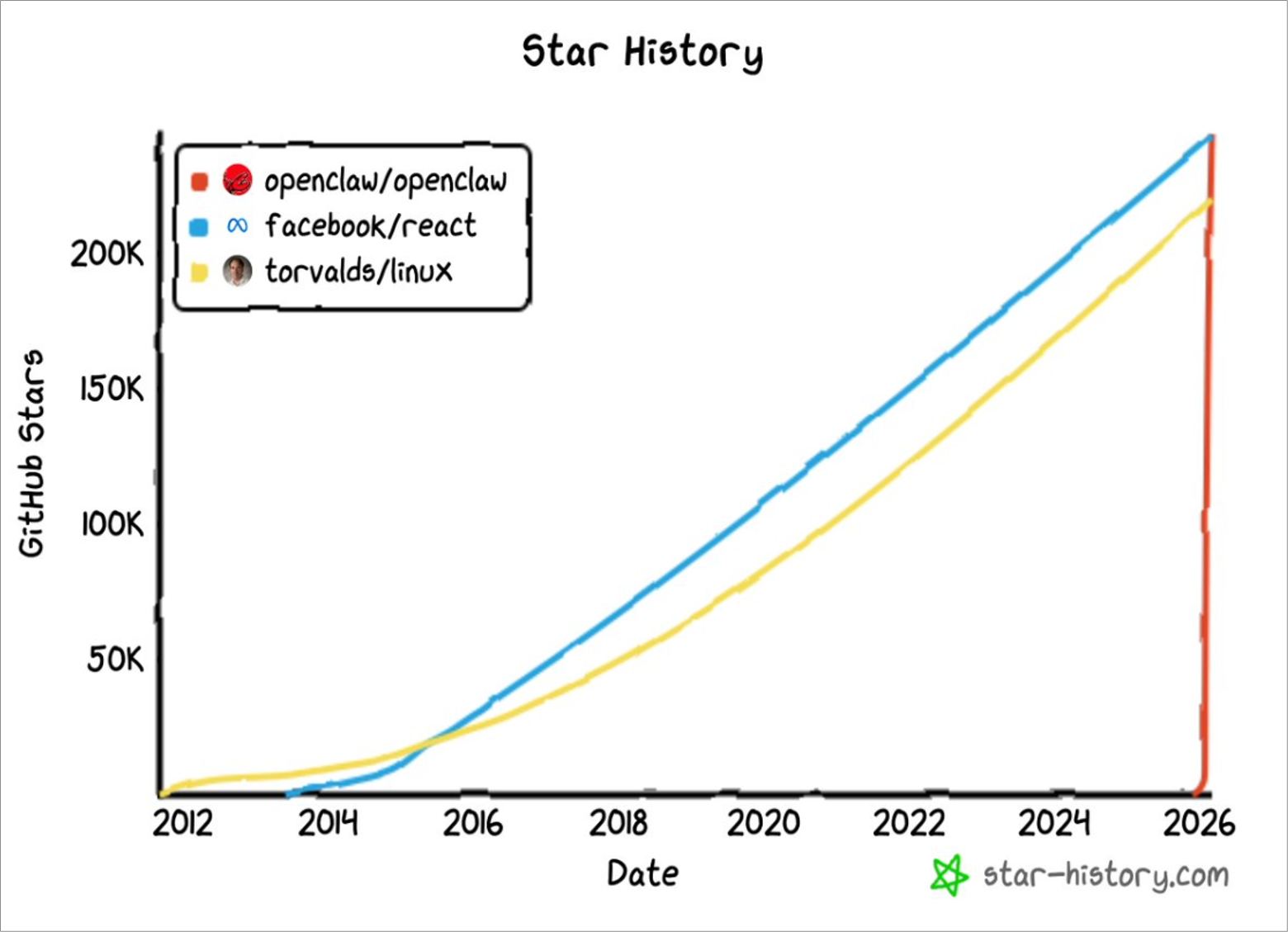
由 Peter Steinberger 创建的 OpenClaw,是一款自托管的持久性 AI 助手,专为在本地或私有服务器上运行而设计。该项目因其可达性和不受限制的自主性而受到关注:用户可以在本地部署 AI 模型,而无需依赖云基础设施或外部应用程序编程接口 (API)。
如今的大多数 AI 智能体都由提示词 (Prompt) 触发,完成特定任务后便停止运行。而长时间运行的自主智能体 (或称为 “Claw”) 的工作方式则不同。这些智能体在后台持续运行,自主完成任务,仅在需要人类决策时才进行提示。它们基于“心跳”机制运行:定期检查任务列表,评估需要如何操作,然后执行或等待下一个周期。
OpenClaw 的迅速普及也引发了争议。安全研究人员对自托管 AI 工具如何管理敏感数据、身份验证和模型更新表示担忧。其他人则质疑本地部署是否会将用户暴露于新的风险中 —— 例如未打补丁的服务器实例或社区分支中的恶意代码贡献。随着贡献者和维护者努力解决这些问题,OpenClaw 的崛起促使整个 AI 生态系统就开放性、隐私性和安全性之间的权衡展开了更广泛的讨论。
为提升 OpenClaw 项目的安全性和稳健性,NVIDIA 正在与 Steinberger 以及 OpenClaw 开发者社区合作,共同应对潜在漏洞,OpenClaw 在近期发布的一篇博客对此进行了详细介绍。
NVIDIA 提供的代码和指导侧重于改进模型隔离、更好地管理本地数据访问以及加强社区代码贡献的验证流程。目标是通过以开放、透明的方式贡献其在安全和系统方面的专业知识来支持该项目的发展势头,从而在保持 OpenClaw 独立治理的同时加强社区的工作。
为了让长时间运行的智能体在企业环境中更加安全,NVIDIA 还推出了 NVIDIA NemoClaw,这是一个参考实现方案,使用单个命令即可安装 OpenClaw、NVIDIA OpenShell 安全运行时和 NVIDIA Nemotron 开放模型,这些模型具有针对网络、数据访问和安全性的强化默认设置。NemoClaw 为组织更安全地部署 Claw 提供了一个蓝图。
每次 AI 浪潮都令推理需求成倍增长
AI 已经历四个阶段,且每个阶段间的间隔正在缩短。预测式 AI 花了数年才成为主流;生成式 AI 普及速度更快;推理 AI 的到来则更为迅速。OpenClaw 所代表的自主 AI 浪潮,正在以更快的速度向前推进。
伴随每次浪潮而加剧的是推理需求。与预测式 AI 相比,生成式 AI 增加了 Token 的使用量,推理 AI 则将其进一步提升了 100 倍。而持续运行并在长时间跨度内执行操作的自主智能体,将推理需求在推理 AI 的基础上又提升了 1000 倍。每次浪潮都使所需的算力成倍增加。

Token 使用量的增加使组织能够以数量级的方式提升生产效率。例如,长时间运行的智能体可以帮助研究人员在一夜之间解决问题、在数千种配置中迭代设计,或监测系统并仅显示需要人工判断的异常情况 —— 从而解放研究人员的工作时间,让他们专注于更高价值的任务。
选择工具:何时部署 “Claw”
虽然生成式 AI 已经成为按需任务的主力工具,但在某些特定场景中,Claw 持续的“心跳”具有显著优势。何时从基于标准提示词的 AI 转向长时间运行的智能体通常取决于工作流的性质:
- 从“按需启动”到“始终在线”:虽然标准模型非常适合处理即时、人工触发的查询,但 Claw 通常更适合需要持续后台监测或定期系统检查而无需手动启动的任务。
- 管理高频迭代循环:对于复杂问题,例如测试数千种化学组合或模拟基础设施压力测试,Claw 可以管理大量迭代,否则这些迭代可能会因人为干预而遭遇瓶颈。
- 从建议转向行动:在许多工作流中,标准 AI 用于提供信息或生成草稿。当目标是让 AI 进入执行阶段 —— 在较长时间跨度内与 API 交互、更新数据库或管理文件时,通常会考虑使用 Claw。
- 资源优化:对于大规模、Token 高消耗的推理任务,与高频调用云 API 相比,在 NVIDIA DGX Spark 个人 AI 超级计算机等专用硬件上部署本地 Claw,不仅成本更具可预测性,还能确保数据隐私安全。
组织如何应用长时间运行的自主智能体?
长时间运行的自主智能体的实际应用已遍布各个职能部门和行业领域。
在金融服务领域,智能体会持续监测交易系统和监管信息,在进行晨间审查之前标记重要事件。在药物研发领域,智能体会扫描新的科学文献,提取相关发现,并在没有研究人员干预的情况下实时更新内部数据库 —— 而这一过程以前需要数周时间。
在工程和制造领域,智能体通过测试数千个参数组合、对结果进行排序并标记值得检查的配置来加速问题分析 —— 而这些都可以在一夜之间完成。
在 IT 运维中,智能体可诊断基础设施故障、应用已知补救措施,并仅升级处理新出现的问题 ——将平均解决时间从数小时缩短至数分钟。在 ServiceNow,借助 Apriel 和 NVIDIA Nemotron 模型的 AI 专家能够自主解决 90% 的工单。
企业如何负责任地部署自主智能体?
自主智能体具备实际操作能力。它们可以发送通信、写入文件、调用 API 和更新实时系统。当智能体执行错误操作时,就会产生实际后果。从一开始就建立正确的问责框架至关重要,在生产环境中部署自主智能体的组织必须将治理视为首要需求。
组织需要了解它们的智能体正在做什么,检查每个步骤的推理过程,检查其行为并在必要时进行干预。
负责任地部署自主智能体的组织聚焦以下三个优先事项:
- 开放、可审计的框架:NemoClaw 基于 OpenClaw 的 MIT 许可代码库构建,这意味着组织拥有完整的智能体运行框架。他们可以读取、分支并修改智能体构建和部署的每一层。这种透明度使团队能够在代码级别了解和控制系统。在本地运行如 NVIDIA Nemotron 这样的开源模型,可以将包括患者记录、法律文件、金融交易和专有研究在内的敏感工作负载保存在组织自己的环境中,确保追踪数据始终处于组织的控制之下。
- 保护运行时环境:NemoClaw 在 OpenShell 中运行智能体,这个沙盒环境明确定义了智能体可以做什么和不能做什么,从一开始就强制执行明确的权限边界。
- 本地计算:NVIDIA DGX Spark 超级计算机以桌面级的外形尺寸提供数据中心级 GPU 性能,专为始终在线的本地推理而构建,支持本地模型托管,并确保数据留在组织环境中。对于需要在复杂持续的工作负载,且同时运行多个智能体的团队,NVIDIA DGX Station 系统能够进一步扩展这种能力。
那些在实践中定义自主智能体行为的组织正在积累有价值的东西:数月的实时运营经验、通过实际工作负载开发的治理框架,以及吸收了组织内部背景知识从而变得真正实用的智能体。随着时间的推移,这一基础只会逐渐深化。
开始使用 NVIDIA NemoClaw
访问分步教程,了解如何在 NVIDIA DGX Spark 上使用 NemoClaw 构建更安全的 AI 智能体。探索 NemoClaw 如何通过单个命令部署更安全且始终在线的 AI 助手。
您可以在 GitHub 上体验 NemoClaw,与大家一起在 DGX Spark 上使用 NVIDIA Nemotron 3 Super 和 Telegram 构建 NemoClaw 应用。
订阅 NVIDIA AI 新闻、加入 NVIDIA 开发者社区,及时了解关于代理式 AI 和 NVIDIA Nemotron等最新资讯。