
实时自然语言理解将改变我们与智能机器和应用程序的交互方式。
高质量人机对话应响应迅速、智能且声音自然。
但目前为止,在开发语言处理神经网络以支持实时语音应用程序的过程中,开发人员被迫面临着一种权衡:要实现快速响应,必须牺牲响应质量;要追求智能响应,则不可避免会减慢速度。
这是因为人类对话极其复杂,每个语句都建立在既定语境和先前的交互之上。从“内涵笑话”到特定文化背景中的“梗”和文字游戏,人类总是能够毫不迟疑且极为微妙地进行交谈。每个响应之间几乎无缝衔接。朋友之间交流时,未等对方开口便能猜到他要说什么。
什么是对话式人工智能?
真正的对话式人工智能是一种语音助手,能够进行类人对话,捕捉语境并提供智能响应。这种 AI 模型一定很庞大且十分复杂。
但模型越大,用户提问与 AI 应答之间的延迟就越长。如果间隔超过 0.2 秒,对话可能听起来就会不自然。
借助 NVIDIA GPU 和 CUDA-X AI 库可以快速训练和优化大量最先进的语言模型,从而将推理运行时间控制在短短几毫秒(1毫秒=千分之一秒)内。这对开发人员来说是一项重大进展,因为他们无需再对高速 AI 模型与大型且复杂的 AI 模型进行权衡。
这些突破有助于开发人员构建和部署最先进的神经网络,并让我们距离目标更进一步:即实现真正的对话式人工智能。
GPU 优化的语言理解模型可集成到医疗保健、零售和金融服务等行业的 AI 应用程序中,为智能扬声器和客户服务领域中的高级数字语音助手提供支持。通过使用这些高质量的对话式人工智能工具,各个领域的企业在与客户交流时,均可实现前所未有的个性化服务标准。
对话式人工智能的速度必须达到多快?
自然对话中的标准响应间隔大约为 200 毫秒。为了让 AI 模仿人类交互,它可能需要依次运行十二个或更多的神经网络,完成多层任务——所有这些任务均要在 200 毫秒或更短的时间内完成。
回答问题的步骤如下:将用户语音转换为文本,理解文本含义,搜索符合语境的最佳应答,最后使用文本转语音工具提供应答。每一步都需要运行多个 AI 模型,因此每个单独网络的可用执行时间约为 10 毫秒或更短。
如果每个模型的运行时间较长,则响应速度会大大减慢,因此对话就会变得不和谐且不自然。
在如此严格的延迟标准下,当前语言理解工具的开发人员必须做出权衡。高质量的复杂模型可用作聊天机器人,在这种情况下,延迟并不像在语音接口中那样重要。开发人员也可以利用较小的语言处理模型,这种模型能够更快地给出结果,但应答却无法做到细致入微。
未来的对话式人工智能是什么样的?
电话树算法等基本语音接口(带有如“要预定新航班,请说‘预订’”之类的提示)都是事务型的,需要一系列步骤和响应,通过预先编程的队列来推动用户进行下一步操作。有时,只有电话树末端的工作人员才能理解微妙的问题并以智能方式解决来电者的问题。
当前市场上的语音助理更加智能,但它们所基于的语言模型并不像想象中的那么复杂,其中只包含有数百万(而非数十亿)个参数。这些 AI 工具可能会在对话过程中出现延迟,如在回答问题之前,提供“我来帮你查一下”之类的应答。或者它们会显示一列网页搜索结果,而不是以会话语言的形式对查询做出响应。
真正的对话式人工智能将实现进一步飞跃。理想模型十分复杂,能够准确理解人们有关其银行对帐单或医疗报告结果的查询,且几乎能够瞬时以无缝的自然语言作出响应。
这项技术可应用于医生办公室的语音助手,帮助患者安排预约和后续验血,或应用于零售业的语音 AI,向愤怒的来电者解释包裹运送延迟的原因,并提供商店积分作为补偿。
现如今,人们对这种高级对话式人工智能工具的需求日益增加:预计到 2020 年,50% 的搜索结果将由语音执行,且到 2023 年,将有 80 亿个数字语音助手投入使用。
什么是 BERT?
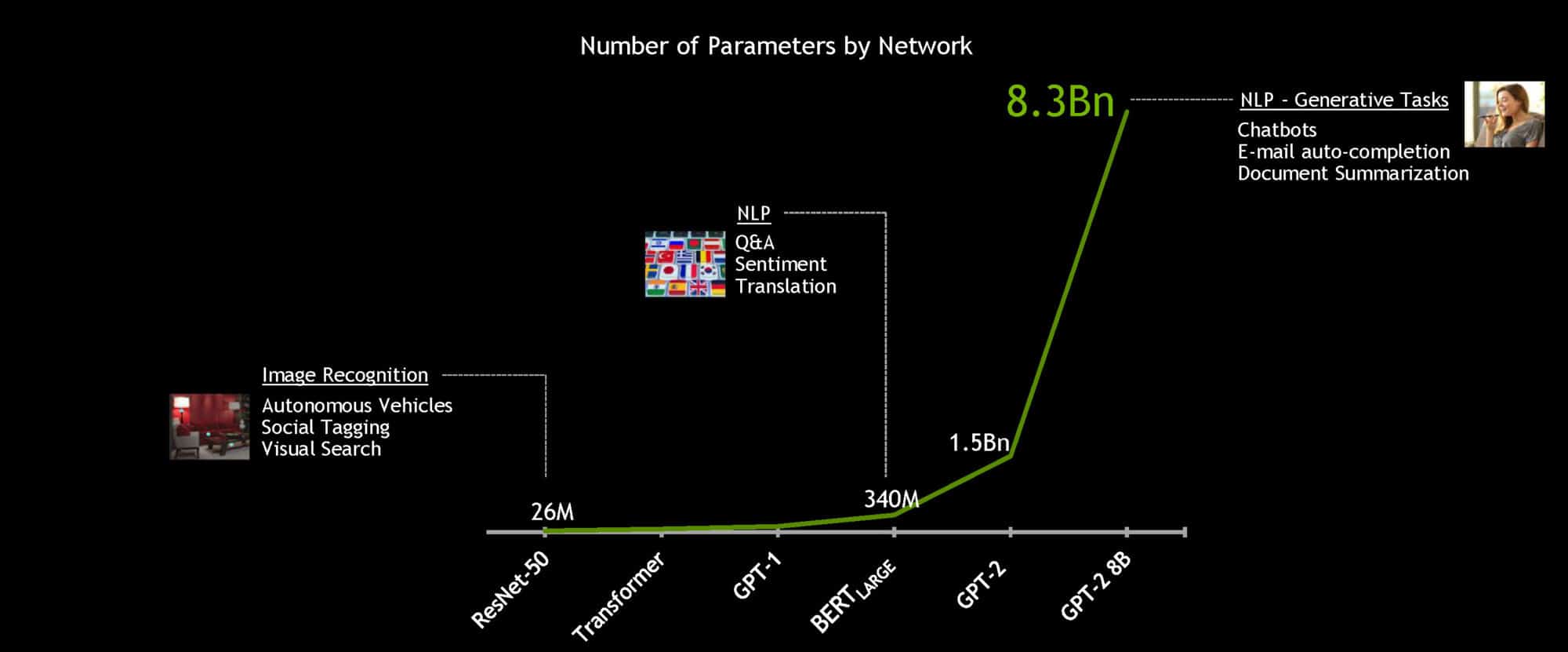
BERT(Transformer 的双向编码器表示)是一种大型计算密集型模型,自去年推出后,便立即成为了最先进的自然语言理解模型。微调后的 BERT 可应用于各种语言任务,如阅读理解、情感分析或问答等。
BERT 基于一个包含 33 亿单词的大型英语文本语料库进行训练,在某些情况下,它甚至比普通人更擅长理解语言。它的优势在于能够基于未标记的数据集进行训练,且无需经过大的修改,便可推广到各种应用程序。
同一个 BERT 可用于理解多种语言,且经过微调后,可执行翻译、自动完成或搜索结果排序等特定任务。由于这种通用性,它成为了开发复杂自然语言理解的常用选择。
BERT 基于 Transformer 层级,即递归神经网络的备选方案。它使用了 Attention 技术,可利用句子前后最具关联性的词语进行句子解析。
例如“窗外有个 crane(鹤;吊车)”,这句话可能描述的是一只鸟或一个施工场地,具体情况取决于事件地点是“湖边小屋”还是“办公室”。借助一种双向或非定向编码方法,BERT 等语言模型可利用语境线索更好地理解每种情况下的具体含义。
现如今,跨领域的领先语言处理模型基于 BERT,包括 BioBERT(适用于生物医学文档)和 SciBERT(适用于科学出版物)。
NVIDIA 技术如何优化基于 Transformer 的模型?
在与复杂语言模型协作时,NVIDIA GPU 的并行处理能力和 Tensor Core 架构可实现更高的吞吐量和可扩展性,从而为 BERT 的训练和推理提供史无前例的性能。
借助功能强大的 NVIDIA DGX SuperPOD 系统,这个包含 3.4 亿参数的 BERT 大型模型可在一小时内完成训练,而一般的训练需要花上几天时间。但对于实时对话式人工智能,提速主要是为了推理。
NVIDIA 开发者使用 TensorRT 软件优化了包含 1.1 亿参数的 BERT 基准模型。该模型在 NVIDIA T4 GPU 上运行,基于“斯坦福问答数据集”进行测试时,它只用 2.2 毫秒就完成了响应计算。SQuAD 数据集是一种常见基准,用于评估模型理解语境的能力。
许多实时应用程序的延迟阈值为 10 毫秒。即使是经过高度优化的 CPU 代码,处理时间也会超过 40 毫秒。
将推理时间缩短到几毫秒,说明在生产中部署 BERT 具有一定的可行性。而且我们不仅止步于 BERT,同样的方法也可用于加速基于 Transformer 的其他大型语言模型,如 GPT、XLNet 和 RoBERTa。
为实现真正的对话式人工智能,语言模型变得越来越大。未来的模型将比现在使用的大很多倍,因此 NVIDIA 构建并开源了迄今为止最大的基于 Transformer 的 AI:GPT-2 8B,这是一种内含 830 亿参数的语言处理模型,比 BERT 大 24 倍。
如需了解有关在 GPU 上训练 BERT、优化 BERT 推理性能以及自然语言处理中的其他项目的更多信息,请查阅 NVIDIA 的开发者博客。