许多用户希望在本地运行 大语言模型 (LLM) ,以便更好地保护隐私、获得更多控制权,并避免订阅。但这意味着要在输出质量上做出妥协。直到最近,这个问题才得到解决。新发布的开放权重模型,例如 OpenAI 的 gpt-oss 和阿里巴巴的通义千问 3 (Qwen 3),可以直接在 PC 上运行,并提供优质且实用的输出,尤其适用于本地智能体 AI。
这为学生、业余爱好者和开发者开辟了在本地探索生成式 AI 应用的新机遇。NVIDIA RTX PC 可加速这些体验,为用户带来快速、敏捷的 AI。
已针对 RTX PC 优化的本地 LLM 入门指南
NVIDIA 致力于为 RTX PC 优化热门大语言模型应用,以充分发挥 RTX GPU 中 Tensor Core 的强大性能。
开始在 PC 上使用 AI 的最简单方式之一就是使用 Ollama,这是一款开源工具,提供简单的界面,用于运行大语言模型并与之交互。这款工具支持将 PDF 拖放到提示窗口、进行对话式聊天,以及包括文本和图像的多模态理解工作流。
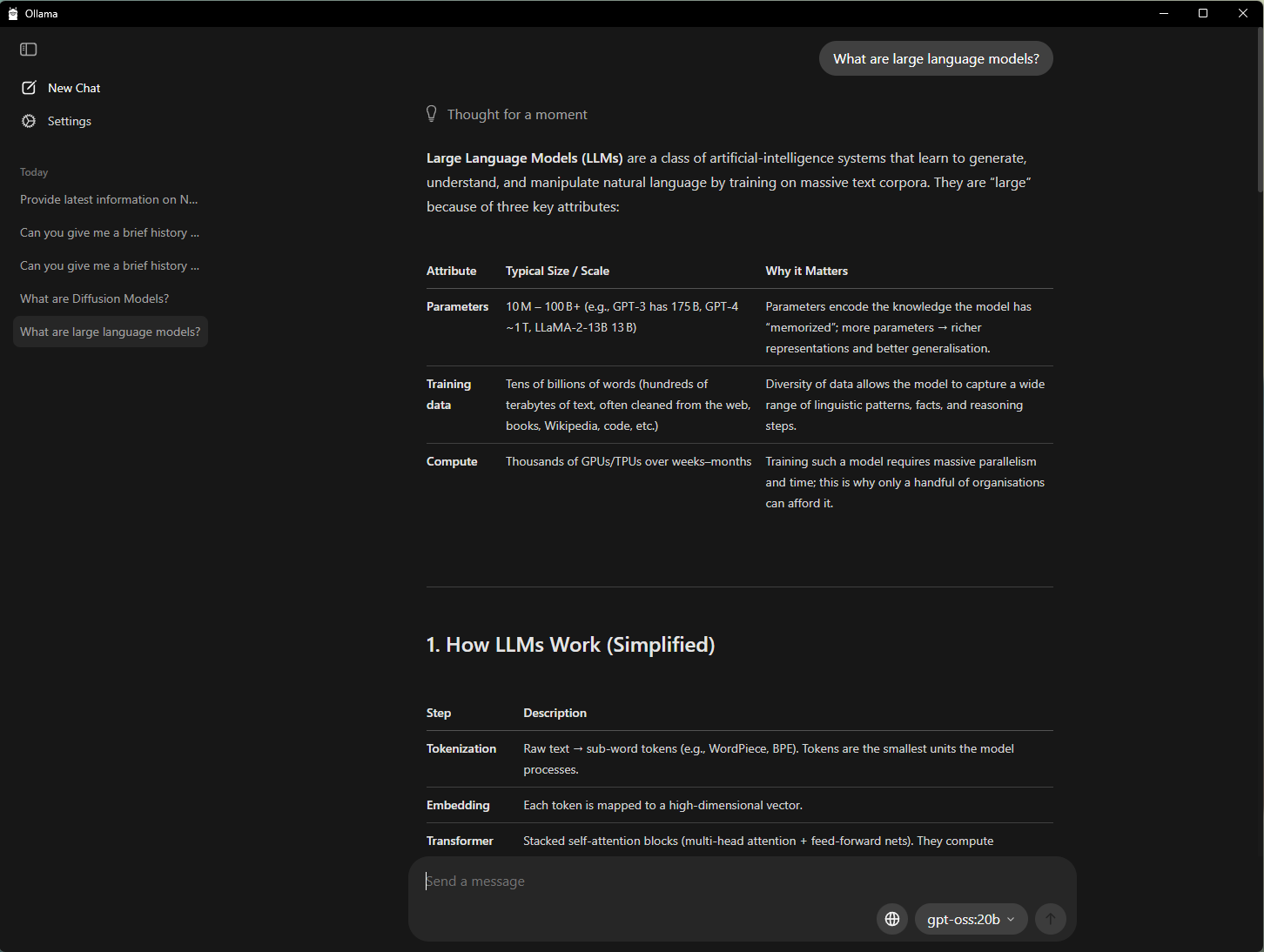
NVIDIA 已与 Ollama 展开合作,旨在提升其性能和用户体验。最新进展包括:
- 已针对 GeForce RTX GPU 优化 OpenAI gpt-oss-20B 模型和 Google Gemma 3 系列模型的性能
- 推出针对全新 Gemma 3 270M 和 EmbeddingGemma 模型的支持,为超高效 RAG 提供助力
- 改进了模型调度系统,以尽可能提高显存利用率并更准确的记录显存占用
- 提升了稳定性,以减少崩溃次数
同时,Ollama 是一个可与其他应用搭配使用的开发者框架。例如,开源应用 AnythingLLM(它允许用户构建由任意 LLM 提供支持的个人 AI 助理)就可以基于 Ollama 运行,并受益于 Ollama 的所有加速功能。
发烧玩家还可以通过 LM Studio 来上手使用本地大语言模型,该应用由广受欢迎的 llama.cpp 框架提供支持。该应用提供用户友好的界面,以便用户在本地运行模型。用户可借助该应用加载不同的大语言模型、与大语言模型进行实时聊天,甚至将大语言模型作为本地应用程序编程接口 (API) 端点集成到自定义项目中。
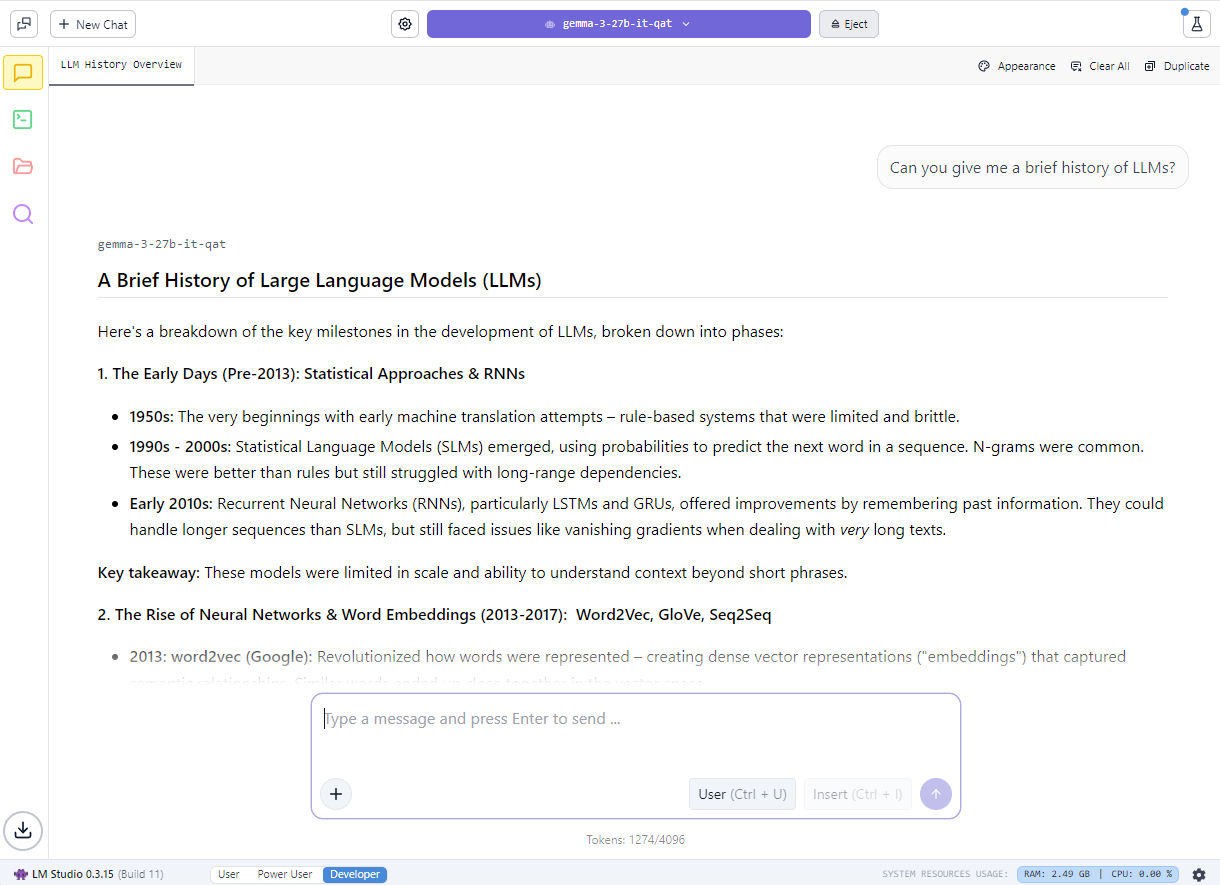
NVIDIA 已与 llama.cpp 的开发团队展开合作,以优化该框架在 RTX GPU 上的性能。最新更新包括:
- 推出了适用于最新的 NVIDIA Nemotron Nano v2 9B 模型的支持,该模型基于全新的混合 Mamba 模型架构
- Flash Attention 现在会默认开启,与关闭 Flash Attention 相比,可将性能提升多达 20%
- 已针对 RMS Norm 和基于 fast-div 的取模运算优化了 CUDA Kernel,可使热门模型的性能提升多达 9%
- 推行语义版本控制,让开发者能够轻松采用后续版本
了解更多 gpt-oss 在 RTX 上运行的详情,以及 NVIDIA 如何与 LM Studio 合作,以加速 RTX PC 上的大语言模型性能。
通过 AnythingLLM 打造 AI 赋能的学习伙伴
除了提升隐私保障和性能外,在本地运行大语言模型还可以消除文件加载数量或可用时间方面的限制,从而实现更长时间的上下文感知 AI 对话。在构建对话式 AI 和生成式 AI 支持的助理时,这能带来更高的灵活性。
对于学生来说,管理大量幻灯片、笔记、实验报告和过往考试资料可能会令人不堪重负。本地大语言模型让学生能够打造一个可以适应个人学习需求的个性化指导老师。
以下演示展示了学生可如何使用本地大语言模型来构建生成式 AI 助理:
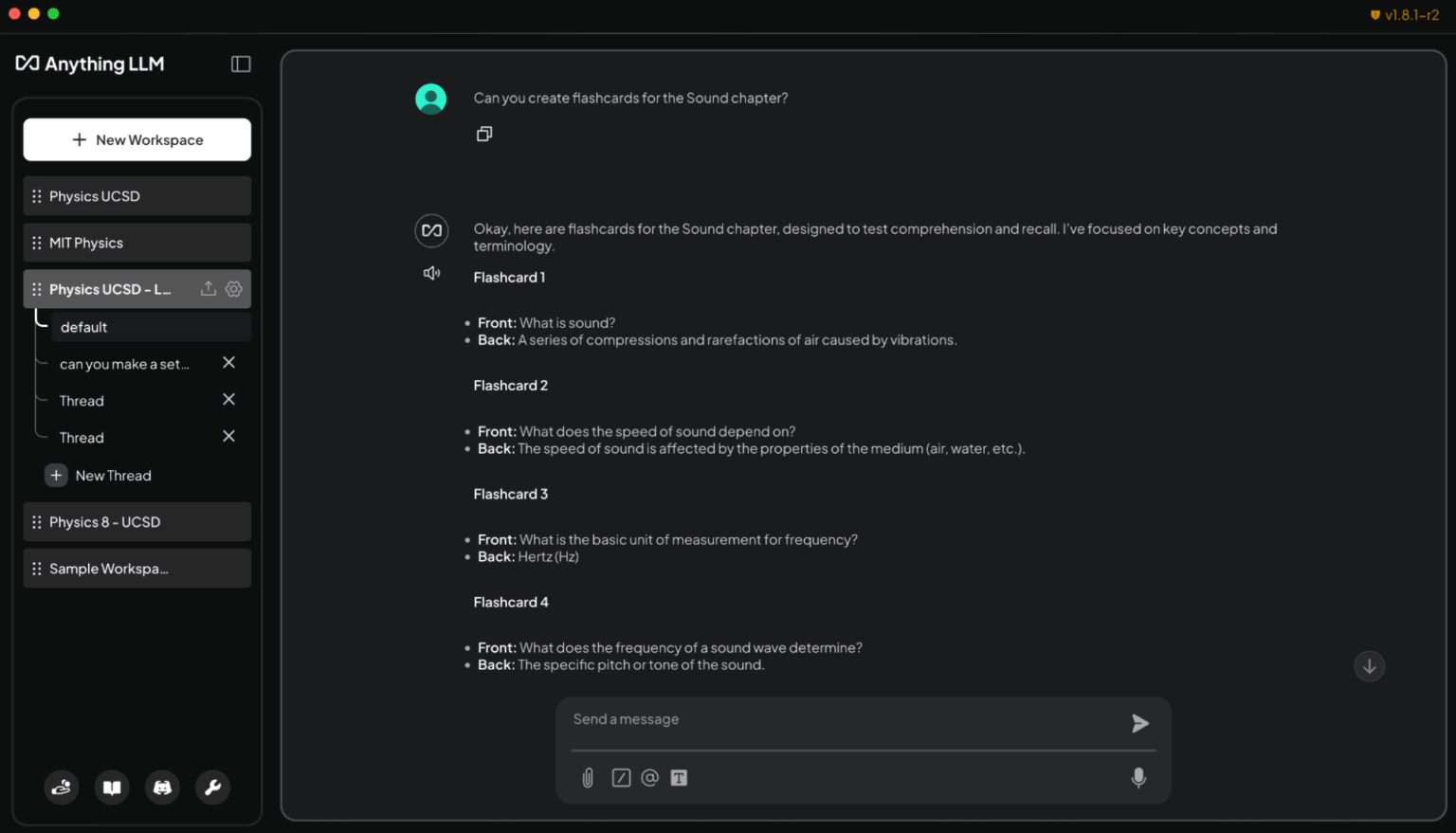
要实现这一点,一种简单的方式便是借助 AnythingLLM,这款应用能够帮助用户连接文档和数据,从而构建自定义 AI 聊天机器人和智能体。该应用支持文档上传、自定义知识库以及对话式界面。这使其成为了一款灵活的工具,适合任何想要创建可自定义 AI,以帮助完成研究、项目或日常任务的用户。此外,通过 RTX 加速,用户还可以享受更快的响应速度。
学生只需将课程大纲、作业和课本加载到 RTX PC 上的 AnythingLLM,就能获得一个具备自适应能力的交互式学习伙伴。他们可以使用纯文本或语音,请求智能体协助完成以下任务:
- 根据讲义幻灯片生成知识卡片:“请根据《声音》章节的讲义幻灯片创建知识卡片。请将关键术语放在一面,将定义放在另一面。”
- 提出与学习资料相关的情境问题:“请根据我的《物理 8》笔记解释动量守恒定律。”
- 创建测验并批改以备考:“请根据化学课本第 5 至第 6 章创建一份包含 10 道选择题的测验,并批改我的答案。”
- 逐步讲解难题:“请逐步演示如何解答编程作业中的第 4 题。”
除了课堂学习之外,业余爱好者和专业人士还可以使用 AnythingLLM 来准备全新研究领域的认证考试,或将 AnythingLLM 用于其他类似目的。此外,在 RTX GPU 上本地运行,还能确保快速获得响应、保障隐私,同时免除订阅费用或使用限制。
Project G-Assist 现可控制笔记本电脑设置
Project G-Assist 是一款实验性 AI 助理,可帮助用户通过简单的语音或文本命令调整、控制和优化游戏 PC,而无需手动翻找菜单。在接下来的一天里,全新的 G-Assist 更新将通过 NVIDIA app 主页推出。
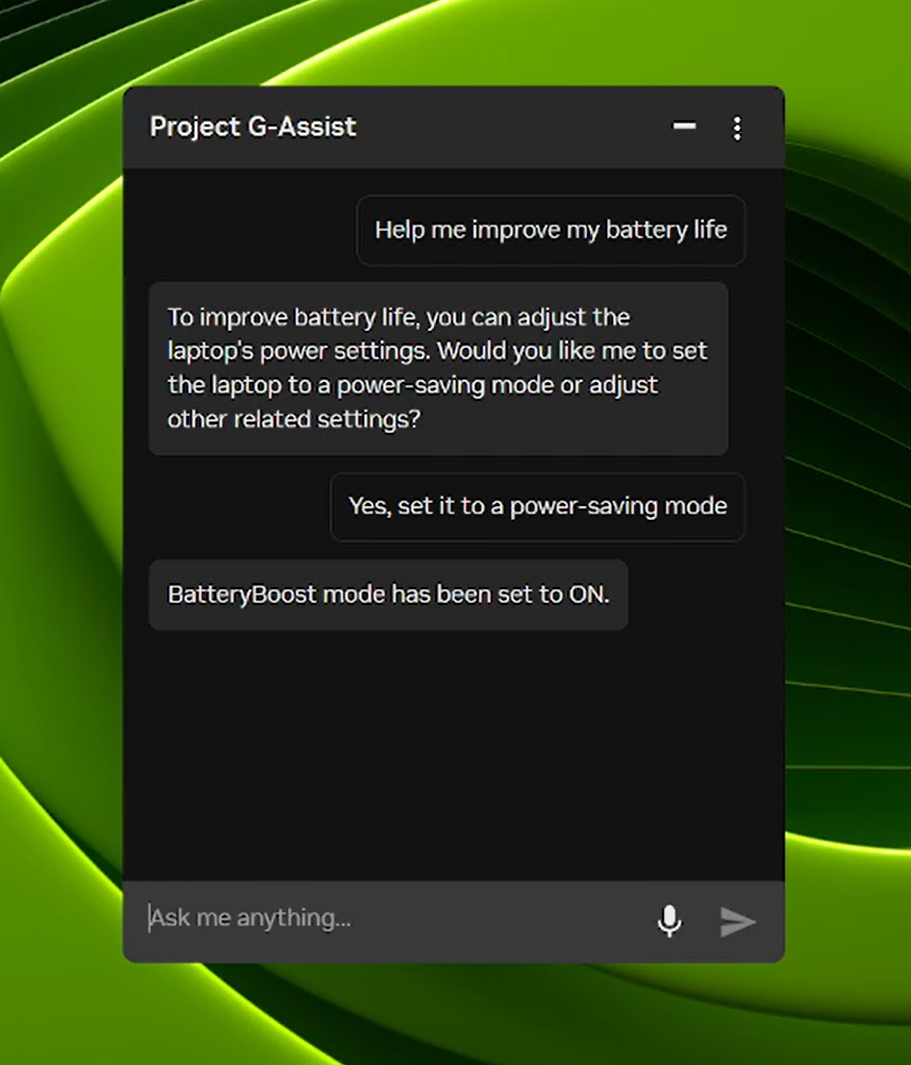
今年八月的更新带来了更高效的全新 AI 模型以及对更多 RTX GPU 的支持,而本次 G-Assist 更新则新增了调整笔记本电脑设置的命令,包括:
- 针对笔记本电脑优化应用配置文件:当笔记本电脑未连接充电器时,自动将游戏或应用调整为最佳性能、最佳画质或平衡模式。
- BatteryBoost 控制:启用或调节 BatteryBoost,在保持流畅帧率的同时延长电池续航时间。
- WhisperMode 智能降噪控制:可在需要时将风扇噪音降低多达 50%,并在不需要时恢复到全性能模式。
G-Assist 项目亦支持扩展。通过 G-Assist Plug-In Builder,用户可以添加新命令,或将外部工具与易于创建的插件连接,从而创建和自定义 G-Assist 功能。此外,通过 G-Assist Plug-In Hub,用户还能轻松发现并安装插件,以扩展 G-Assist 功能。
访问 NVIDIA 的 G-Assist GitHub 资源库,以获取入门指导材料,其中包括示例插件、分步说明以及用于构建自定义功能的文档。
#ICYMI——RTX AI PC 的最新进展
🎉 Ollama 在 RTX 上的性能获得显著提升
最新更新优化了 OpenAI gpt-oss-20B 的性能,提升了 Gemma 3 模型的运行速度,并让模型调度变得更智能,以减少内存问题并提高多 GPU 效率。
🚀 Llama.cpp 与 GGML 已针对 RTX 进行优化
最新更新可在 RTX GPU 上实现更快、更高效的推理,包括对 NVIDIA Nemotron Nano v2 9B 模型的支持,默认启用 Flash Attention,以及对 CUDA 内核的优化。
⚡ G-Assist 项目更新现已推出
通过 NVIDIA app 下载 G-Assist v0.1.18 更新,本次更新推出了可供笔记本电脑用户使用的新命令,还提升了回答质量。
⚙️ 采用 NVIDIA TensorRT for RTX 的 Windows ML 现已正式推出
Microsoft 现已发布采用 NVIDIA TensorRT for RTX 加速技术的 Windows ML,可在 Windows 11 PC 上将大语言模型、扩散模型及其他类型的模型的推理速度提升多达 50%,同时简化这些模型的部署流程,并为其提供支持。
🌐 NVIDIA Nemotron 助力 AI 开发
NVIDIA Nemotron 系列开放模型、数据集与技术正在推动 AI 创新,从通用推理到行业特定应用,处处都受其影响。
每周,RTX AI Garage 博客系列都会分享由社区推动的 AI 创新与内容,面向希望深入了解 NIM 微服务、AI Blueprint,以及如何在 AI PC 和工作站上构建 AI 智能体、创意工作流、数字人、生产力应用等的用户。
欢迎关注 NVIDIA 在微博、微信和哔哩哔哩的官方账号,获取最新资讯请订阅 RTX AI PC 新闻通讯。
请参阅有关软件产品信息的通知。