
编者注:本文属于《AI 解密》系列栏目,该系列的目的是让技术更加简单易懂,从而解密 AI,同时向 GeForce RTX PC 和 NVIDIA RTX 工作站用户展示全新硬件、软件、工具和加速特性。
从游戏和内容创作应用,再到软件开发和生产力工具,AI 正越来越多地集成到应用中,以增强用户体验和提高效率。
这些效率提升将延伸到日常任务,如网页浏览。作为一款致力于保护隐私的网络浏览器,Brave 最近推出了一款名为 Leo AI 的智能 AI 助手,除提供搜索结果之外,该助手还可以帮助用户总结文章和视频,从文档中获取见解,回答问题等。
Brave 和其他 AI 赋能工具背后的技术组合了硬件、软件开发库和生态系统软件,这类软件经过优化,可满足 AI 的独特需求。
为什么软件至关重要
从数据中心到 PC,NVIDIA GPU 构建了世界的 AI。它们包含 Tensor 核心,这些核心经过专门设计,可通过大规模的并行运算来加速 Leo AI 这类 AI 应用 — 快速同步处理 AI 所需的大量运算,而不是逐次运算。
但只有当应用能够高效利用强大的硬件时,这些硬件才有意义。在 GPU 上运行的软件对于提供最快速和最具交互性的 AI 体验同样至关重要。
第一层是 AI 推理库,它充当转换器,用于接收常见的 AI 任务请求,然后将其转换为特定指令以便硬件运行。热门推理库包括 NVIDIA TensorRT、Microsoft 的 DirectML,以及 Brave 和 Leo AI 通过 Ollama 使用的名为 llama.cpp 的推理库。
Llama.cpp 是一个开源软件开发库和框架。CUDA 是 NVIDIA 的软件应用编程接口,可帮助开发者为 GeForce RTX 和 NVIDIA RTX GPU 进行优化,通过 CUDA 可为数百个模型提供 Tensor 核心加速,包括热门的大语言模型 (LLM),如 Gemma、Llama 3、Mistral 和 Phi。
除推理库以外,应用通常还使用本地推理服务器来简化集成。推理服务器负责处理下载和配置特定 AI 模型等任务,以便减轻推理库的负担。
Ollama 是一个开放源代码项目,它构建于 llama.cpp 之上,提供对软件开发库功能特性的访问。它支持提供本地 AI 功能的应用生态系统。在整个技术栈中,NVIDIA 致力于优化 Ollama 等工具,以便在 RTX 硬件上提供更快、响应速度更出色的 AI 体验。

NVIDIA 对优化的专注涵盖整个技术栈 — 从硬件到系统软件,再到推理库和工具,以帮助 RTX 上的应用提供更快、响应速度更出色的 AI 体验。
本地与云端对比
Brave 的 Leo AI 可以通过 Ollama 在云端或本地 PC 上运行。
使用本地模型推理具有诸多优势。由于无需向外部服务器发送提示词以进行处理,因此可获得专有且始终可用的体验。例如,Brave 用户可以获得有关财务或医疗问题的帮助,而无需向云端发送任何内容。此外,在本地运行也不需要为无限制的云访问付费。使用 Ollama,用户可以利用比大多数托管服务更广泛的开源模型,后者通常只支持同一 AI 模型的一或两个变体。
用户还可以与专业领域各不相同的模型进行交互,例如双语模型、紧凑型模型、代码生成模型等。
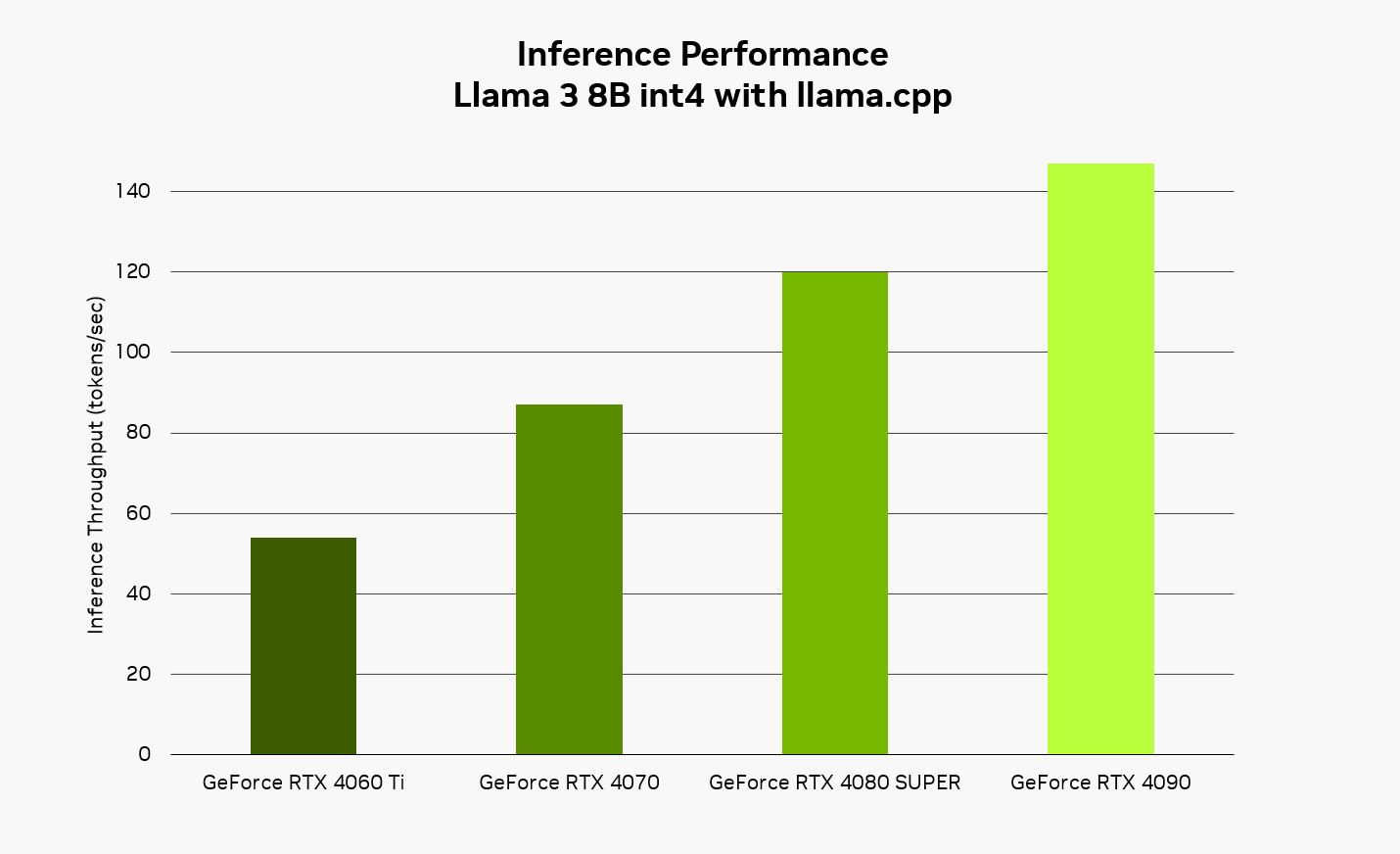
在本地运行 AI 时,RTX 能够提供快速、响应速度较高的体验。使用 Llama 3 8B 模型配合 llama.cpp,用户可体验高达 149 token/s (约等于每秒 110 个单词) 的响应速度。将 Brave 与 Leo AI 和 Ollama 搭配使用时,它能更迅速地回复问题、内容摘要等请求。
开始使用 Brave 与 Leo AI 和 Ollama
安装 Ollama 非常简单 — 只需从项目网站下载安装程序,然后在后台运行即可。用户可以通过命令提示符下载并安装一系列受支持的模型,然后从命令行与本地模型进行交互。
有关如何通过 Ollama 添加本地 LLM 支持的简单说明,请参阅该公司博客。配置好 Ollama 之后,Leo AI 将使用本地托管的 LLM 来处理用户请求。用户还可以随时在云端和本地模型之间切换。
开发者可以在 NVIDIA 技术博客中了解更多有关如何使用 Ollama 和 llama.cpp 的信息。
请订阅《解码 AI》时事通讯,我们每周都会将新鲜资讯直接投递到您的收件箱。