
对于未受过训练的人来说,它们是一堆各种颜色的方框、方块和数字。而对于训练有素的观察者而言,它们是从鱼眼摄像头、激光雷达和其他传感器读取到的数据。而对于自动驾驶汽车而言,这就是它们穿梭而过的复杂环境的细节。
在今年的拉斯维加斯国际消费电子展上,您将看到汽车制造商和研究人员所作的大量演示,他们从新一代自动驾驶系统的角度展示车辆未来发展趋势。
凭借全球最强大的车用人工智能引擎 NVIDIA DRIVE PX 2,我们引领自动驾驶汽车的研发。使用 DriveWorks 软件和 DRIVE PX 2,将帮助汽车开发人员将深度学习的动力用于新一代无人驾驶汽车上。
这些新系统所展现出的新技术令人惊叹不已 – 每秒可以处理 24 万亿次深度学习操作。新系统所取得的成绩需要作一下说明。
下面简单介绍一下在观看自动驾驶演示时,您会看到和不会看到的内容。
您会看到的内容
您将看到两大类的识别能力展示:
语意分割 – 这项能力可标示出属于特定类别物体的像素 (构成计算机图像的小点)。我们可以从下图中看到道路是蓝色的。人是橙色的。车辆是红色的。如果计算机识别图像内物体的精细程度能达到这种水平,那么我们就能对自动驾驶系统安全导航的能力怀有更大的信心。

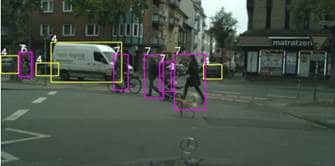
物体检测 – 这项能力可以用方框标示出物体位置。您将在多个视频中看到我们同时检测多个类别物体的能力。在以下示例中,我们设计了一款能识别行人和车辆的探测器。使用方框比分割法更容易标示物体位置。
您不会看到的内容
在多数展示自动驾驶系统所看到的路况画面的演示中,您可以在屏幕上注意到语意分割和物体探测这两项技术。
但是您看不到推动这一切的重要幕后推手: 深度学习技术。深度学习技术让我们做到人类无法完成的事情。开发出能识别路上每个物体类别的软件并不具有实用性,因为路上的东西太多了。
因此,正确的解决方案应能教会机器进行自我学习。深度学习技术可让我们设定一个有难度的目标。如果使用对的方法或算法得出正确的公式,神经网络就能找出解决复杂问题的方法。
我们利用 NVIDIA GPU 的超强计算能力来训练这些神经网络。GPU 能一次平行处理许多任务,因而是深度学习的不二之选。
我们将以最近推出的 GoogLeNet 和 VGG 等先进深度学习网络为基础,使用单次检测和分割架构。单次意味着网络可以获得完整的图像,并输出检测或分割像素标识内容。
此举能让汽车制造商使用真实驾驶情境视频,快速训练系统在各种情况下识别物体。投入深度学习系统中的的数据越多,系统就会变得更智能。而且,这还可让他们将结果与由独立研究单位管理的真实图像识别基准 (如 KITTI 基准套件) 相比较,以便了解与同行产品相比,自己的产品表现如何。
如何判断您所看到的内容
下次再观看演示时,请提出三个问题。如何训练这些系统理解其从未见过的状况?它们是否实时运行?与计算机科学家用于测量这些计算机视觉系统精度的基准相比,这些结果的表现又是如何?
图片由戴姆勒–奔驰公司提供