最近发布的 DeepSeek-R1 系列模型已在 AI 社区掀起一阵风潮,爱好者和开发者可以在 PC 上本地运行具有问题解决、数学和代码能力的先进推解理模型,同时保障了隐私。
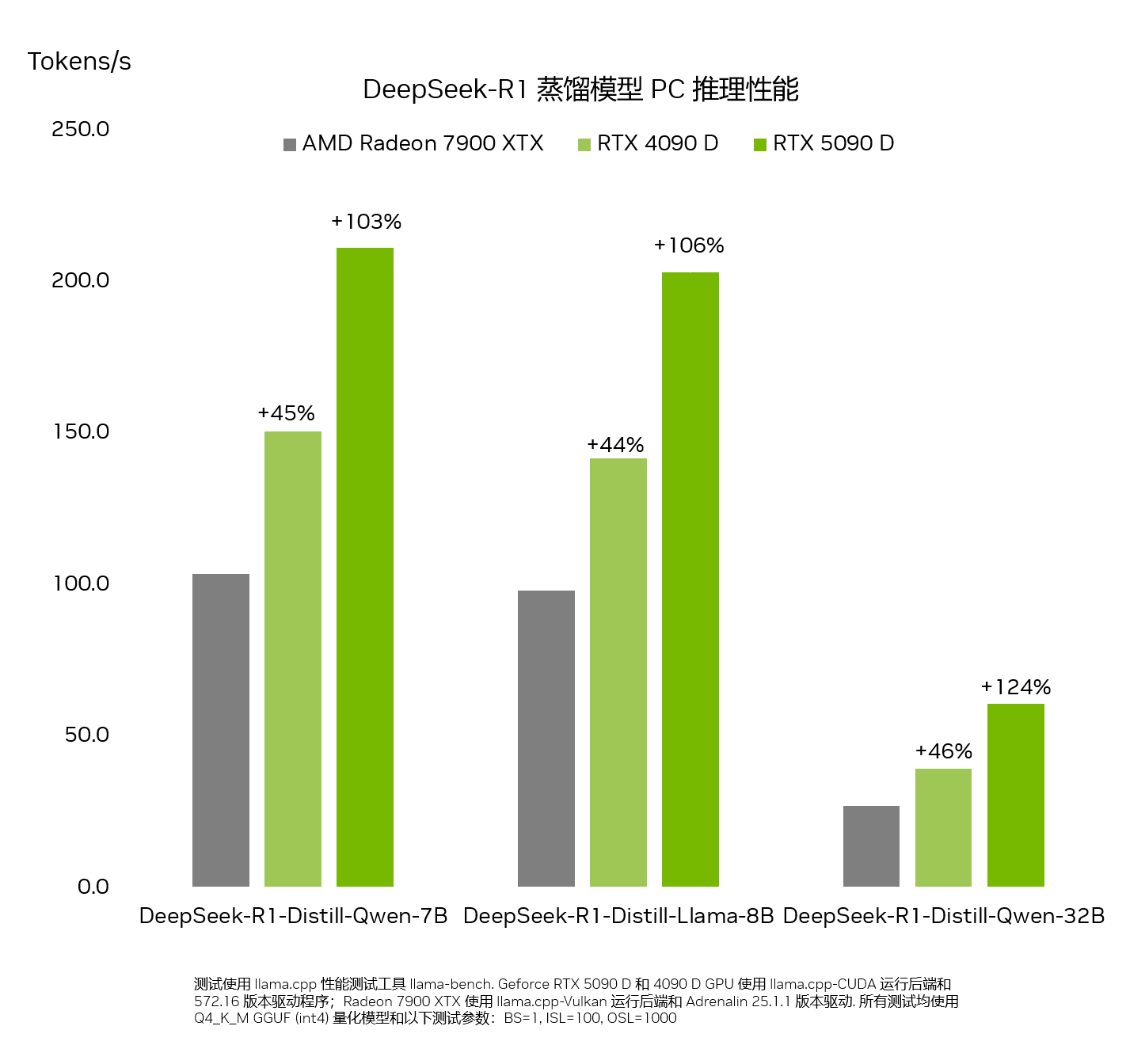
由于具有至高每秒执行 2375 万亿次运算的 AI 算力,相比于 PC 市场上的任何产品,NVIDIA GeForce RTX 50 系列 GPU 能够更快运行 DeepSeek 系列蒸馏模型。
新型推理模型
推理模型是一类全新的大语言模型 (LLM),需要花费更多时间来“思考”和“反思”以解决复杂问题,同时描述完成任务所需的步骤。
其基本原则是,任何问题都可以通过深入思考、推理并花费时间来解决,就像人类解决问题的方式一样。通过在某个问题上花费更多时间 — 从而进行计算 — LLM 能够生成更好的结果。这种现象称为 Test-time scaling,即在推理期间,模型会动态分配计算资源,以针对问题进行因果推理。
推理模型可通过深入了解用户的需求、代表用户采取行动,并允许他们对模型的思考过程提供反馈,来增强用户的 PC 体验,从而解锁智能体工作流来完成复杂的多步骤任务,例如分析市场调研、解决复杂的数学问题、调试代码等。
DeepSeek 的不同之处
DeepSeek-R1 系列蒸馏模型基于一个包含 6710 亿个参数的混合专家模型 (MoE)。MoE 模型包含多个用于解决复杂问题的小型专家模型。DeepSeek 模型会进一步分工,并将子任务分配给更小的专家群体。
DeepSeek 采用蒸馏技术,基于包含 6710 亿个参数的大型 DeepSeek 模型构建了一系列 6 个较小的学生模型 — 参数数量从 15 亿到 700 亿不等。包含 6710 亿个参数的大型 DeepSeek 模型的推理能力被“传授”给较小的 Llama 和 Qwen 学生模型,从而生成在本地 RTX AI PC 上运行、功能强大的小型高性能推理模型。
RTX 上的峰值性能
对这类新型因果推理模型来说,推理速度至关重要。GeForce RTX 50 系列 GPU 搭载了专用的第五代 Tensor Core,其基于与 NVIDIA Blackwell GPU 相同的架构,该架构为数据中心内的全球领先 AI 创新提供了强大动力。RTX 可为 DeepSeek 提供全面加速,从而在 PC 上实现出色推理性能。
借助 RTX 体验 DeepSeek
NVIDIA 的 RTX AI 平台提供了丰富的 AI 工具、软件开发套件和模型,允许用户在全球超过 1 亿台 NVIDIA RTX AI PC (包括由 GeForce RTX 50 系列 GPU 提供支持的 PC) 上使用 DeepSeek-R1 的功能。
高性能 RTX GPU 可确保 AI 功能始终可用 (即使没有互联网连接),实现低延迟并增强隐私保护,因为用户不必上传敏感材料或向在线服务披露其问答数据。
你可以通过庞大的软件生态系统,包括 Llama.cpp、Ollama、LM Studio、AnythingLLM、Jan.AI、GPT4All 和 OpenWebUI 体验 DeepSeek-R1 和 RTX AI PC 的强大功能,从而进行推理。另外,你还可以使用 Unsloth 借助自定义数据微调这些模型。