随着 AI 深度学习持续快速发展,企业努力解决的挑战类型也在不断演变。
推理这项技术可以让用户借助复杂的神经网络(利用功能强大的 GPU 进行训练)解决日常问题。
以往,大部分推理工作一直集中在“下班后”通过大量 CPU 服务器执行大批高吞吐量的工作。但现在这种情况正在迅速改变。
今后,推理将朝着精密的实时服务方向发展,这些服务以更加复杂的语音识别、自然语言处理和翻译(低延迟非常关键的领域)模型为基础。
NVIDIA Tesla 平台可以大幅提升训练和推理(深度学习核心的两项关键计算密集型操作)性能,并且可以促进大规模采用和实现能源成本节省。
随着深度学习的普及,仅搭载 CPU 的服务器无法进行扩展以满足这种需求。一台搭载 GPU 的服务器可以替代 160 台仅搭载 CPU 的服务器,而且,它还可以在低延迟情况下提供更高的推理吞吐量,从而不仅可以满足上述发展趋势的需要,还可以加快这一趋势的发展速度。
TensorRT 3 简介

推理性能不仅仅关乎速度,实际上,完整的推理性能包含四个主要方面:吞吐量、能效、延迟和准确性。
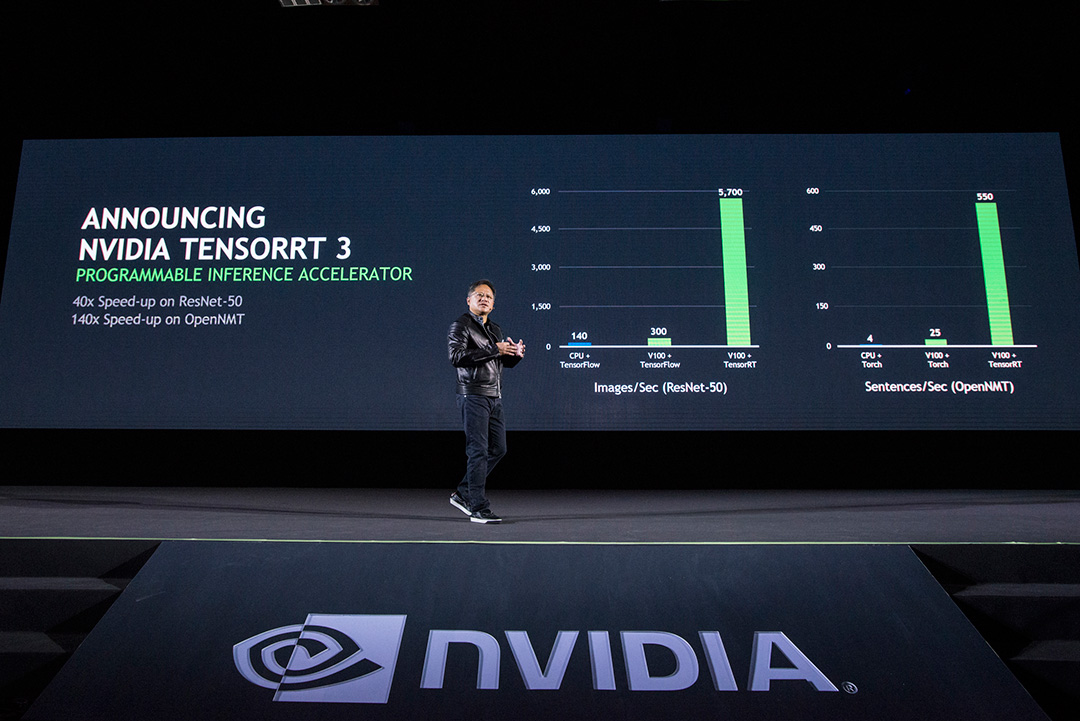
为了更大限度地提高 NVIDIA 深度学习平台的推理性能和效率,我们现在推出了 NVIDIA 的首款可编程推理加速器 – TensorRT 3。此加速器可以压缩和优化经过训练的神经网络,并将其部署为运行时版本,从而提供准确的低延迟推理,而无需在框架方面另行开支。
TensorRT 功能包括:
权重和激活精度校准:通过将模型量化为 INT8,显著改善在 FP32 全精度下训练的模型的推理性能,同时尽可能降低准确度损失
网络层和张量融合:通过将连续节点合并为一个节点来实现单内核执行,从而提高 GPU 利用率并优化内存存储和带宽
内核自动调整:通过为以下目标选择最佳数据层和最佳并行算法来优化执行时间:Jetson、Tesla 或 DrivePX GPU 平台
动态张量内存:通过仅在使用期间为每个张量分配内存来降低内存占用量并改进内存重复使用效率
多流执行:通过使用相同的模型和权重并行处理流来扩展到同时处理多个输入流

在基于语音的用法中,研究人员最近介绍可接受的更高延迟阈值在 200 毫秒左右。OpenNMT 是用于处理翻译(在本例中为英语到德语)的递归神经网络 (RNN)。

专为深度学习打造的平台必须具备三种独特的品质。必须具备为深度学习量身打造的处理器。其软件必须可编程。必须针对平台优化行业框架,且框架由可在世界范围访问和采用的开发人员生态系统提供支持。
NVIDIA 深度学习平台秉承这三种品质设计,是绝无仅有的端到端深度学习平台。从训练到推理。从数据中心到网络边缘,都足见其特质。
单击此处了解有关 NVIDIA 推理平台的更多信息。
单击此处立即开始使用 TensorRT 3。
性能比较基于使用 ImageNet 数据集从由 TensorFlow 训练的网络中提取的 ResNet-50 模型。运行 TensorRT 3 RC 的 NVIDIA Tesla V100 GPU 与 Intel Xeon-D 1587 Broadwell-E CPU 和 Intel DL SDK 的比较。双倍得分包含 Intel 声明的将支持 AVX512 的 Skylake 性能提升 2 倍。