Dell、Fujitsu、GIGABYTE、浪潮、联想、宁畅和 Supermicro 广泛可用的 NVIDIA DGX 系统和由 NVIDIA 提供支持的系统,在最新的 MLPerf 基准测试中斩获佳绩。
根据今天发布的最新 MLPerf 结果,NVIDIA 合作伙伴正在推出 GPU 加速的系统,实现超快的 AI 模型训练速度。
七家公司在行业基准测试中测试了至少十几种商用系统,其中大多数是 NVIDIA 认证系统。Dell、Fujitsu、GIGABYTE、浪潮、联想、宁畅 和 Supermicro 与 NVIDIA 一起展示借助 NVIDIA A100 Tensor Core GPU 实现的行业领先的神经网络训练结果。
在最新一轮的基准测试中,只有 NVIDIA 及其合作伙伴运行了所有的八个工作负载。我们的作品共占所有提交作品的四分之三以上,并且取得了令人惊叹的结果。
与去年的分数相比,性能提升了 3.5 倍。对于需要强大性能的大型作业,我们从创纪录的 4096 块 GPU 中收集资源,比任何其他提交作品都要多。
为何 MLPerf 很重要
MLPerf 是一个行业基准测试组织,成立于 2018 年 5 月。NVIDIA 生态系统第四次参与训练测试,并在此次测试中展示出最强劲的表现。
MLPerf 使用户能够自信地做出明智的购买决策。它得到了阿里巴巴、ARM、百度、Google、Intel 和 NVIDIA 等数十家行业领军企业的支持,因此测试透明而客观。
基准测试基于计算机视觉、自然语言处理、推荐系统、增强学习等当今非常热门的 AI 工作负载和场景。训练基准测试专注于用户最关心的方面,即训练新 AI 模型的时间。
速度 + 灵活性 = 生产力
归根结底,客户基础设施投资回报取决于其生产力。这由运行多种 AI 工作负载时的高速度和灵活性来实现。
这就是用户需要灵活且功能强大的系统的原因,其能够快速将各种 AI 模型投入生产,加快上市速度,并更大限度地提高其宝贵的数据科学团队的生产力。
在最新的 MLPerf 结果中,NVIDIA AI 平台在商用提交类别的所有八个基准测试中以最短时间完成模型训练,从而创下了性能记录。
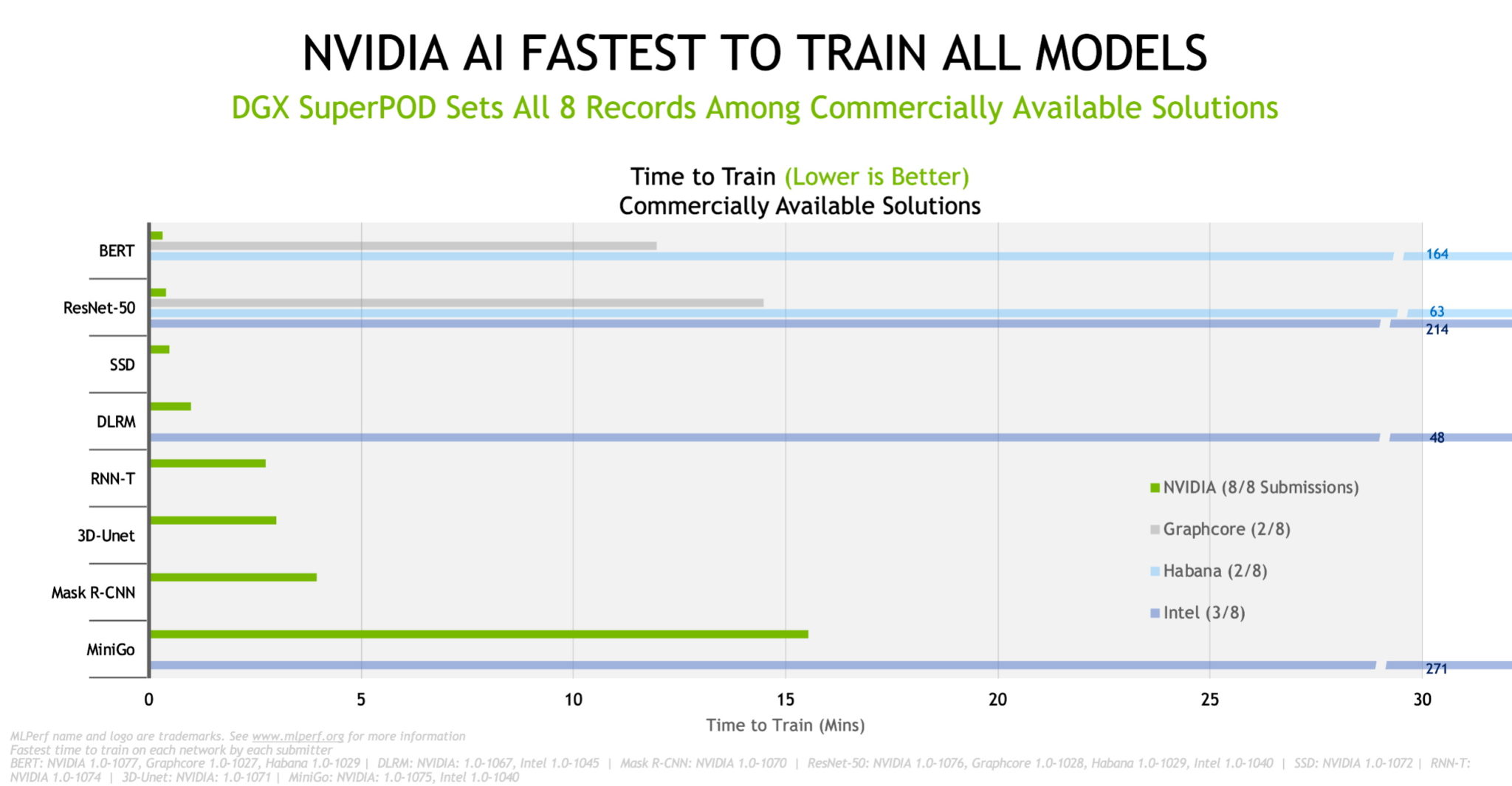
我们对全球速度超快的商用 AI 超级计算机 Selene(根据最新的 TOP500 的排名)运行了大规模测试。该超级计算机基于为榜单中十几个其他系统提供支持的同一 NVIDIA DGX SuperPOD 架构。
扩展到大型集群的能力是 AI 领域的严峻挑战,也是我们的核心优势之一。
在芯片对芯片的比较中,NVIDIA 及其合作伙伴在最新商用系统测试中的所有八个基准测试中都创下了记录。
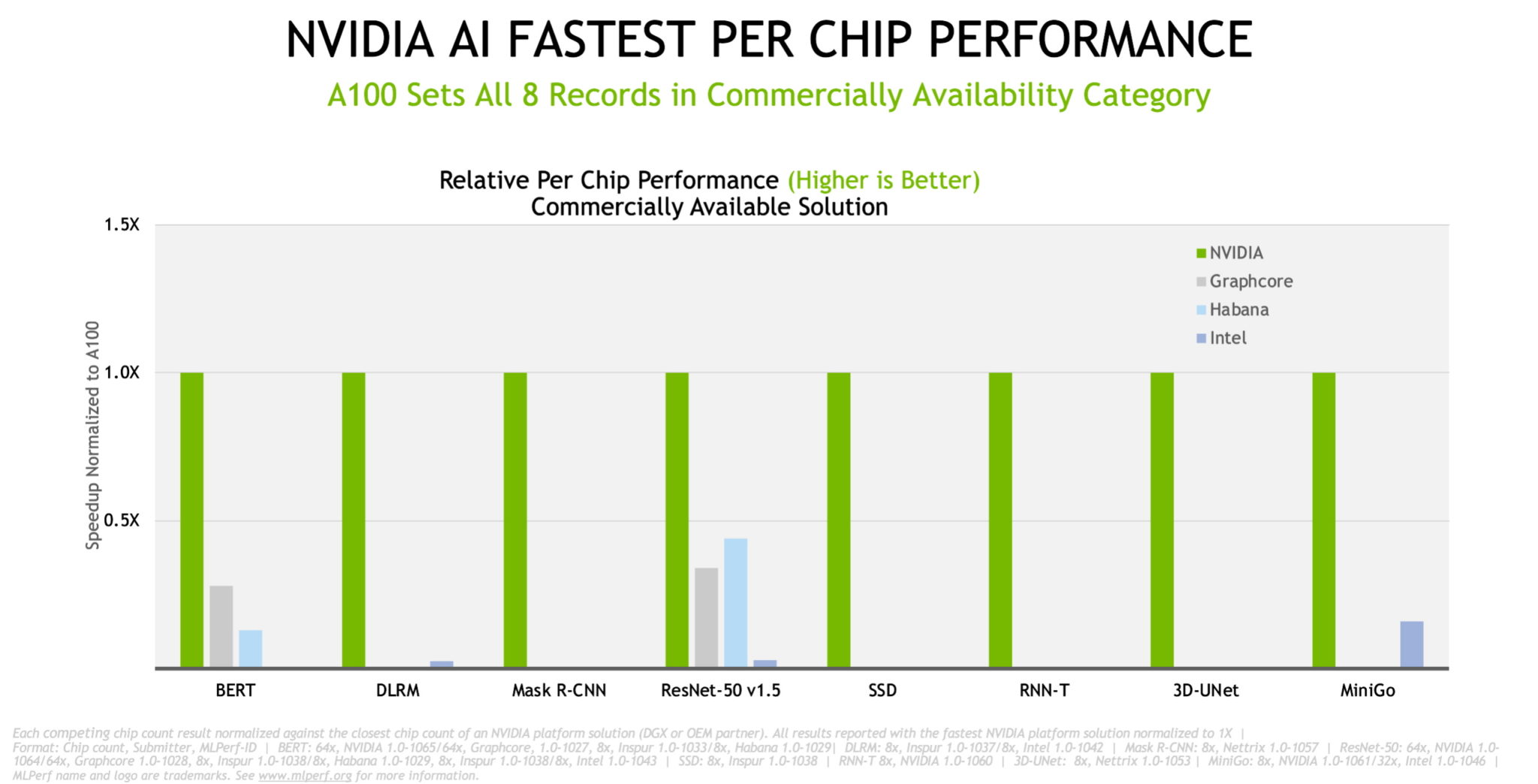
总体而言,以下结果显示,我们的性能在两年半内增长了 6.5 倍,这证明了我们在 GPU、系统和软件的全栈 NVIDIA 平台上的努力。
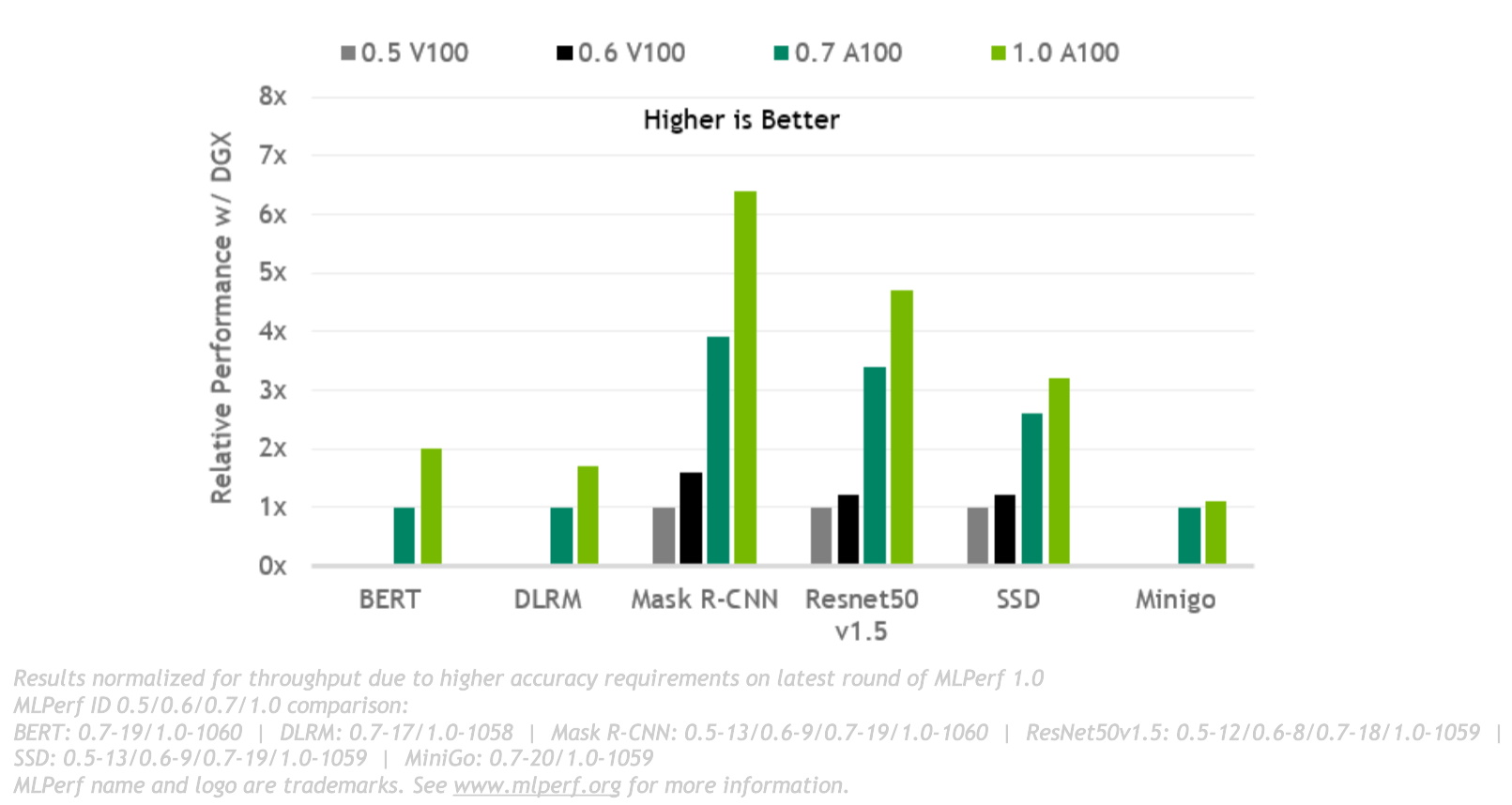
广泛的生态系统提供更好的价值和更优的选择
MLPerf 结果能够在具有许多新型创新系统的基于 NVIDIA 的各种 AI 平台上展示性能。它们涵盖的范围从入门级边缘服务器到可容纳数千个 GPU 的 AI 超级计算机。
近二十家云服务提供商和原始设备制造商使用 NVIDIA A100 GPU 提供在线实例、服务器和 PCIe 卡等相关产品或计划(其中包括近 40 个 NVIDIA 认证系统),参与最新基准测试的七家合作伙伴就在其中。
我们的生态系统为客户提供各种部署模式选择 – 从可按分钟租赁的实例到本地服务器和托管服务 – 提供业内每美元价值更高的服务。
所有 MLPerf 测试的结果显示,随着时间的推移,我们的性能会不断提高。这通过具有已然成熟且不断改进的软件的平台来实现,如此一来,团队可以快速开始使用不断改进的系统。
我们的实现方式
这是我们 A100 GPU 的第二轮 MLPerf 测试。我们在涵盖 GPU、系统、网络和 AI 软件的另一篇文章中详细介绍了各种进展,其中就包括加速。
例如,我们的工程师找到了一种方法,使用 CUDA Graphs(NVIDIA CUDA 操作及其依赖项的软件包)来启动完整的神经网络模型。这使以往测试中的 CPU 问题迎刃而解,在以往的测试中,AI 模型作为一个由许多独立组件组成的链发布,称为内核。
此外,大规模测试还使用了 NVIDIA SHARP 软件,可整合网络交换机内的多个通信作业,减少网络流量和 CPU 等待时间。
CUDA Graphs 和 SHARP 的组合使数据中心的训练作业能够使用创纪录数量的 GPU。这正是自然语言处理等许多领域所需的能力。在这些领域中,其 AI 模型不断壮大,进而包含数十亿个参数,。
其他收益来自最新 A100 GPU 的扩展内存,该扩展将内存带宽增加近 30%,达到 2 TB/s 以上。
客户关注 MLPerf 测试结果
许多 AI 用户发现这些基准测试非常有用。
在纳米技术和气候研究等领域进行研究的瑞典查尔姆斯理工大学的一位发言人说:“MLPerf 基准测试提供了跨多个 AI 平台的透明的同类比较,从而展示在各种实际用例中的实际性能。”
这些基准测试可帮助用户找到符合全球一些大型先进工厂要求的 AI 产品。例如,TSMC 是芯片制造领域的全球领导者,他们利用机器学习来改进光学邻近修正 (OPC) 和蚀刻仿真。
“为充分发挥机器学习在模型训练和推理中的潜力,我们正与 NVIDIA 工程团队合作,将我们的 Maxwell 仿真和反光刻技术引擎移植到 GPU,从而实现显著的加速。MLPerf 基准测试是我们决策中的一个重要因素。”TSMC 的 OPC 部门总监 Danping Peng 说。
医药、制造业的牵引力
对于突破 AI 界限来改善医疗健康的研究人员而言,这些基准测试也非常有用。
“我们与 NVIDIA 密切合作,将 3DUNet 等创新引入医疗健康市场。行业标准的 MLPerf 基准测试可为 IT 组织和开发者提供相关性能数据,以获得适当的解决方案来加速其特定项目和应用程序。”德国癌症研究中心 DKFZ 医疗图像计算部门主管 Klaus Maier-Hein 说。
作为研究和制造领域的世界领导者,三星在实施 AI 时也使用 MLPerf 基准测试来提升产品性能及制造生产力。
“实现这些 AI 进展要求我们拥有更好的计算平台。MLPerf 基准测试可为我们提供开放、直接的评估方法,统一评估平台供应商,从而简化我们的选择流程。”三星电子发言人说。
获取同样的结果和工具
我们用于最新提交作品的所有软件均可从 MLPerf 仓库获得,因此任何人都可以再现我们的基准测试结果。我们不断地将这些代码添加到 NGC(GPU 应用程序软件中心)上的深度学习框架和容器中。
它是全栈 AI 平台的一部分,已在最新的行业基准测试中得到验证,可从各种合作伙伴处获得,能够处理当今真正的 AI 作业。