在最新 MLPerf 基准测试中,NVIDIA H100 和 L4 GPU 将生成式 AI 和所有其他工作负载带到了新的水平,Jetson AGX Orin 则在性能和效率方面都有所提升。
作为独立的第三方基准测试,MLPerf 仍是衡量 AI 性能的权威标准。自 MLPerf 诞生以来,NVIDIA 的 AI 平台在训练和推理这两个方面一直展现出领先优势,包括最新发布的 MLPerf Inference 3.0 基准测试。
NVIDIA 创始人兼首席执行官黄仁勋表示:“三年前我们推出 A100 时,AI 世界由计算机视觉主导。如今,生成式 AI 已经到来。”
“这正是我们打造 Hopper 的原因,其通过 Transformer 引擎专为 GPT 进行了优化。最新的 MLPerf 3.0 凸显了 Hopper 的性能比 A100 高出 4 倍。”
“下一阶段的生成式 AI 需要高能效的新的 AI 基础设施来训练大型语言模型。客户正在大规模采用 Hopper,以构建由数万颗通过 NVIDIA NVLink 和 InfiniBand 连接的 Hopper GPU 组成的 AI 基础设施。”
“业界正努力推动安全、可信的生成式 AI 取得新的进展。而 Hopper 正在推动这项重要的工作。”
最新MLPerf结果 显示,NVIDIA将从云到边缘的AI推理性能和效率带到了一个新的水平。
具体而言,在DGX H100系统中运行的NVIDIA H100 Tensor Core GPU在每项AI推理测试(即在生产中运行神经网络)中均展现出最高的性能。得益于软件优化,该GPU在9月首次亮相时就实现了高达54%的性能提升。
针对医疗领域,H100 GPU 在 3D-UNet(MLPerf 医学影像基准测试)中的性能相比 9 月提高了 31%。
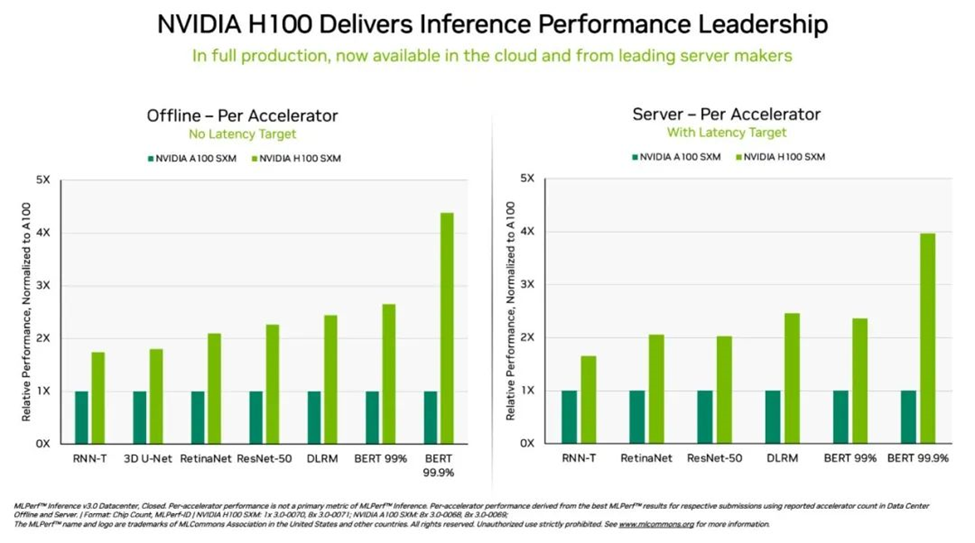
在Transformer引擎的加持下,基于Hopper架构的H100 GPU在BERT上的表现十分优异。BERT是一个基于transformer的大型语言模型,它为如今已经得到广泛应用的生成式AI奠定了基础。
生成式 AI 使用户可以快速创建文本、图像、3D 模型等。从初创公司到云服务提供商,企业都在迅速采用这一能力,以实现新的业务模式和加速现有业务。
数亿人现在正在使用 ChatGPT(同样是一个 transformer 模型)等生成式 AI 工具,以期得到即时响应。
在这个AI的iPhone时刻,推理性能至关重要。深度学习的部署几乎无处不在,这推动了从工厂车间到在线推荐系统等对推理性能的无尽需求。
L4 GPU 精彩亮相
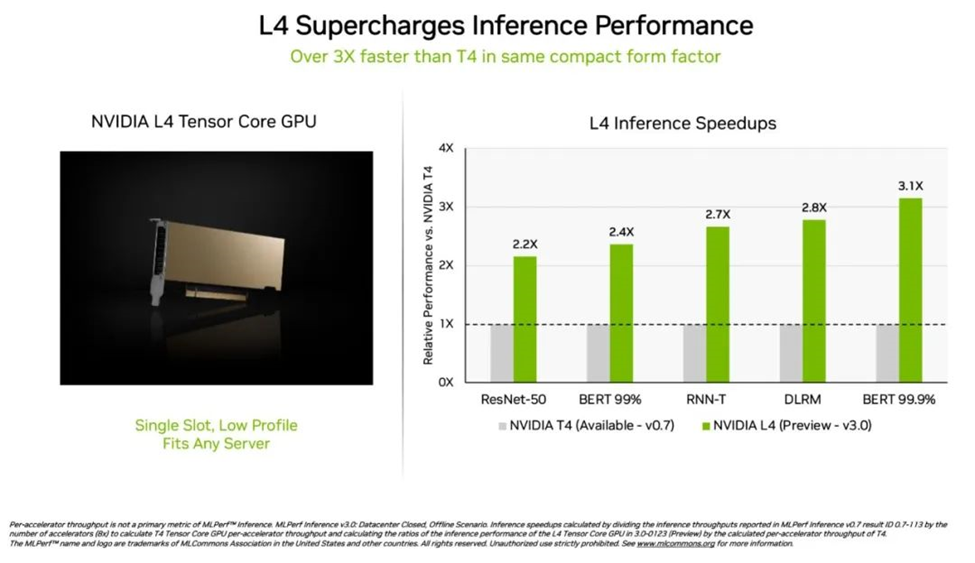
NVIDIA L4 Tensor Core GPU在本次 MLPerf 测试中首次亮相,其速度是上一代 T4 GPU 的 3 倍以上。这些加速器具有扁平的外形,可在几乎所有的服务器中提供高吞吐量和低延迟。
L4 GPU 运行了所有 MLPerf 工作负载。凭借对关键的 FP8 格式的支持,其在对性能要求很高的 BERT 模型上取得了非常惊人的结果。
除了出色的 AI 性能外,L4 GPU 的图像解码速度快了 10 倍,视频处理速度快了 3.2 倍,同时图形和实时渲染性能提高了 4 倍以上。
这些加速器两周前在GTC上发布并已通过各大系统制造商和云服务提供商提供。L4 GPU是NVIDIA在GTC上发布的AI推理平台产品组合中的最新成员。
NVIDIA 的全栈式 AI 平台在一项全新 MLPerf 测试中展现了其领先优势。
被称之为 Network-division 的基准测试将数据传输至一个远程推理服务器。它反映了企业用户将数据存储在企业防火墙后面、在云上运行 AI 作业的热门场景。
在BERT测试中,远程NVIDIA DGX A100系统提供高达96%的最大本地性能,其性能下降的原因之一是因为它们需要等待CPU完成部分任务。在单纯依靠GPU进行处理的ResNet-50计算机视觉测试中,它们达到了100%的性能。
这两个结果在很大程度上要归功于NVIDIA Quantum Infiniband网络、NVIDIA ConnectX SmartNIC以及NVIDIA GPUDirect等软件。
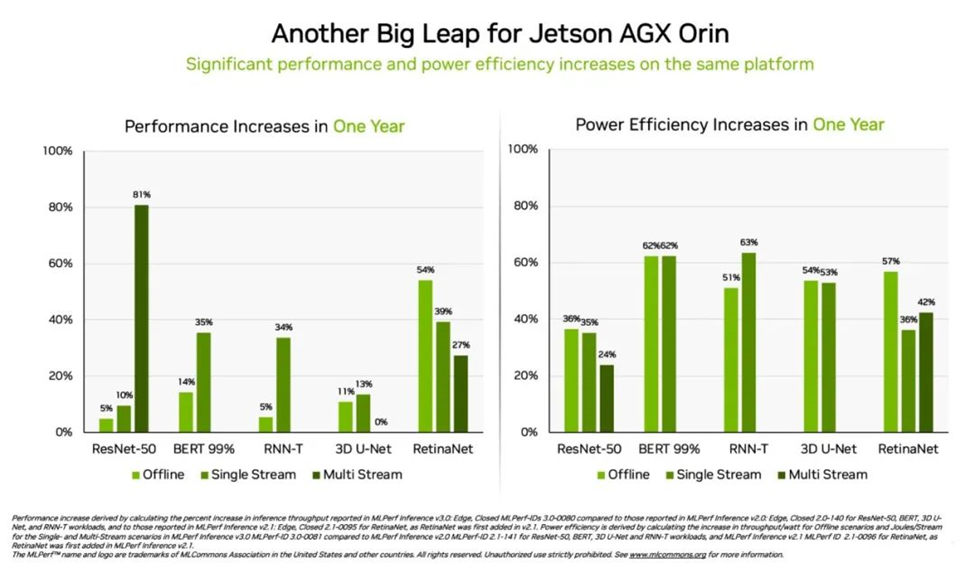
Orin 在边缘的性能提升 3.2 倍
另外,相较于一年前的结果,NVIDIA Jetson AGX Orin 模块化系统的能效提高了 63%,性能提高了 81%。Jetson AGX Orin 可在需要 AI 的狭小空间内以低功率进行推理,包括在由电池供电的系统上。
专为需要更小模块、更低功耗的应用而开发的 Jetson Orin NX 16G 在本次基准测试中首次亮相便大放异彩。其性能是上一代 Jetson Xavier NX 处理器的 3.2 倍。
广泛的 NVIDIA AI 生态
MLPerf 结果显示,NVIDIA AI 得到了业内最广泛的机器学习生态系统的支持。
在这一轮测试中,有十家公司在NVIDIA平台上提交了结果,包括华硕、戴尔科技、技嘉、新华三、联想、宁畅、超微和超聚变等系统制造商和微软Azure云服务。
他们所提交的结果表明,无论是在云端还是在自己的数据中心运行的服务器中,用户都可以通过 NVIDIA AI 获得出色的性能。
NVIDIA 的众多合作伙伴也参与了 MLPerf,因为他们知道这是一个帮助客户评估 AI 平台和厂商的很有价值的工具。最新一轮结果表明,他们今天所提供的性能将随着 NVIDIA 平台的发展而不断提升。
用户需要的是“多面手”
NVIDIA AI 是唯一能够在数据中心和边缘计算中运行所有 MLPerf 推理工作负载和场景的平台。其全面的性能和效率让用户能够成为真正的赢家。
用户在实际应用中通常会采用许多不同类型的神经网络,这些网络往往需要实时提供答案。
例如,一个 AI 应用可能需要先理解用户的语音请求,对图像进行分类、提出建议,然后以人声作为语音来回答用户。每个步骤都需要用到不同类型的 AI 模型。
MLPerf 基准测试涵盖了这些以及其他流行的 AI 工作负载,所以这些测试能够确保 IT 决策者获得可靠且可以灵活部署的性能。
用户可以根据 MLPerf 的结果做出明智的购买决定,因为这些测试是透明的、客观的。该基准测试得到了包括 Arm、百度、Facebook AI、谷歌、哈佛大学、英特尔、微软、斯坦福大学和多伦多大学在内的广泛支持。
可以使用的软件
NVIDIA AI平台的软件层NVIDIA AI Enterprise确保用户能够从他们的基础设施投资中获得最佳的性能以及在企业数据中心运行AI所需的企业级支持、安全性和可靠性。
这些测试所使用的所有软件都可以从MLPerf库中获得,因此任何人都可以获得这些领先的结果。
各项优化措施不断地被整合到NGC(NVIDIA的GPU加速软件目录)上的容器中。本轮测试中提交的每项工作均使用了该目录中的NVIDIA TensorRT优化AI推理性能。