关注 AI 领域评分的人都知道,NVIDIA GPU 于去年 12 月和今年 7 月相继为数据中心的神经网络训练设定了性能标准。今天发布的行业基准测试数据表明,我们在数据中心内外的 AI 网络运行方面也走在前沿。
NVIDIA Turing GPU 和我们的 Xavier 片上系统在 MLPerf Inference 0.5 基准测试中取得领先结果,MLPerf Inference 0.5 是首个针对 AI 推理的独立基准测试。在今天之前,整个行业都迫切希望找到一些关于推理的客观指标,因为推理有望成为人工智能市场中最大、最具竞争力的一个领域。
在 12 家参与测试的公司中,只有 NVIDIA AI 平台提供了由行业基准测试组织 MLPerf(2018 年 5 月成立)制定的全部五项推理测试的结果。这充分证明了我们的 CUDA-X AI 和 TensorRT 软件已十分成熟。这些产品可支持用户更轻松地利用我们从数据中心到边缘的各种用途的 GPU。
MLPerf 定义了五项推理基准测试,涵盖三个已确定的 AI 应用领域 – 图像分类、目标检测和翻译。每项基准测试都包含四个方面。服务器和脱机场景与数据中心用例关系最为密切,而单流和多流场景则旨在满足边缘设备和 SoC 的需求。

NVIDIA 在数据中心场景(脱机和服务器)的全部五项基准测试中均名列前茅,其中 Turing GPU 的每处理器性能在商用产品中排名第一。
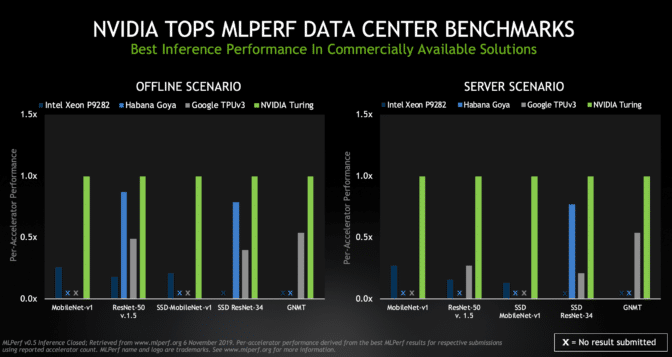
脱机场景代表所有数据都在本地可用的数据中心任务(例如为照片添加标签等)。服务器场景则反映了诸如在线翻译服务之类的作业,其中数据和请求以突发和间歇的方式随机送达。
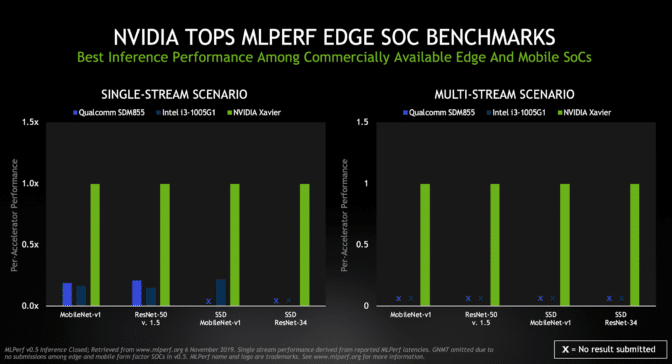
在市售边缘和移动 SoC 中,Xavier 在两种专注于边缘的场景(单流和多流)中表现最佳。
用于识别快速移动的生产线中存在的缺陷的工业检测相机就是一个很好的单流任务示例。多流场景则测试一个芯片可以处理多少个数据源 – 这是可能要使用 6 个或更多摄像头的自动驾驶汽车的一项关键功能。
结果展示了我们的 CUDA 和 TensorRT 软件的强大实力。它们提供了一个通用平台,使我们能够展示多种产品和用例的领先成果,而这是 NVIDIA 独有的功能。
在数据中心场景中,我们让两款 GPU 参与了排名。我们的 TITAN RTX 展现出了 Turing 级 GPU 的全部潜力,在要求苛刻的任务(例如运行用于语言翻译的 GNMT 模型)中更是毫不逊色。
通用且应用广泛的 NVIDIA T4 Tensor Core GPU 在多种场景中均展现了出色的结果。这些功率为 70 瓦的 GPU 旨在轻松地安装到任何具有 PCIe 插槽的服务器中,使用户能够根据需要扩展计算能力,以处理公认具有较强扩缩性的推理作业。
MLPerf 得到了全行业和学术界的广泛支持。其成员包括 Arm、Facebook、Futurewei、通用汽车、谷歌、哈佛大学、英特尔、联发科、微软、NVIDIA 和 Xilinx。值得称赞的是,新的基准测试吸引了比之前两次训练排名更多的参与者。
NVIDIA 采用三种产品及总计四种配置,在 20 个场景中为 19 个场景提交了结果,展现了对这项工作的广泛支持。我们的合作伙伴 Dell EMC 和我们的客户阿里巴巴也提交了使用 NVIDIA GPU 获得的结果。我们携手合作,为用户描绘了比其他任何参与者都要更加广阔的产品组合潜力前景。
新视角,新产品
推理是在实时生产系统中运行 AI 模型以从大量数据中筛选出富有实用价值的见解的过程。这是一种仍在发展中的新兴技术,而 NVIDIA 一直在此领域摸索前进。
今天,我们发布了在 MLPerf 测试中使用的 Xavier SoC 的低功耗版本。全速运行时,Jetson Xavier NX 可提供高达 21 TOPS 的性能,而功耗仅为 15 瓦。它旨在支持要求优越性能、超低功耗的新一代机器人、无人机和其他自主型设备。
除了新硬件之外,NVIDIA 还以 GitHub 上的开源代码形式,发布了 MLPerf 基准测试中使用的全新 TensorRT 6 优化。您可以在此 MLPerf 开发者博客中了解有关优化的更多信息。我们不断发展完善这款软件,让我们的用户可以从不断改进的 AI 自动化和性能中获益。
让大众可以更轻松地利用推理
通过今天的 MLPerf 测试,我们总结出的一个重要结论就是推理十分困难。例如,在实际工作负载中,推理的要求要高于基准测试,因为实际工作中需要大量的预处理和后处理步骤。
NVIDIA 创始人兼首席执行官黄仁勋在去年的 GTC 主题演讲中将错综复杂的推理要求压缩为一个首字母缩写词:PLASTER。他说,现代 AI 推理需要在 Programmability(可编程性)、Latency(延迟)、Accuracy(准确性)、Size-of-model(模型大小)、Throughput(吞吐量)、Energy efficiency(能效)和 Rate of Learning(学习速率)方面表现卓越。
因此,用户在处理要求苛刻的推理作业时,越来越青睐高性能的 NVIDIA GPU 和软件。这些用户包括宝马、Capital One、思科、Expedia、John Deere、微软、PayPal、Pinterest、宝洁、Postmates、Shazam、Snap、Shopify、Twitter、Verizon 和沃尔玛等具有远见卓识的知名公司。
本周,全球规模最大的配送服务公司 – 美国邮政– 成为使用 NVIDIA GPU 进行 AI 训练和推理的组织之一。
硬盘制造商希捷科技公司希望借助在 NVIDIA GPU 上运行的 AI 推理技术,将其生产能力提高 10%。该公司预计,凭借效率和质量的提升,他们将获得高达 300% 的投资回报。
Pinterest 依靠 NVIDIA GPU 来训练和评估其识别模型,并针对其 1,750 亿个 PIN 执行实时推理。
Snap 使用 NVIDIA T4 加速器在 Google 云端平台上执行推理,与纯 CPU 系统相比,可有效提高广告效果,同时降低成本。
Twitter 的发言人指出了这样的趋势:“使用 GPU 不仅可以大大缩短训练时间,而且可以让我们在推理时实时了解直播视频,从而让我们能够理解我们平台上的媒体。”
关于推理的 AI 对话
展望未来,对话式 AI 代表着即将到来的一系列重大机遇和技术挑战 – NVIDIA 在这方面无疑也是领先者。
NVIDIA 已经为对话式 AI 服务提供了优化的参考设计,例如自动语音识别、文本转语音和自然语言理解。我们针对 BERT、GNMT 和 Jasper 等 AI 模型的开源优化助力开发者实现一流的推理性能。
我们的客户和合作伙伴中已经涌现出在对话式 AI 领域开创先河的卓越公司。其中包括 Kensho、微软、Nuance、Optum 等。
值得讨论的话题有很多。MLPerf 小组已经在着手努力改进其当前的 0.5 推理测试。我们将努力继续保持在这些基准测试中的领先地位。
- 数据中心服务器规格以及脱机和服务器场景的 MLPerf v0.5 推理结果于 2019 年 11 月 6 日检索自 www.mlperf.org 的如下条目:Inf-0.5-15、Inf-0.5-16、Inf-0.5-19、Inf-0.5-21、Inf-0.5-22、Inf-0.5-23、Inf-0.5-25、Inf-0.5-26、Inf-0.5-27。通过将总性能的主要指标除以所报告的加速器数量,即可得出各处理器的性能。
- 边缘规格以及单流和多流场景的 MLPerf v0.5 推理结果于 2019 年 11 月 6 日检索自 www.mlperf.org 的如下条目:Inf-0.5-24、Inf-0.5-28、Inf-0.5-29。